要想成长为参天大树,就必须向下深深地扎根,同样的道理,要在AI学习的道路上走得远,就要深入了解其背后的工作原理,今天我们就来研究一下GPT的底层架构,看看其神奇表现是如何一步步实现的。

因为GPT-4没有开源,所以本文主要以GPT-3为基础进行介绍,GPT-4比GPT-3虽然在性能上有很大的提升,但在架构上一脉相承没有巨大变化,都是一个基于Transformer的自回归模型。
虽然这里要介绍的是GPT-3的底层架构,但我始终相信,任何复杂的事物背后一定有一个简单清晰的想法,下面的介绍也将避开晦涩的数学推导,我们将通过看图说话的方式,一步步走完整个GPT-3的工作过程。
GPT架构全景图
GPT是Generative Pre-trained Transformer的首字母缩写,从名字就可以看到,GPT是基于Transformer架构的,这一架构由Google在2017年的论文《Attention Is All You Need》中首次提出,其架构图如下:
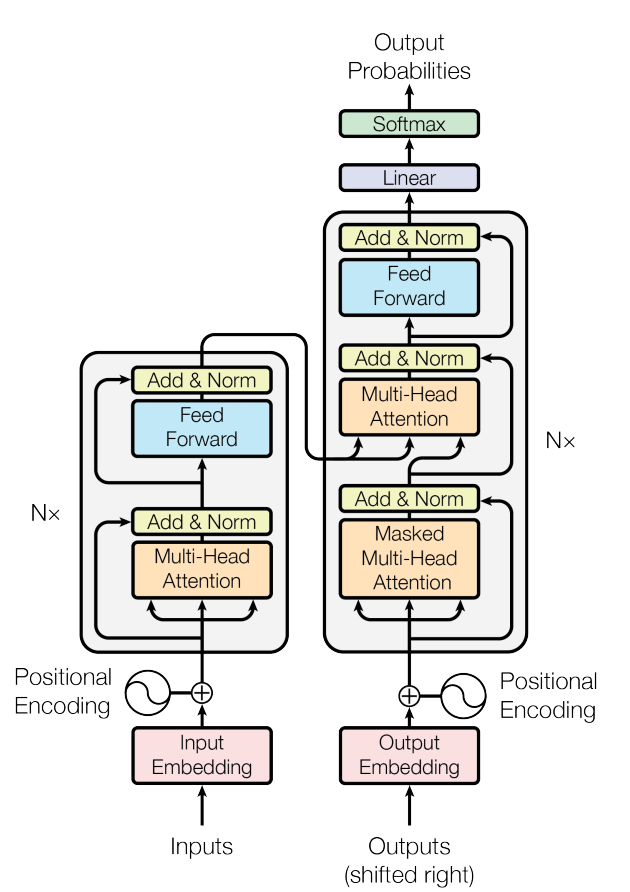
图中有很多细节导致看起来比较复杂,实际上其主要是由左边的N个Encoder和右边的N个Decoder连接而成,可以简单理解为:
左边的N个编码器(Encoder),通过注意力机制获取输入文字的特征(如语法、语义、情感等) 右边的N个解码器(Decoder)也以类似的方式工作,用注意力机制获取当前上下文(已经输出的文字)的特征 以第2步得到的上下文特征为基础,参考第1步得到的输入文字的特征,预测出下一个要输出单词 把新输出的单词拼接到上下文,回到第2步继续循环,直到完成所有输出
上述4步是一个极简介绍,虽然不够精确,但可以忽略细节对Transformer先有一个大致的理解,下文会逐步进行详细介绍。
在上述Encoder-Decoder的基础上,OpenAI在论文《Improving Language Understanding by Generative Pre-Training》中进行了进一步简化,通过自注意力机制,采用了只使用Decoder的架构,这成为了GPT系列的架构基础:
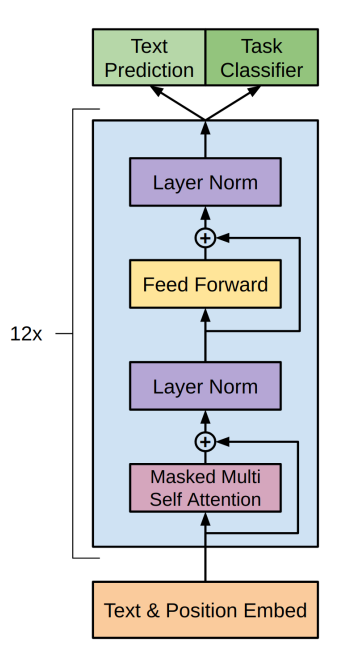
下面我们就来对这一架构分模块进行详细介绍。
GPT的输入输出是什么
像剥洋葱一下,在深入GPT架构前,我们先来看看其输入和输出是什么,我们用一张图来说明:
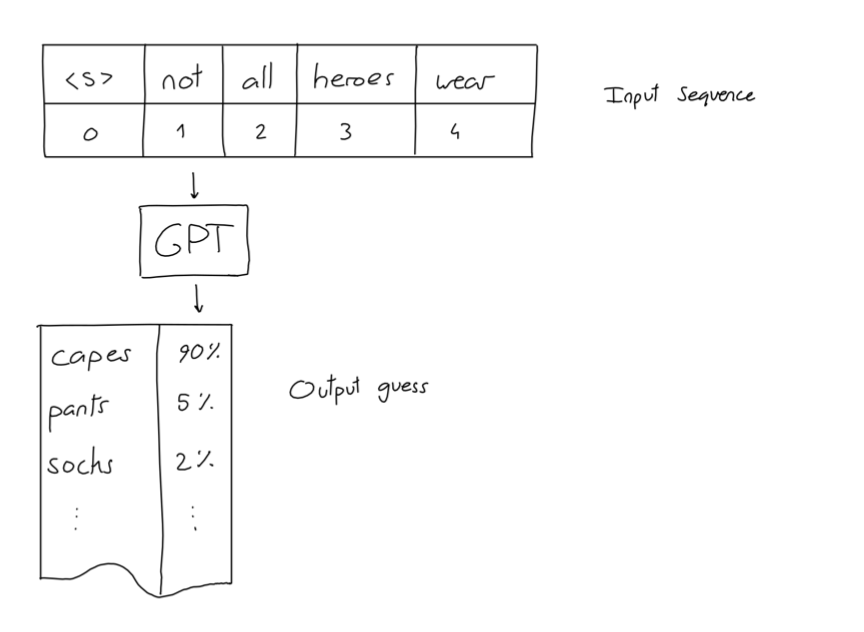
可以看到,我们输入的是一个句子"not all heroes wear",然后GPT给出了若干个可能的下一个词,以及其相应的概率,如果我们选择概率最高的那个词的话(贪心算法),那么"capes"就是句子的下一个词。
