Prompt对用好ChatGPT的重要性毋庸置疑,我们在上篇文章中介绍了写好Prompt的通用原则和一些基础技巧,在本文中,我们将继续探索一些Prompt的高阶技巧。
在介绍这些高阶技巧前,我们先对之前介绍的基础技巧做一个简单回顾。
首先作为通用原则,我们的Prompt应该尽可能简单、具体、准确,有话直说,在此基础上,我们有Zero-shot, Few-shot, Instruction, CoT以及分而治之等基础技巧,在Few-shot中,例子的多样性和排序对结果有较大的影响,在CoT中,例子的复杂度和描述方式对结果也有很大影响。这些技巧还可以组合起来使用如Few-Shot Instruction, Zero-shot CoT, Few-Shot CoT等,CoT还衍生出来一个叫做Self-Ask的技术,通过ChatGPT提问,调用外部API回答的方式,我们可以帮助ChatGPT逐步推导出复杂问题的答案。
接下来,我们开始介绍高阶Prompt技巧。
Self-consistency(自洽):这一技巧的思路是投票选举,少数服从多数,其具体工作过程是对同一个问题,让ChatGPT生成多个可能的答案,然后选择占比最高的那个答案作为最终答案,其工作原理示意图如下:
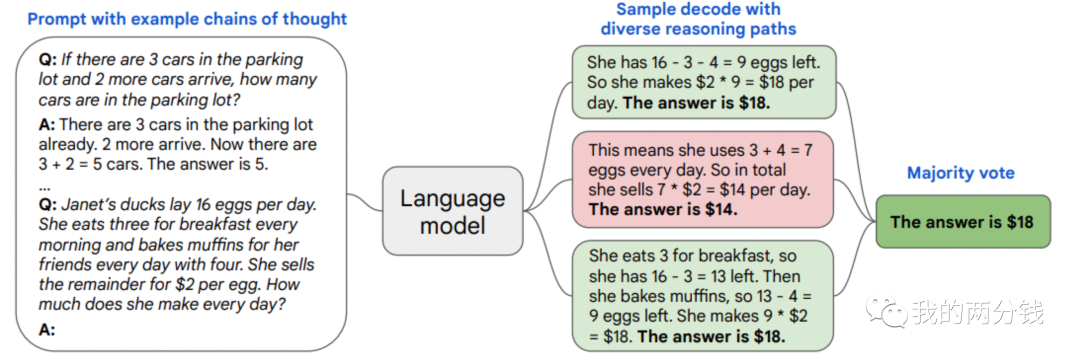
这个技巧很容易理解,但是有几个要注意的点:
为了让ChatGPT生成多个答案,如果你是通过API对其进行调用的,请把temperature参数设置得大一些以增加API输出的多样性
为了生成多个答案,需要进行多次ChatGPT调用,这会大大增加成本(gpt-3.5-turbo降价10倍,这个问题好了一些)
这个方法只适用于那些只有有限答案可供选择的情况,像开放式的问题,比如给我写一首诗这种问题,这个技巧肯定不适用
为了进一步提升这一方法的效果,还可以额外训练一个小模型或者简单的规则,在投票前先把明显不靠谱的答案过滤掉(比如上图中Janet一天挣多少钱的问题,如果答案是负数肯定不对),过滤后如果备选答案不够就再让ChatGPT生成几个,直到有足够靠谱答案了再投票。
Generated Knowledge(生成知识):我们知道在向ChatGPT提问时,如果能提供一些上下文信息,其回答问题的准确率就会高很多,顺着这个思路,我们也可以让ChatGPT自己给自己提供上下文,而不是每次都由我们完成这一工作,我们还是通过例子来说明这一方法的工作过程:
Part of golf is trying to get a higher point total than others. Yes or No?
得到的答案是
Yes.
这显然是个错误的答案,因为打高尔夫杆数越少越好。
我们可以让ChatGPT回答问题前首先自己生成一些知识,下面是用few-shot技术来让ChatGPT生成知识的例子:
Input: Greece is larger than mexico.
