为了充分激发大语言模型(如ChatGPT)的潜力,各种Prompt技巧层出不穷,其中最常被使用的一个技巧就是Few-Shot了,通过给出几个例子,ChatGPT等大语言模型就能从例子中迅速学习总结出规律,给出非常好的答案。下图就是一个Few-Shot的例子:
既然Few-Shot的效果如此之好,问题随之而来,不同的人在使用Few-Shot的时候可能会使用不同的例子,不同的格式,这些不同的例子和格式是否对效果有影响?Few-Shot是否也有一些使用技巧?如何才能让Few-Shot的效果最大化?
要回答这些问题,我们需要首先看看Few-Shot的不足之处。
Few-Shot的不足之处
业界有研究(https://arxiv.org/pdf/2102.09690.pdf)发现,使用Few-Shot技巧时,模型对Few-Shot中例子的选择、例子的格式、甚至顺序都非常敏感,不同的选择导致模型的表现有巨大的起伏。
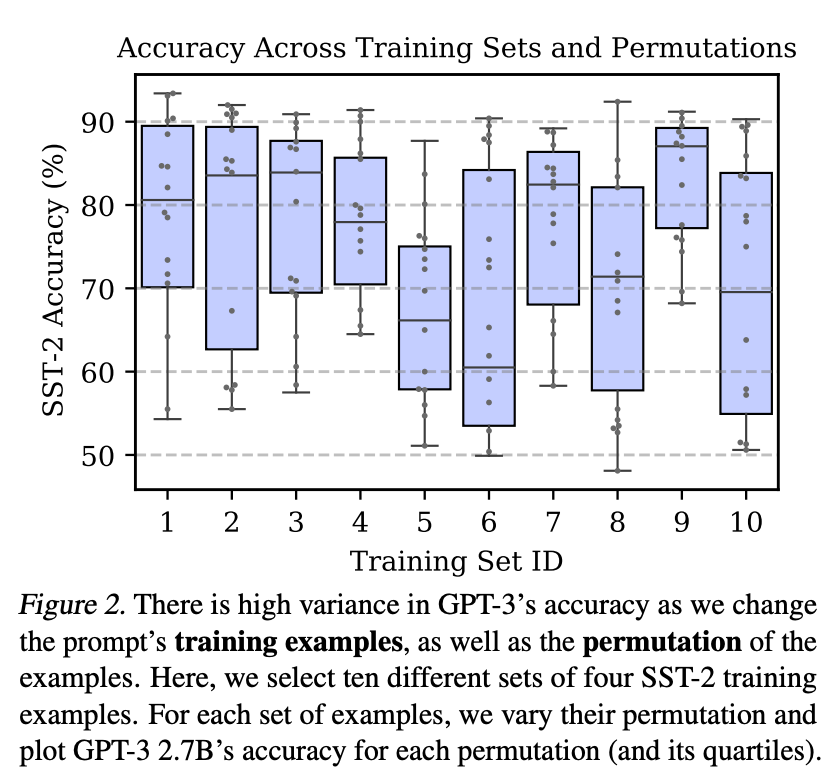
研究人员在SST-2这个测试集上,选择了10组不同的例子,对每一组例子,分别用不同的顺序来对GPT3进行测试,其结果如下图,可以看到模型表现差异巨大,其准确率,最差仅比50%略高,这是一个接近抛硬币的表现,最好情况则可以达到接近90%的准确率。
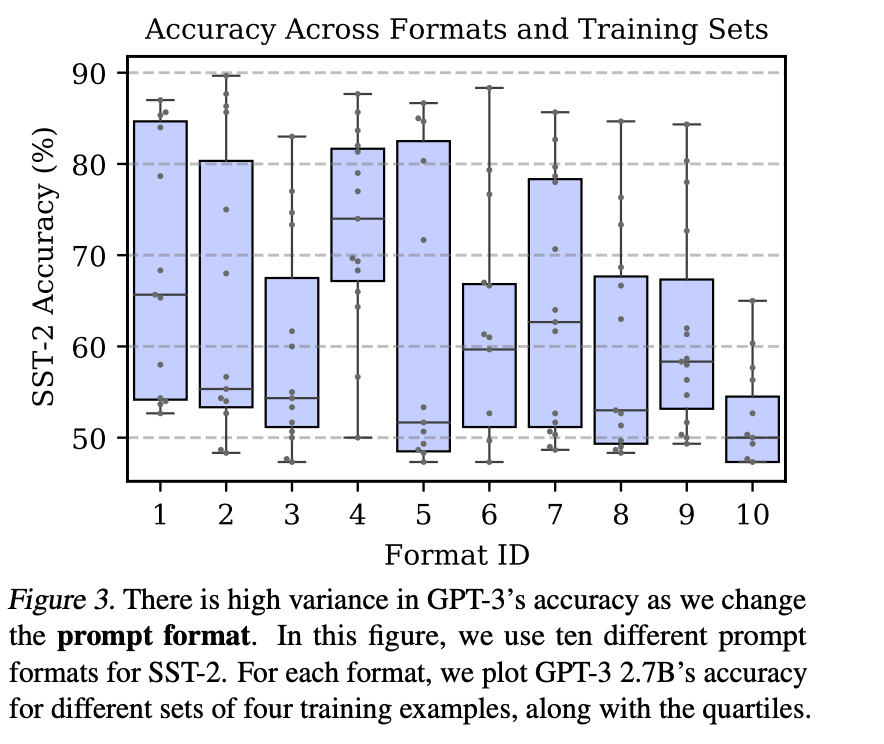
除了对例子的顺序很敏感外,模型对例子的格式也很敏感,研究人员选择了10种不同的格式来给出例子,对每一种格式,分别用4组不同的例子来对GPT3进行测试,可以看到模型的表现依然波动巨大,其准确率在不足50%到80%以上的巨大区间内波动。
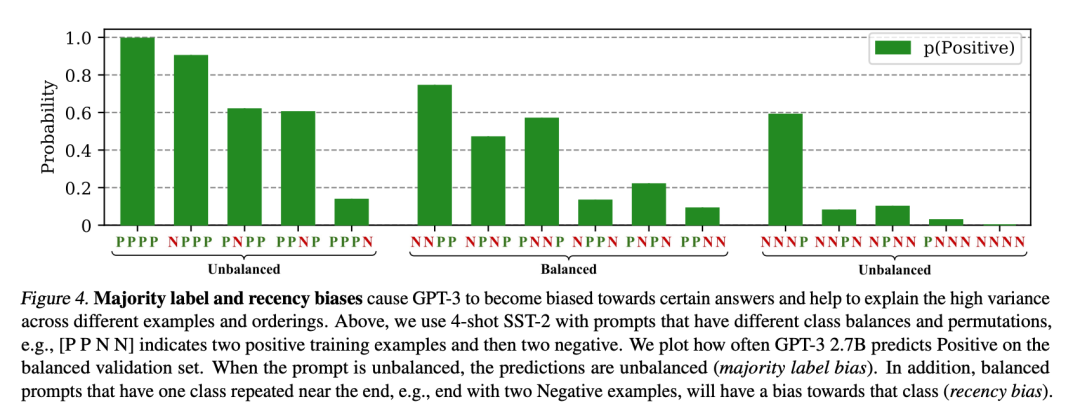