Not all heroes wear -> capes Not all heroes wear capes -> but
Not all heroes wear capes but -> all
Not all heroes wear capes but all -> villans
Not all heroes wear capes but all villans -> do
这种不断把新输出拼接到原来输出、并不断循环的工作方式,就是“自回归”这一名词的来由。
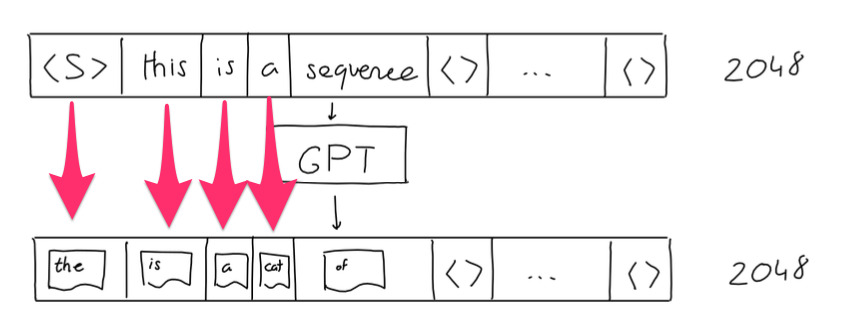
上图只是一个简单的示意图,实际在GPT-3中,输入序列固定为2048个单词(这也就是GPT系列上下文大小限制的来由),如果输入长度不足2048,则用空值填充。
GPT-3的输出实际也是一个长度为2048的序列,其中的每个位置上的单词都是其前面句子对应的输出预测,如下图所示,当句子为空时,输出预测为"the", 句子为"this"时,输出预测为"is", 句子为"this is"时,输出预测为"a"...,在文本生成任务中,我们一般取最后位置上的预测单词就好。
GPT的输入是如何编码的
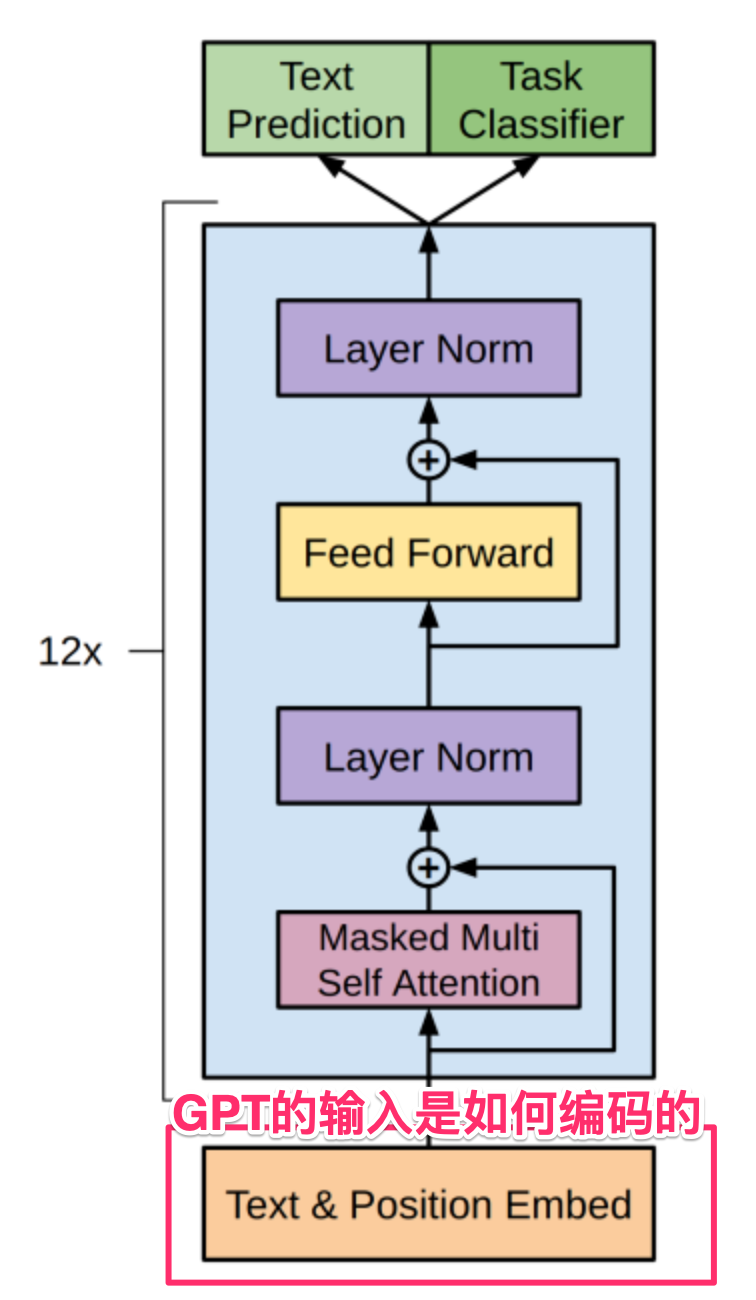
在GPT的工作过程中,它并不直接使用输入的单词,我们首先需要把输入的单词编码成向量表示。