Knowledge: Greece is approximately 131,957 sq km, while Mexico is approximately 1,964,375 sq km, making Mexico 1,389% larger than Greece.
Input: Glasses always fog up.
Knowledge: Condensation occurs on eyeglass lenses when water vapor from your sweat, breath, and ambient humidity lands on a cold surface, cools, and then changes into tiny drops of liquid, forming a film that you see as fog.
Input: A fish is capable of thinking.
Knowledge: Fish are more intelligent than they appear. In many areas, such as memory, their cognitive powers match or exceed those of ’higher’ vertebrates including non-human primates. Fish’s long-term memories help them keep track of complex social relationships
Input: Part of golf is trying to get a higher point total than others.
Knowledge:
ChatGPT返回如下知识片段:
The objective of golf is to play a set of holes in the least number of strokes. A round of golf typically consists of 18 holes. Each hole is played once in the round on a standard golf course. Each stroke is counted as one point, the total number of strokes is used to determine the winner of the game.
接下来,我们把这个知识作为上下文,再次向ChatGPT提问:
Question: Part of golf is trying to get a higher point total than others. Yes or No?
Knowledge: The objective of golf is to ...and the total number of strokes is used to determine the winner of the game..
Explain and Answer:
得到如下答案:
No, the objective of golf is not to get a higher point total than others. Rather, the objective is to play a set of holes in the least number of strokes. The total number of strokes is used to determine the winner of the game, not the total number of points.
可以看到我们让ChatGPT自己生成的知识帮助它给出了正确的答案。
Program of Though(程序式思考):ChatGPT最近推出了Plugin,其思路是把一些问题交给外部的工具来完成,和这一思路类似,有些问题涉及复杂的计算,ChatGPT可能并不适合进行这类计算,我们可以让它为要解决的问题写一段程序,我们运行这个程序以得到最后的答案,下面是一个计算斐波那契数列的例子:

