作者:Demis Hassabis
Google DeepMind CEO,代表 Gemini 团队
去年 12 月,我们发布了 Google 的首款原生多模态模型 Gemini 1.0,包含 Ultra、Pro 和 Nano 三种不同大小。仅仅几个月后,我们又发布了 Gemini 1.5 Pro,这款新模型的性能更强,并且拥有突破性的达 100 万个令牌(Token)的长上下文窗口。
开发者和企业客户已经在以各种令人惊叹的方式开始使用 1.5 Pro,他们发现,1.5 Pro 的长上下文窗口,多模态推理能力,以及出色的整体性能非常实用。
从用户反馈中,我们了解到,有些应用场景需要更低的延迟和更低的部署成本。这激励着我们不断创新,所以今天,我们推出了 Gemini 1.5 Flash:一个相较于 1.5 Pro 更轻量的模型,旨在快速高效地进行规模化服务。
100 万令牌上下文窗口的 1.5 Pro 和 1.5 Flash 目前都已在 Google AI Studio 和 Vertex AI 中发布公开预览版。现在,使用 API 的开发者和 Google Cloud 客户还可以通过候补名单获取 200 万令牌上下文窗口的 1.5 Pro。
我们还将推出开放模型系列的更新,发布我们下一代开放模型 Gemma 2,并通过 Astra 项目与大家分享 AI 助理的未来。
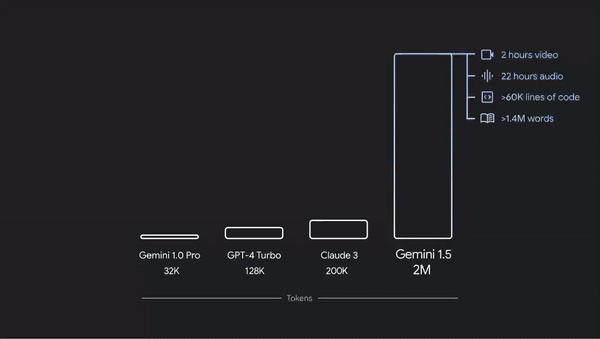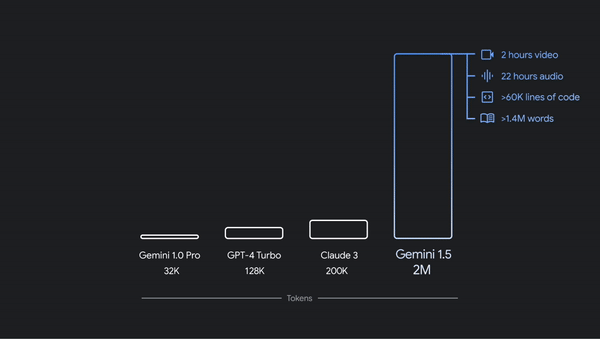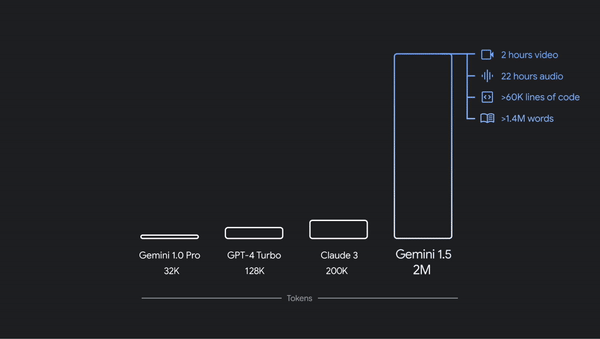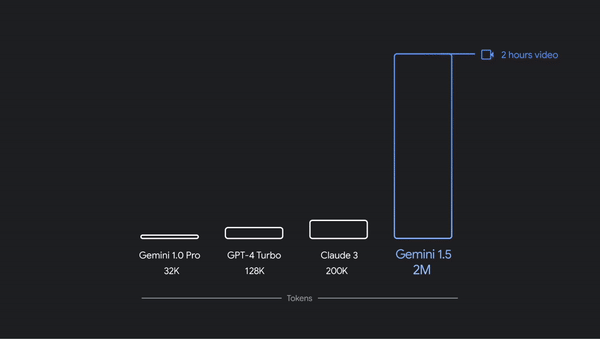
主流基础模型的上下文长度与 Gemini 1.5 的
200 万令牌能力的比较。
Gemini 系列模型的更新
推出的 1.5 Flash,速度更快、效率更高
1.5 Flash 是 Gemini 系列模型中最新成员,它也是通过 API 提供的速度最快的 Gemini 模型。在具备突破性的长文本能力的情况下,它针对大规模地处理高容量、高频次任务进行了优化,部署起来更具性价比。
尽管它比 1.5 Pro 更轻量级,但它在处理大量信息时具有强大的多模态推理能力,就其大小而言达到了令人印象深刻的质量。
新的 Gemini 1.5 Flash 模型在速度和效率方面进行了优化,具有很强的多模态推理能力,并具有突破性的长上下文窗口。
1.5 Flash 在总结摘要、聊天应用、图像和视频字幕生成以及从长文档和表格中提取数据等方面表现出色。这是因为我们利用 1.5 Pro 对该模型进行了被称作“蒸馏”(distillation)的训练,将较大模型中最核心的知识和技能迁移到了更小、更高效的模型中。
1.5 Pro 的重磅更新
