ChatGPT的出现,让大语言模型成为了万众瞩目的焦点,但语言模型到底是什么?如何用一句话描述语言模型的本质?语言模型是如何一步步进化到今天的?今天我们就来一起找找答案,让我们在应用ChatGPT的同时,知其然也知其所以然。
所谓的语言模型到底是什么?
我们都知道一门语言,其基本组成单元是单词(汉语是单字),这些单词组合起来就形成了句子。穷尽所有的单词组合我们就得到了所有可能的句子,这些句子中很多是毫无意义的,从概率角度看,我们说这些无意义的句子其出现概率为0,也有很多句子在我们日常说话时频繁出现,从概率角度,我们说这种常见的句子其出现概率很高,而其它不同的句子也各有其出现的概率。
如果我们画一张图,横轴是各种可能的句子,纵轴是这个句子出现的概率,那么这张图大概会长这样:
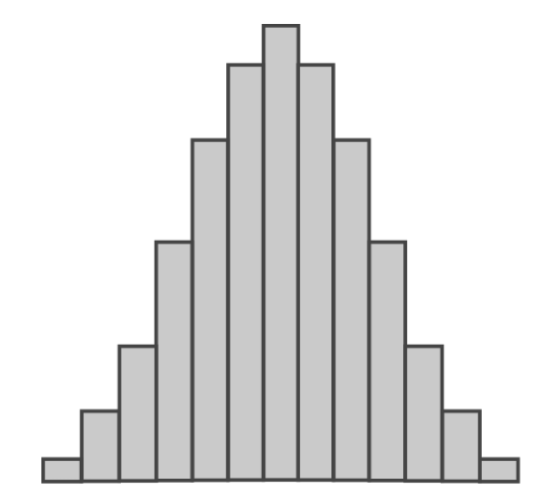
这叫做“概率分布”,如果我们的句子足够多,这个概率分布图就会逐渐变得平滑,成为这样:
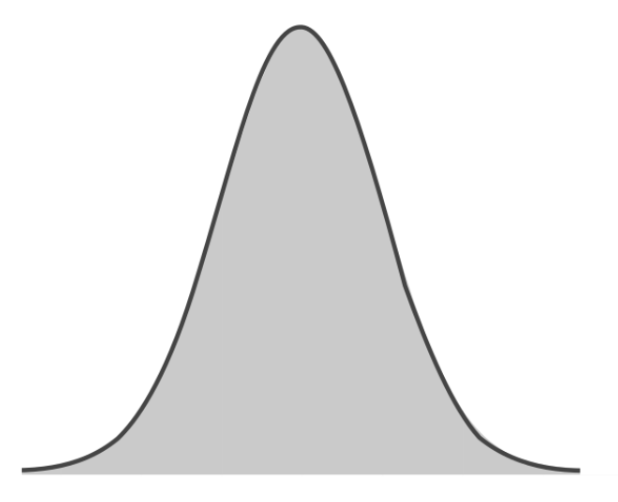
需要注意的是,这个简单的钟形曲线只是一个示意图,对一门真正的语言来说,其概率分布很可能不是这样规则对称的。
而所谓语言模型,无论其技术实现有多复杂,其本质上就是Token序列(句子)的一个概率分布(Token和单词大致对应,但也包含如“es”等表示复数的常见字母组合)。
假设我们有一个语言模型,并用p来表示概率,那么可能会有如下概率值:
p(老鼠爱大米) = 20% (语法正确,符合常识) p(大米爱老鼠) = 1% (语法正确,但不符合常识) p(大老爱米鼠) = 0.001% (胡言乱语)
而ChatGPT的工作就是用这个概率分布不断对下一个单词进行预测的过程。
自回归语言模型
我们知道一句话里面,前面出现的单词会影响后面单词出现的概率,比如在“老鼠爱大米”这句话中,“老鼠”这个词出现后,下一个词为动词的概率就会比较高。
如果我们用p(当前词 | 前面的词)来表示前面的词出现后当前词出现的概率,那么就会有:
p(老鼠爱大米) = p(老鼠) * p(爱 | 老鼠) * p(大米 | 老鼠爱)
对一个长度为L的句子,如果我们用x表示句子中的单词/Token,那么这个句子出现的概率可以写成:
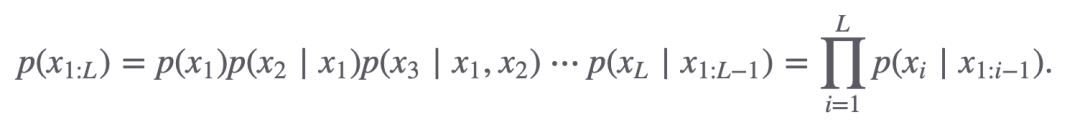
虽然这个数学公式看着比较长,但和上面计算“老鼠爱大米”的过程是一样的。
所谓自回归语言模型(如ChatGPT),其工作过程就是每次生成一个单词,把这个单词拼接到输出中,然后根据已有的输出继续预测下一个单词,这样不断循环直到结束。生成“老鼠爱大米”的过程就类似:
"" -> "老鼠" -> "老鼠爱" -> "老鼠爱大米"
要生成一个长度为L的句子,写成伪代码的话就是:
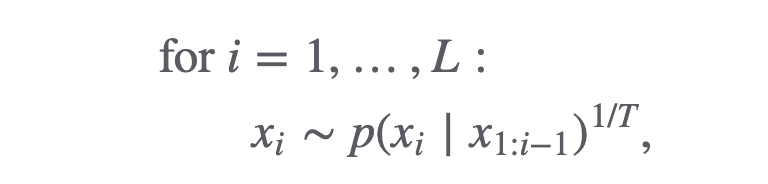
其中的T就是我们调用ChatGPT API时的Temperature参数,它决定了模型输出的随机性:
当T=0的时候,模型选择概率最高的那个单词输出 当T=1的时候,模型严格按照其概率分布选择输出的单词 当T接近于无穷大的时候,模型的概率分布被拉平,所有单词的概率都一样,这时的效果和瞎选一个单词一致
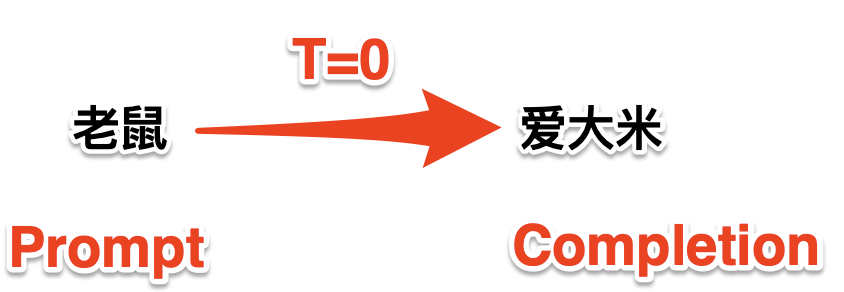
如果我们不是从头开始生成一个句子,而是先给模型一个前缀,然后让模型完成后面的部分,那么这个前缀就是我们常说的"Prompt",而模型生成的部分就是所谓的"Completion":
极简语言模型史
虽然ChatGPT表现惊艳,但其本质和上面介绍的语言模型一致,那么问题来了,为什么ChatGPT直到今天才出现?原因在于虽然语言模型的工作过程比较简单,但要找到那个概率分布却并不容易,下面我们就来看看语言模型的发展简史。
N-gram时代
早期的自然语言处理任务主要是语音识别和机器翻译这两大类,在这些任务中,早期处于主导地位的是N-gram模型。
我们知道所谓语言模型就是Token序列的一个概率分布,在我们前面介绍自回归模型的时候,我们说对一个长度为L的句子,如果我们用x表示句子中的单词/Token,那么这个句子出现的概率可以写成:
可以看到对单词/Token Xi,它依赖它前面出现的所有单词(X1 : i-1),随着句子长度的增加,计算概率分布的复杂度呈指数级上升,而N-gram的思路就是把这个依赖序列变短,让一个单词 Xi只依赖它前面的n-1个单词(Xi-(n-1) : i-1),假设n=3, 对于"the mouse ate the cheese"这句话:
p(cheese | the mouse ate the) = p(cheese | ate the)
也就是说cheese这个词出现概率现在只依赖于它前面的"ate" 和"the"这两个单词。
在N-gram模型中,n的取值一般都不大,这样我们只需要对训练语料进行简单的频率统计就能计算出一个单词的出现概率,比如上面的例子,假设“ate the xxx"这样的词组共出现了10次,其中xxx = cheese的次数为3次,那么我们知道当出现”ate“ ”the“这两个词的时候,下一个词为cheese的概率为30%。
可以看到使用N-gram模型,其概率计算非常简单从而成本也非常低,作为对比,GPT-3的训练使用了三千亿(300Billion)个token,而Google早在2007年就做了一个5-gram的机器翻译模型,这个模型使用了两万亿(2Trillion)个Token,然而,这个5-gram的模型虽然训练数据多了近7倍,但其翻译效果却并不如GPT-3好,为什么?