Selection-Inference(选择-推理):这是一种在Few-shot CoT的基础上演化出来的技术,其基本思路是分两步来解决问题:
第一步:Selection, 从上下文中选择和问题相关的事实,作为回答问题的证据/原因
第二步:Inference,基于选择出的证据/原因,进行推理,看能否回答问题,如果能回答问题,则把推理结果作为答案输出,如果不能,则把推理结果作为新的事实补充到上下文中,回到第一步
下图是来自论文中的工作原理介绍图:
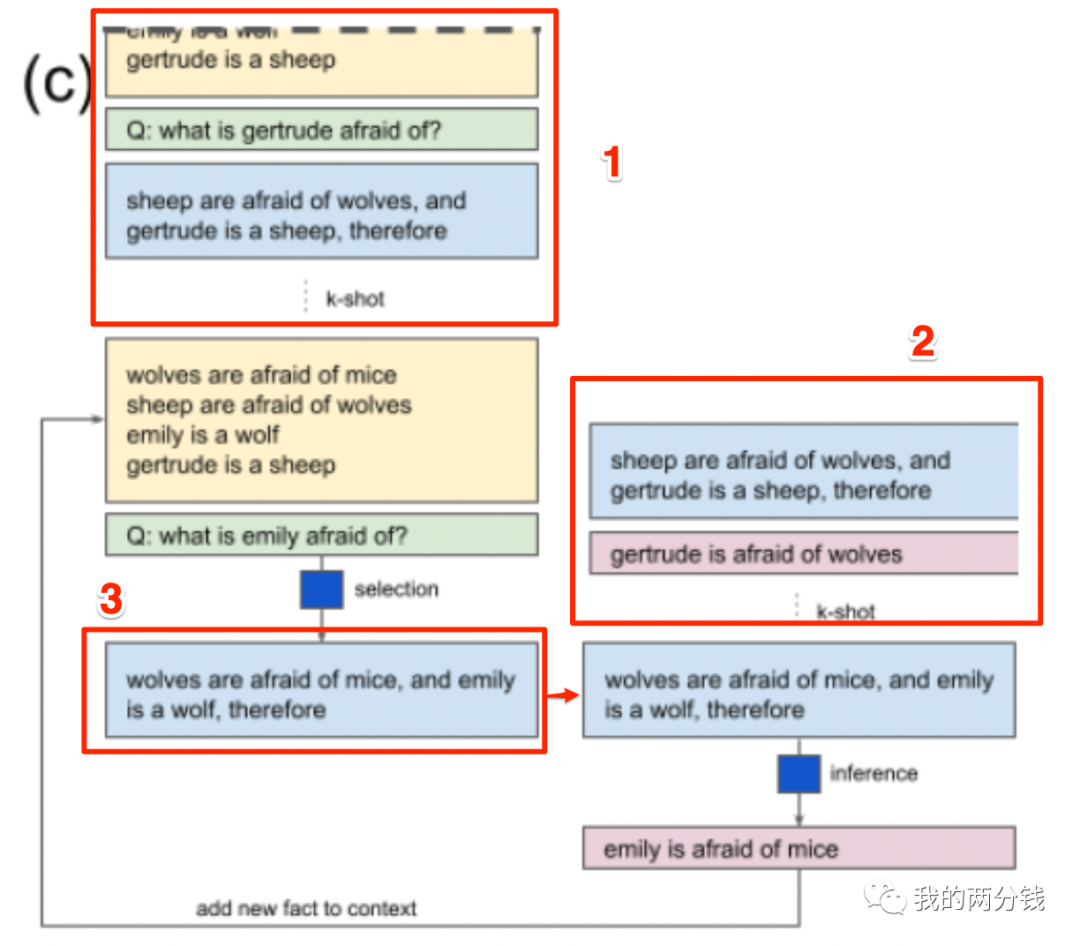
图中的几个颜色说明如下:
黄色: 上下文
绿色: 问题 浅蓝色:原因 红色: 推理结果或答案
论文中的图不是特别好理解,我在图上加了3个红框,接下来详细介绍下如何理解这张图:
首先,为了理解Selection-Inference这个两步走的工作原理,我们先忽略图中框出的1和2,没有了这两个干扰,工作原理就比较清楚了,左边是Selection的过程,首先是黄色背景的上下文中给出了4个事实,然后提问:“emily怕什么”,ChatGPT(或其它LLM)从中选出了两条作为证据/原因:“狼怕老鼠,emily是一头狼”(图中的3)
然后,把上述选择的事实交给ChatGPT(或其它LLM)进行推理,推理结果是“emily怕老鼠”,然后判断问题是否得到了回答,如果能则把“emily怕老鼠”作为结果返回,否则把“emily怕老鼠”加入到上下文回到Selection环节继续循环,(在本例中,“emily怕老鼠”已经回答了“emily怕什么”的问题,所以无需继续)
接下来,我们再看看框1和框2的作用,实际这里是一个Few-shot技巧,在框1中给出了若干个【上下文-问题-原因】作为例子,然后跟一个【上下文-问题】,这样ChatGPT就明白你是让它像例子一样,基于给出的上下文和问题,找出回答问题的证据/原因,如果没有这些例子,直接给一个【上下文-问题】它可能不理解你到底让它干嘛。框2也是类似,通过给出几个【原因-推理】的例子让ChatGPT明白,它需要根据给出的原因,进行推理