GPT-3有一个大小为50257单词词表,每个单词都在这个词表中有自己的位置,所以一个单词的One-Hot的向量表示(向量中只有1个1,其它都是0)就是类似下面这样 :

对输入的一个句子,我们就可以得到类似下面这样的一个矩阵:
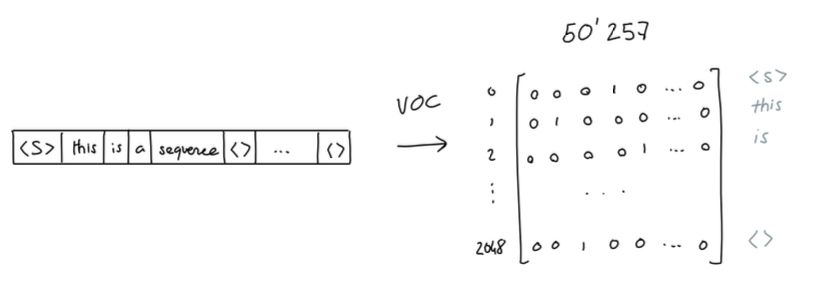
理解了GPT-3的词表和相应的One-Hot编码后,有一个需要说明的细节,GPT-3的词表和我们日常的单词并不是严格一一对应的,它实际是按照字母组合的出现频率来对句子进行拆分的,比如"Not all heroes wear capes"实际会被拆分为"Not" "all" "heroes" "wear" "cap" "es"这6个Token,前5个和我们的单词对应,而最后的"es"则没有对应的单词。
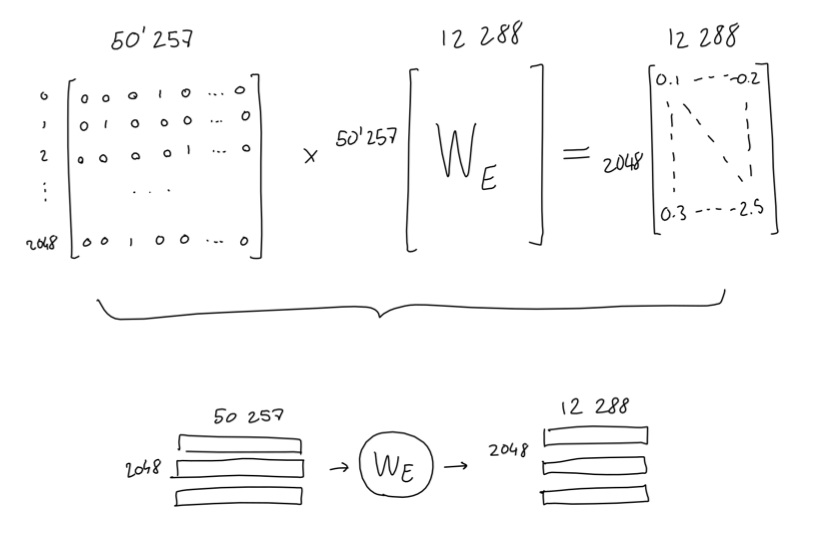
可以看到上面那个2048 * 50257的矩阵极度稀疏,不但浪费空间也没有对输入句子的特征进行充分表达,为了解决这一问题,我们用一个权重矩阵将其投射到一个意义空间,这个空间的每个维度都可以看作代表了某个实际意义(如语法、语义、情感、空间、时间等),在这个空间中,意义相近的单词其位置也比较接近。假设这个空间只有2维,这个过程类似下图:
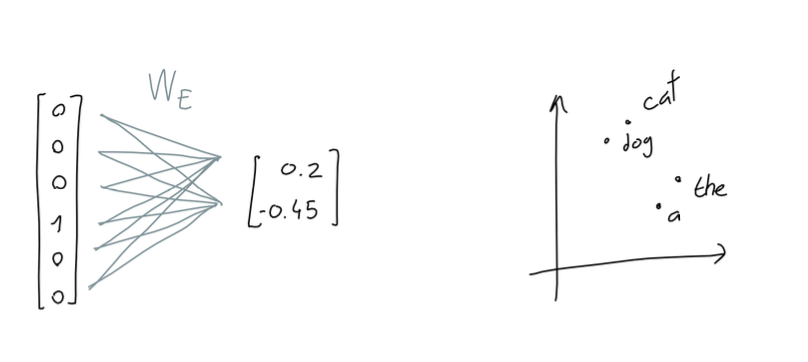
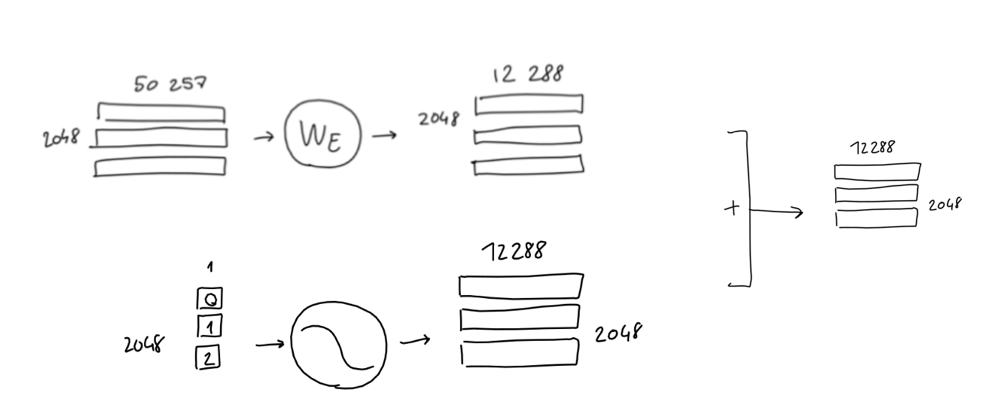
