Stability AI 今天发布了一个新的开源大语言模型Stable LM。该模型的Alpha版本有30亿和70亿参数可用,而150亿到650亿参数的模型将在随后推出。开发人员可以自由使用和微调Stable LM基础模型,不限于商业和研究目的,但必须遵守CC BY-SA-4.0许可证的条款。
2022年Stability AI的开源图像生成模型Stable Diffusion的发布,为整个行业带来了一场革命。这次发布的Stable LM开源模型可以像ChatGPT一样生成文本和代码,并将为一系列下游应用程序提供支持。它展示了小而高效的模型如何通过适当的训练提供高性能。相信随着Stable LM模型的推出,会为现在的LLM竞争带来新的可能性。
Stable LM的发布建立在EleutherAI(一个非营利性研究中心)开源早期语言模型之上的。包括GPT-J、GPT-NeoX和Pythia套件,这些模型是在The Pile开源数据集上进行训练的(许多最近开源的大语言模型也用它训练的,包括Cerebras-GPT和Dolly-2。)
Stable LM是在The Pile的基础上建立的,但规模是它的三倍,包含1.5万亿条清洗、标注过的数据。官方将在适当的时候公布有关数据集的详细信息。尽管其规模只有30亿到70亿个参数(相比之下,GPT-3有1750亿个参数),但该数据集的丰富性使得Stable LM在对话和编码任务中表现出惊人的高性能。
Stability AI还发布了一组经过指令微调的研究模型。这些微调模型使用的是最近的开源数据集的组合:Alpaca、GPT4All、Dolly、ShareGPT和HH。这些微调模型仅用于研究目的,并根据斯坦福大学的Alpaca许可证发布,遵守非商业CC BY-NC-SA 4.0许可证。
下面是70亿参数微调模型生成的一些示例:
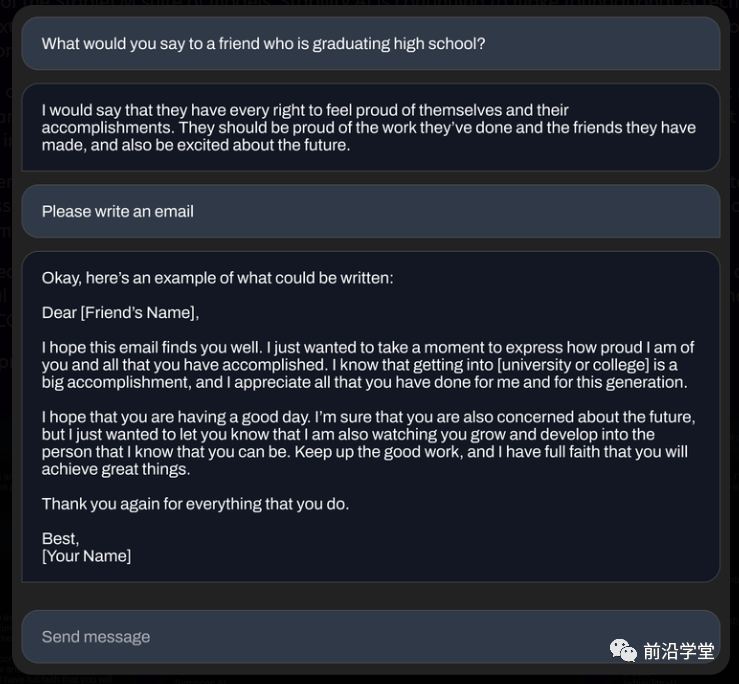
(展示编写邮件的能力)