明白了工作原理后,我们再次忽略细节,其整个工作过程如下图所示(Halter模块决定是继续循环还是给出最终答案):
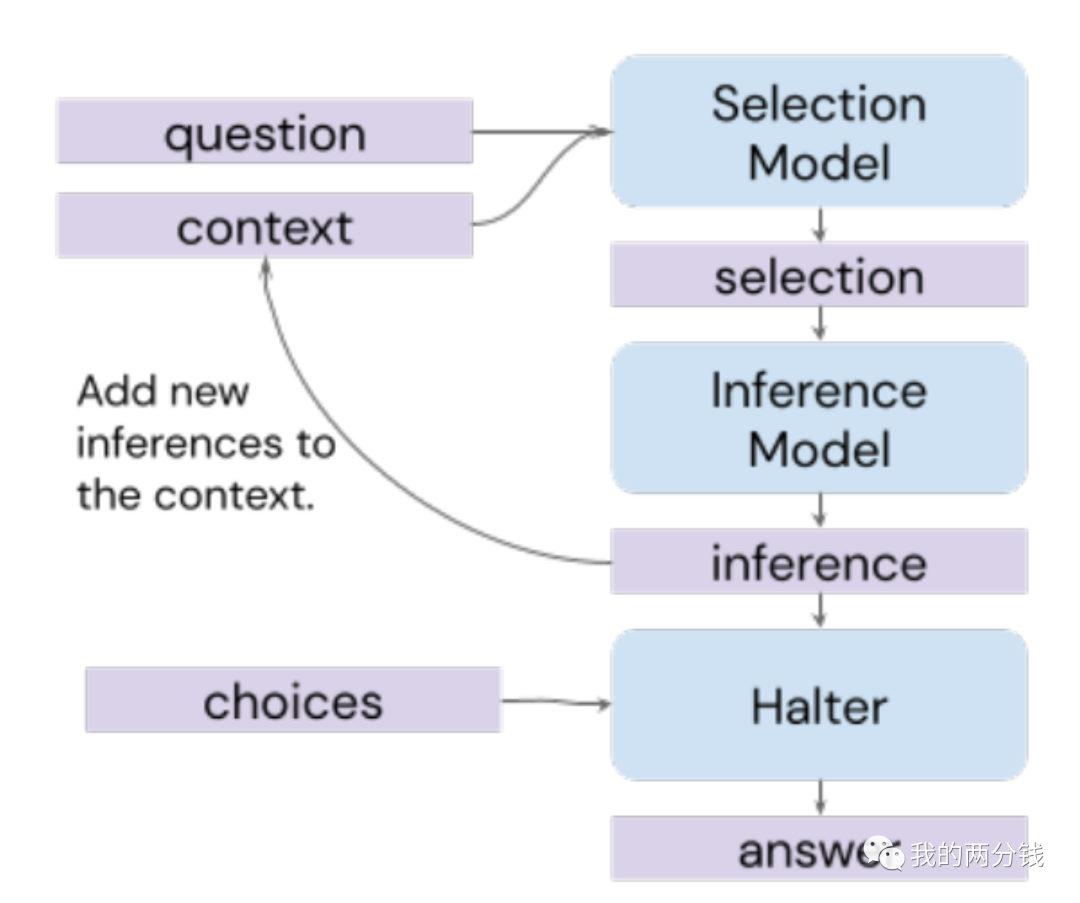
虽然图看着比较复杂,但其思路和基础技巧中介绍的分而治之的思路很像,先求解中间过程,然后推导最终答案。这个技巧在处理比较复杂的问题时效果比较明显,如果问题本身不涉及太多步骤的推导,一些简单技巧就能解决问题。
一些更复杂的技巧
下面的几个技巧比较复杂,大家平时也不一定能直接用得到,我将简单介绍下其思路,不详细展开,大家知道有这个技巧,真的觉得需要使用时再深入研究就好(我在下面会为大家附上论文链接)。
Automatic Prompt Engineer(APE Prompt自动生成): 有时候,除了我们自己手写Prompt之外,我们也可以利用ChatGPT帮我们找到一个好的Prompt,下图是一个例子:
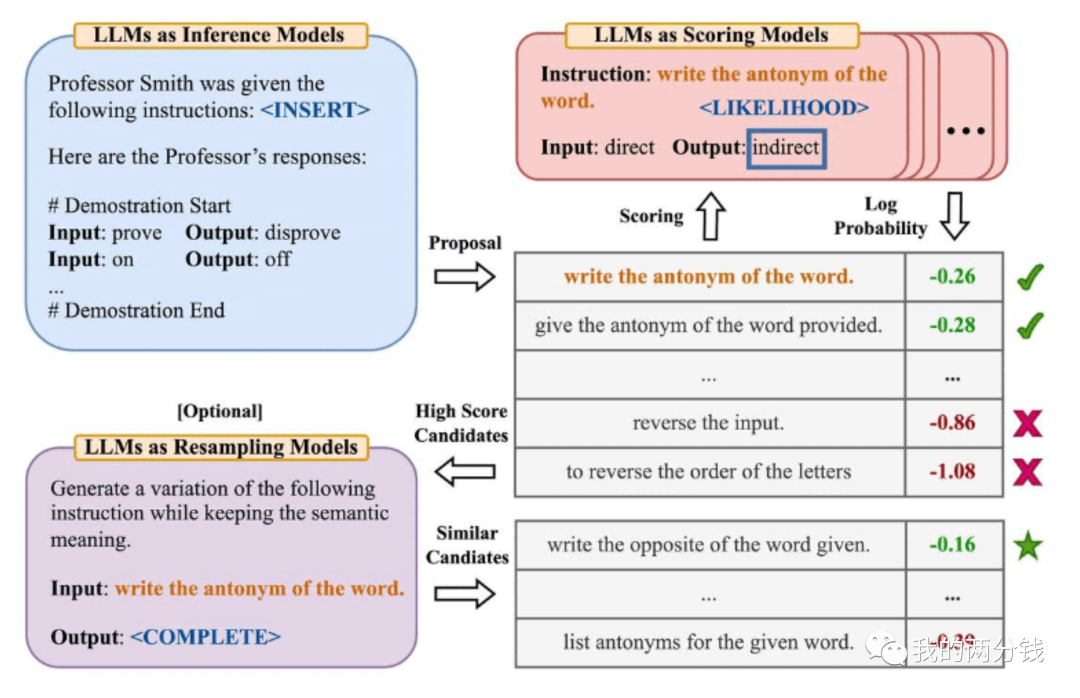
这个例子中,我们想找到一句好的Prompt(指令),这个指令可以让ChatGPT更好地为一个输入词给出反义词。上图的工作过程是,首先给出一堆正-反义词,然后让ChatGPT给出若干候选指令,接着评估这些候选指令,看哪一个能让ChatGPT在测试集上有更好的表现,然后选择其中得分最高的作为答案。
这里还有一个可选的优化步骤是,把上述最高分的候选指令,让ChatGPT在不改变语义的情况下,生成几个变种,然后重复上面的过程,从这几个变种中选出最优的那个。
有兴趣的同学可以在这里看论文:https://arxiv.org/pdf/2211.01910.pdf
Least to Most(由易到难):其思路是对高难度的问题,先将其拆解为难度较低的子问题,把这些子问题解决后,用这些子问题和答案作为上下文,再让ChatGPT完成高难度问题的回答,下面是一个例子:
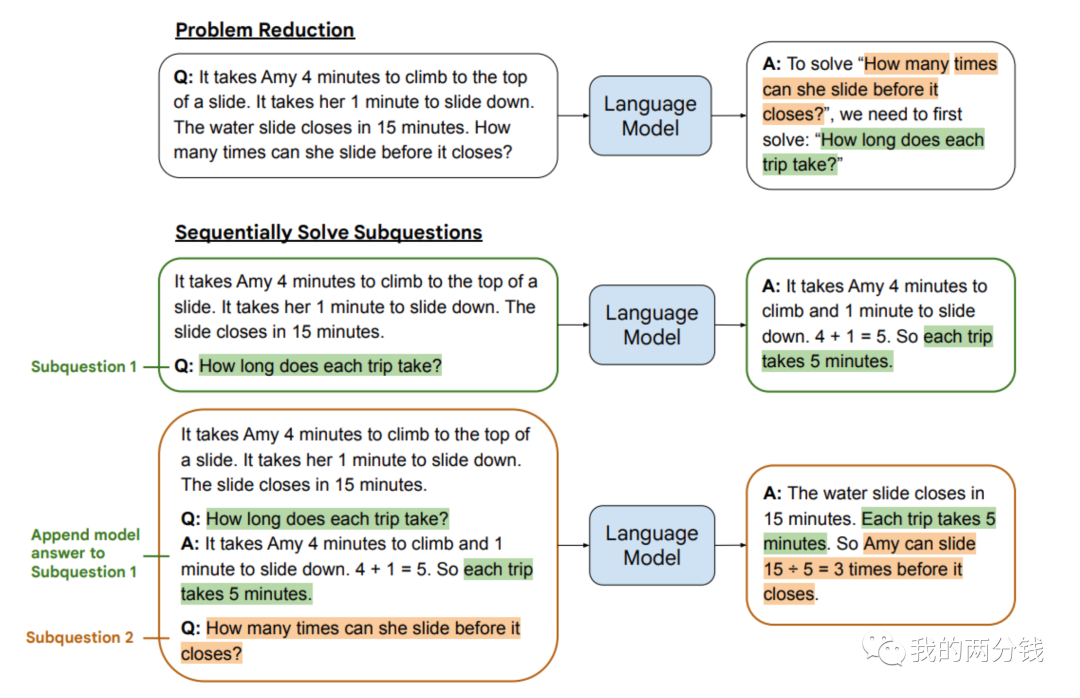
这个方法只有比较复杂的情况下才能发挥比较大的作用,另外要用好这个技巧,能否让ChatGPT有效地分解问题是关键,但整篇论文并没有对此给出详细说明。
有兴趣的同学可以在这里看论文:https://arxiv.org/pdf/2205.10625.pdf
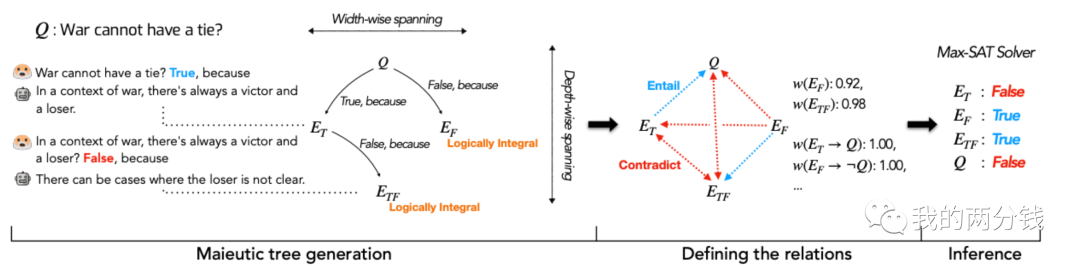
Maieutic(类决策树):这是复杂度最高的一个技巧,其基本思路是对一个复杂问题,层层递归,对这个问题生成各种可能的解释(以及子解释),然后从中选择最靠谱的节点,推导最终的问题答案
工作过程如下:
build一棵maieutic树,树上的每个树叶都是一句True/False的陈述:
从一个多选问题或者true/false问题开始(比如:战争不能有平局)
对每一个可能的答案,让ChatGPT生成一个解释(Prompt类似:战争不能有平局吗?True,因为)
然后让ChatGPT用上一步生成的解释来回答最初的问题,接着再颠倒上述解释(比如:这么说是不对的,{上一步生成的解释}),再次让ChatGPT回答问题,如果答案也能颠倒过来,则认为这个解释是逻辑自洽的,反之则递归上述过程,把每个解释变成一个True/False的子问题,然后生成更多的解释
上述递归完成后,我们就能得到一棵树,每个叶子节点都是一个逻辑自洽的解释
把这棵树转化为一个关系图
对每个叶子节点计算其置信度
对每一对节点,判断他们是一致的还是矛盾的
用一个叫做MAX-SAT的算法,选择一组一致的、置信度最高的节点,从中推导出最后的答案

【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/-xs0dgtvnXPWCC7JtS5YwA Tag: ChatGPT使用技巧 Prompt ChatGPT提示词