更进一步,研究人员还发现,模型对例子的样本分布,尤其是最后一个例子尤其敏感,研究人员用4个例子的Few-Shot对GPT3进行情感分析任务测试,如下图所示,P和N分别表示正向和负向情感,图中的[PPNN]则表示前两个例子为正向,后两个例子为负向,而纵轴则表示模型在测试中给出正向结果判断的概率,可以看到:
模型的输出和最后一个例子强相关,如果模型的最后一个例子为正向,则模型给出正向判断的概率会比较高,反之则比较低 例子的分布严重影响模型输出,如果正向例子较多,则模型给出正向判断的概率会比较高,反之则比较低
如何解决Few-Shot的不稳定问题

解决不稳定问题最直接的想法是保持例子的多样性、让样本分布保持均匀,同时用一个好的格式来描述例子,然后试着给出尽量多的例子来缓冲最后一个例子对结果的影响。但这么做不但费时费力,而且效果具体如何并不是很有保证。
研究人员给出另一种非常直接的解法,其工作过程很简单,在给定任意格式、例子的分布和顺序的前提下,先给出一个如N/A、[MASK]、空字符串之类的“空问题”,把模型对这个空问题的输出作为偏差,后继用同样的例子、格式、和顺序对模型正常提问,然后把模型的输出减去偏差值,用这个结果作为最后的输出。
这个工作过程类比一下就像我们打靶前对瞄准镜进行校准一样,在保持稳定射击的前提下,如果发现弹道有偏差,我们就把准星向反方向校准一下。上述研究人员给出的解法,实际就是对Few-Shot进行瞄准镜校准的过程。
我们来看看实际对Few-Shot进行校准的结果:
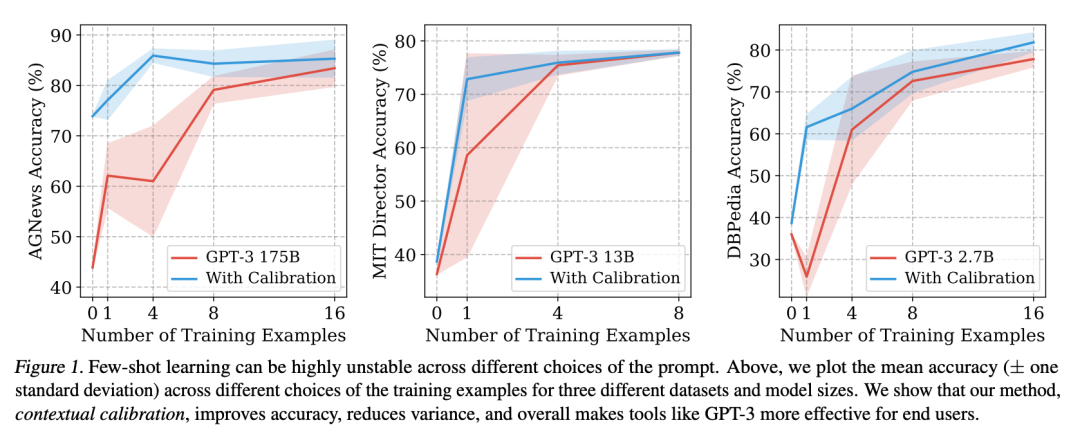
研究人员在分别在GPT3的175B,13B,2.7B这三个不同版本上进行了对比测试,图中的红线是未校准的结果,蓝线是校准后的结果,红线、蓝线周围的阴影是1个标准差的波动范围,可以看到校准后,不但模型的得分显著提高,而且其波动性也显著小于未校准时的波动。