在过去几个月中,我们已经大幅改善了 1.5 Pro,这是我们在各种任务中综合表现最佳的模型。
除了将模型的上下文窗口扩展到支持 200 万个令牌之外,我们还通过改进数据和算法,提升了模型的代码生成、逻辑推理与规划、多轮对话以及音频和图像理解能力。我们看到了每个任务的公开基准和内部基准层面有了显著改进。
现在,1.5 Pro 可以遵循越来越复杂和细致的指令,包括指定产品级行为的指令,如角色、格式和风格。针对特定的使用场景,例如,打造聊天智能体的个性和回答风格,或通过多个功能调用来自动化工作流程,我们改进了对模型回应的控制权。同时,我们也已经让用户能够通过设置系统指令来引导模型的行为。
我们还在 Gemini API 和 Google AI Studio 中添加了音频理解功能,现在 1.5 Pro 可以对 Google AI Studio 中上传的视频进行图像和音频推理。现在,我们已经将 1.5 Pro 整合到 Google 产品中,包括 Gemini Advanced 和 Workspace 应用程序。
Gemini Nano 理解多模态输入
Gemini Nano 从仅可处理文本输入扩展到可以处理图像输入。从 Pixel 开始,使用 Gemini Nano 多模态功能的应用将能够像人类一样理解世界——不仅仅通过文本,还可以通过视觉、声音和语言。
下一代开放模型
今天,我们还将分享一系列关于 Gemma 的更新,这是我们用创建 Gemini 模型相同的研究和技术打造的开放模型系列。
我们将推出 Gemma 2,我们为负责任的 AI 创新打造的下一代开放模型。Gemma 2 采用了一种新型架构,实现了突破性的性能和效率,并且将包含新的大小。
Gemma 模型系列也在不断扩展,新推出了受 PaLI-3 启发开发的首款视觉语言模型 PaliGemma。我们还升级了负责任的生成式 AI 工具包(Responsible Generative AI Toolkit),加入了 LLM Comparator 来评估模型输出的质量。
在开发通用 AI 智能体方面的进展
Google DeepMind 的使命是以负责任的方式构建 AI,造福人类。作为这项使命的一部分,我们一直希望开发能在日常生活中提供帮助的通用 AI 智能体。这就是为什么在今天,我们将通过 Astra(高级视觉和对话响应智能体)项目分享我们在构建未来 AI 助理的进展。
要做到真正实用,智能体需要能够像人一样理解周围复杂多变的环境并做出反应——它需要能接收并记忆所见所闻,从而了解上下文信息并采取行动。它还需要具备主动性、“会学习”并能满足个性化需求,这样用户才能自然地与它交谈,不会有滞后或延迟。
虽然我们在开发能够理解多模态信息的 AI 系统方面取得了惊人的进步,但要将回答时间缩短到可对话的程度,仍是一项非常艰巨的工程挑战。在过去几年中,我们一直在努力改进模型的感知、推理和对话方式,让交互的节奏和质量更加自然。