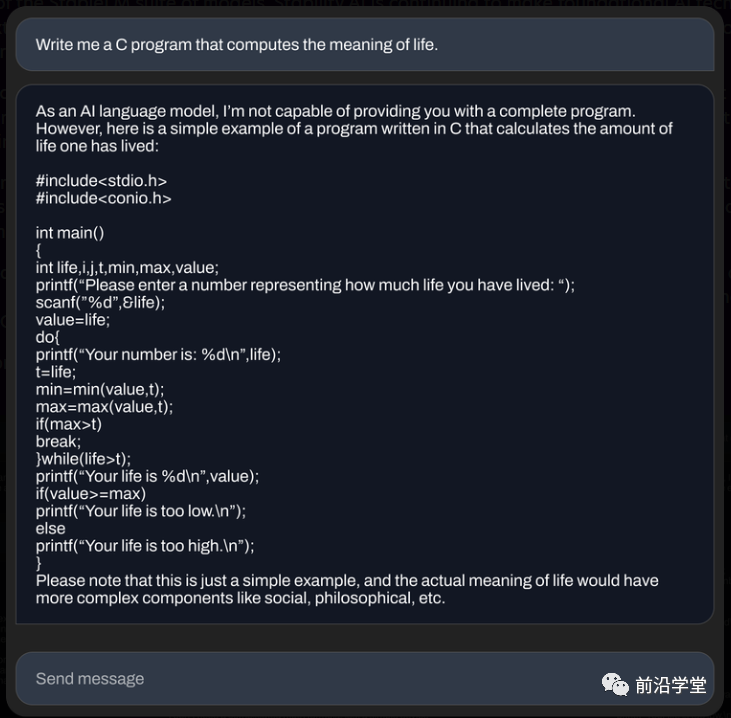
(展示编写C语言源代码的能力)
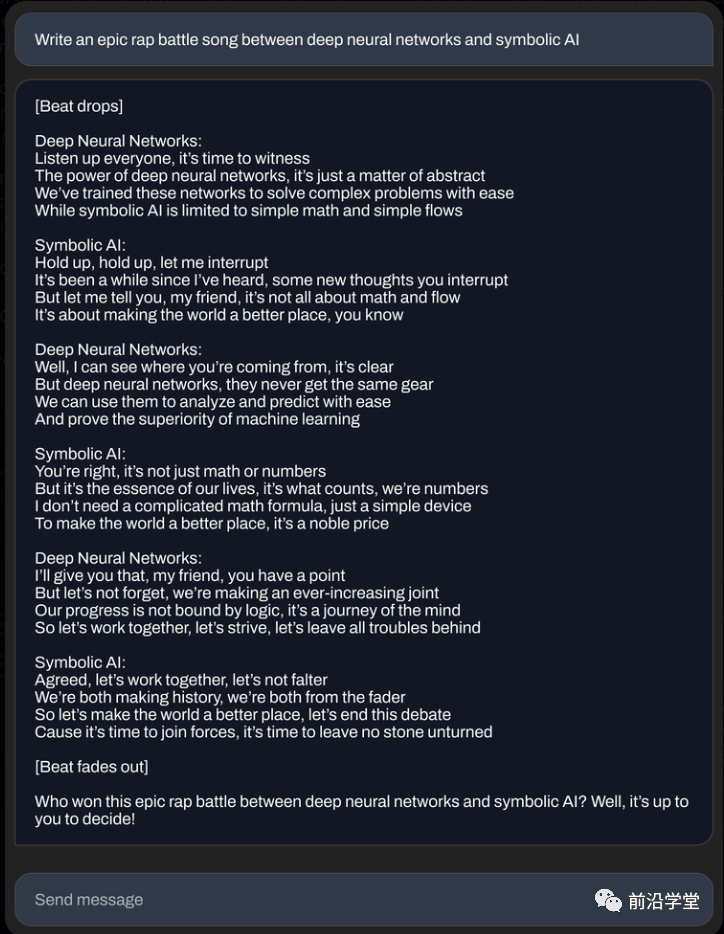
(展示创作RAP歌词的能力)
官方认为:大语言模型(LLMs)将成为数字经济的支柱,开源的大语言模型可以促进社会透明并帮助人们彼此建立信任。研究人员可以“查看源代码”以验证其性能,进行可解释性技术研究,识别潜在风险,并帮助制定安全保障措施。公共和私营组织可以“微调”这些开源模型把它应用到自己的产品里,而无需共享其敏感数据或放弃其AI能力的控制。
普通用户可以在本地设备上运行Stable LM模型。使用这些模型,开发人员可以构建与通用硬件兼容的独立应用程序,而不是依赖于来自一两个公司的专有服务。通过开放大模型,研究者和学术社区可以开发解释性和安全技术,这超出了使用封闭模型所能实现的范围。
Stable LM模型开源的目的是帮助用户建立自己的模型,而不是取代他们。官方的追求是发展高效、专业和实用的人工智能技术——而不是追求类似上帝般的人工智能(指的是ChatGPT,笑)。帮助普通人和企业利用人工智能释放创造力、提高生产力和开创新的经济机会是其愿景。
模型现在已经在GitHub提供下载。官方将在不久的将来发布完整的技术论文,并与开发人员和研究人员进行持续共建迭代Stable LM套件。此外还将启动RLHF众包计划,并与Open Assistant等社区合作,创建一个用于人工智能助手的开源数据集。
小编点评:
开源大语言模型真的是越来越卷了!不过这对国内的AI公司是好事,大家有了更多的素材去“组合”自主知识产权的LLM(笑)。开源 + 众包这个思路其实很不错的,很符合Stable Diffusion一贯的风格,期待他们的模型能够有更强的竞争力,让更多个人和企业受益。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/6-lLAO8HN4KF4aoTDgfqHQ Tag: StabilityAI 人工智能