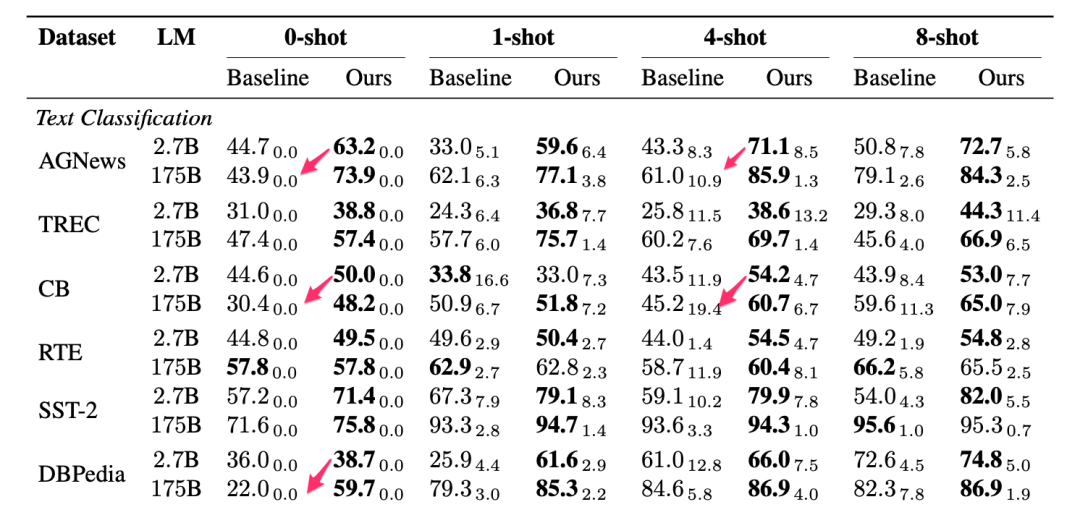
另一个需要特别指出的是,使用这种技术对2.7B参数版本的GPT3进行校准,很多时候,其表现要比175B参数版本的GPT3未校准时的表现还要好,参数少了500倍,而得分却更高。而在同样参数量的情况下,校准后模型的表现则显著高于未校准时的表现:
具体校准过程是如何实现的
如前面的介绍,校准可以简单地理解为从模型的输出结果中减去偏差。下面这段内容涉及一点数学,不感兴趣的同学可以跳过,直接看后面的代码实现。
我们先来看看数学实现,校准公式如下:
q = softmax(Wˆp + b)
其中的p表示模型的原始概率输出,q表示校准后的输出,W是一个权重矩阵,b是一个向量,校准过程就是用权重矩阵W乘以p加上b这个简单运算。
先用一个空问题(如N/A)得到模型的概率输出p_cf,然后W和b有两种计算方法:
把W设置为p_cf的逆矩阵的对角线矩阵,b设置为0向量,这种取值在分类问题上表现较好 把W设置为p_cf的单位矩阵,把b设置为-p_cf,这种取值在文本生成任务中表现比较好
接下来,我们再来看看代码实现,论文的作者在Github开源了复现试验效果的代码 (https://github.com/tonyzhaozh/few-shot-learning),其校准相关的代码实现也很简单:
import numpy as np
...
# calibrate, p_cf is the probabilities output of the Null(N/A) question
num_classes = all_label_probs.shape[1]
if mode == "diagonal_W":
W = np.linalg.inv(np.identity(num_classes) * p_cf)