这个投射过程就是我们常说的Embedding,当然GPT-3的Embedding维度远大于2,实际上其维度是12288维,其投射过程如下图:
监狱中的罪犯大多是男性 男性大多是监狱中的罪犯
虽然这两个句子使用的单词完全一样,但第二个句子显然是错误的,所以我们给GPT的输入,还需要对单词的位置也进行编码。
给定单词的下标 i (在0~2047中取值,因为输入长度固定为2048),GPT-3通过12288个不同频率的sin函数将其转换为一个长度为12288的向量:
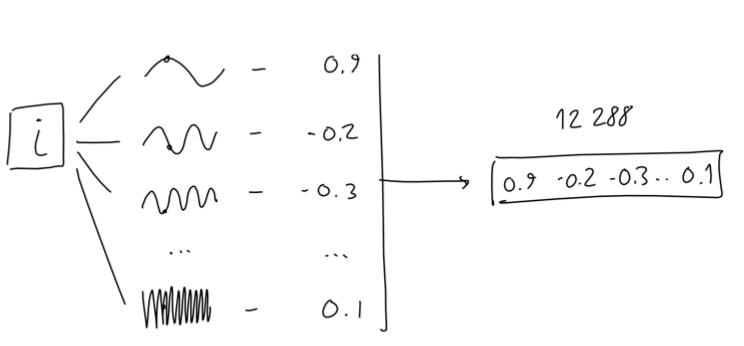
这非常像一个傅立叶变换(几乎任何形状都可以用若干个波函数叠加得到),我没有看到为什么采用这种方式来对位置进行编码,论文作者解释这种方式可以更好地表达单词在高维空间中的相对位置。
对一个完整输入的位置编码,其工作过程类似下图:
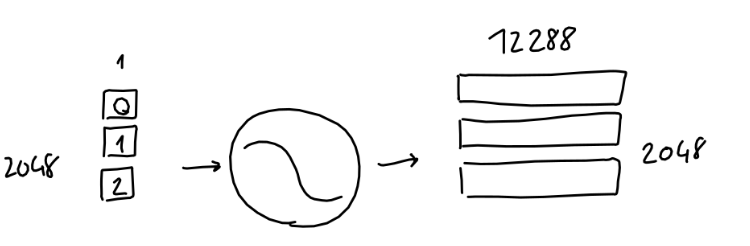
最后,把输入的单词编码和位置编码相加,就完成了输入的编码工作:
注意力机制是如何工作的
在完成了输入的编码后,接下来就是通过注意力机制来获取输入信息中的语言特征了,注意力机制是今天所有大语言模型核心的核心,在详细介绍GPT-3是如何使用注意力机制前,我们需要先理解注意力机制的详细工作过程。