在N-gram中,如果n比较小,那么预测下一个单词就只能注意到最近的几个词而无法准确把握句子的意思,比如“北京是一座拥有悠久历史的城市,它___”,在n比较小的时候,模型是没有机会了解"它"实际指代的是"北京"。
而当n比较大的时候,在训练语料中出现一模一样句子的概率又变得微乎其微,这导致要么无法通过统计得出概率,要么统计出的概率接近于0无法有效应用。
神经网络时代
在N-gram之后,神经网络和深度学习的兴起把语言模型带向了新的范式,在这一范式下,概率的计算不再是基于明确的统计规则,而是通过大量语料训练一个神经网络模型,然后用这个网络模型来预测概率。
通过神经网络,一个单词的出现出现概率可以通过它前面很多个单词来计算(相当于可以有一个很长的上下文),这有效地克服了N-gram只有局部注意力的问题,但神经网络的缺点是训练成本非常昂贵,在神经网络出现的早期,这个缺点严重限制了其大规模应用,这也导致N-gram在神经网络出现后很多年的时间里,依然是主流的应用模型。
在神经网络的范式下,有两个主要的关键进展,首先是RNN的出现(循环神经网络),RNN可以拥有几乎不受限制的上下文长度,这使其成为如机器翻译、情感分析和文本生成等许多NLP任务的首选模型,RNN的变种LSTM(长短时记忆网络) GRU(门控循环单元),则进一步帮助缓解了长序列中的梯度消失问题,提高了模型的性能和稳定性,但RNN在处理长序列时计算时间较长,无法充分利用GPU等硬件加速的优势,这导致其训练非常困难。
RNN之后的下一个主要进展就是今天的Transformer,它的首次提出是在2017年,相比RNN,Transformer有一个上下文的限制,这个限制在GPT-3是2048个Token,这个大小虽然不算太大,但在很多任务中也足够了,而GPT-4则进一步大幅提高了这一限制。Transformer的一个巨大优势是它可以利用GPU来进行并行训练,这大大加速了其训练速度,同时Transformer通过其注意力机制,在处理长文本时也比RNN更为出色。这些特点也使Transformer架构逐渐成为了几乎所有大语言模型的基础,并最终带来了ChatGPT。
总结一下,所谓语言模型实际就是Token序列的概率分布,而语言模型的进化史,就是这个概率分布计算方法的进化史,在早期N-gram是占据统治地位的主流方法,而神经网络的出现则改变了这一方式,RNN是神经网络范式下的第一个大突破,而Transformer架构则成为了今天所有主流大语言模型的基础。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/xCzpOAsgdAPdcX4zntP8Lw Tag: ChatGPT 人工智能