b = np.zeros([num_classes, 1])
elif mode == "identity_W":
W = np.identity(num_classes)
b = -1 * np.expand_dims(p_cf, axis=-1)
代码中的p_cf就是空问题的概率分布,也就是偏差,num_classes是目标值空间的大小,对分类问题它就是可能的标签个数,对文本生成问题,它就是可能的token数量,当处理分类问题时,mode取值“diagonal_W”效果较好,但处理文本生成问题时,mode取值“identity_W”效果比较好。
要得到p_cf,以GPT3为例,只需要在调用OpenAI API的时候指定logprobs参数就可以了,具体可以参考OpenAI的API文档。
import openai.Completion
response = Completion.create(
engine=model_name,
prompt=prompt,
max_tokens=l,
temperature=temp,
logprobs=num_log_probs,
echo=echo,
stop='\n',
n=n)
总结一下,Few-Shot是激发模型潜力的强大工具,但Few-Shot对例子的格式、顺序、样本分布等比较敏感,这导致模型输出很不稳定,通过手工调整例子的方式很难有效规避这一问题,更好的解法是我们先通过一个空问题得到模型的偏差,之后把模型的输出简单减去这一偏差就可以对Few-Shot进行校准,从而实现Few-Shot性能和稳定性的大幅提升。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/8Bi0LTdLMhrWr8LFxVovfQ Tag: ChatGPT使用技巧 Prompt ChatGPT提示词