我们以一个输入只有两个单词的句子"Thinking Machines"为例,如下图所示,其输入Embedding首先会被投射成Query, Key, Value 3个矩阵(Wq, Wk, Wv是做投射时对应的权重矩阵,它们是在模型的训练过程中学习得到的):
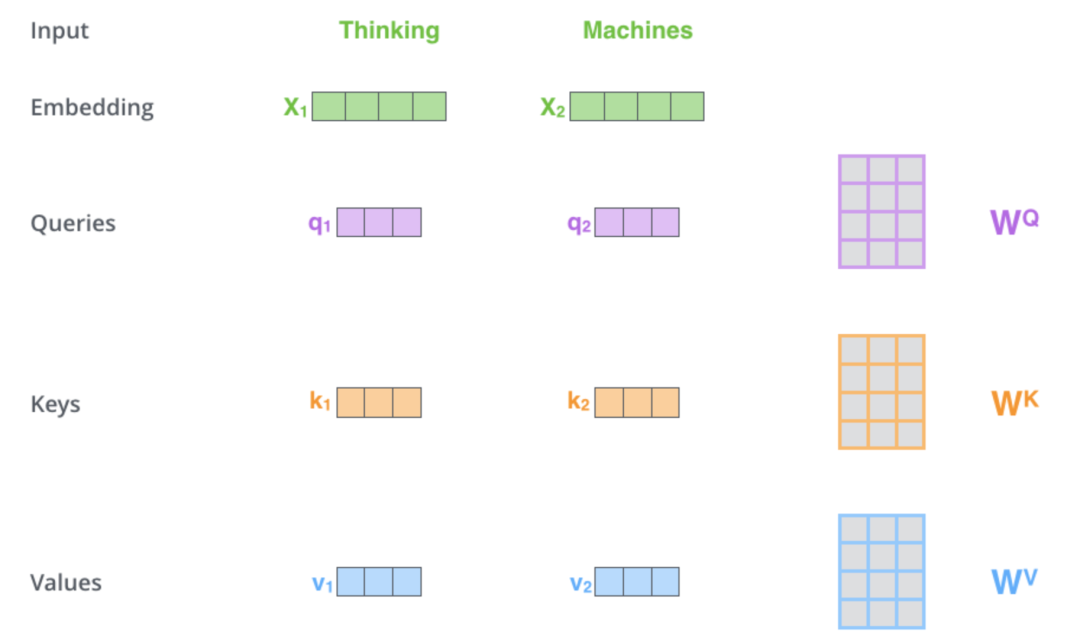
抛开Query, Key, Value的数学推导,我们需要有一个概念上的直观理解,给定一个输入的句子,假设我们要从情感角度看看当前单词应该关注其它哪些单词,输入的句子首先被投射到了一个情感表达的子空间,每个单词都有自己的Query,Key,Value 3个向量:
Key向量代表了当前单词情感特征,如[正/负向、强度、词性、复杂度...] Value向量代表了上述情感特征的取值 而Query向量则表示一种情感分析角度,比如“强烈的情绪”,从这个角度看,情感特征中的“正/负向、强度”比较关键,所以Query向量可能类似[正/负向、强度、Null、Null...]
而在判断哪些单词需要关注时,那些Key向量和当前单词Query向量比较相似的单词就是需要关注的单词。
有了这个直观的概念理解,我们再回到"Thinking Machines"的例子,为了计算当前单词需要关注其它哪些词,我们用当前单词的Query向量和句子中每个词的Key向量做点积(一种计算相似度的方法,几何意义可以理解为两个向量投影的乘积,两个向量越相似,其乘积越大):
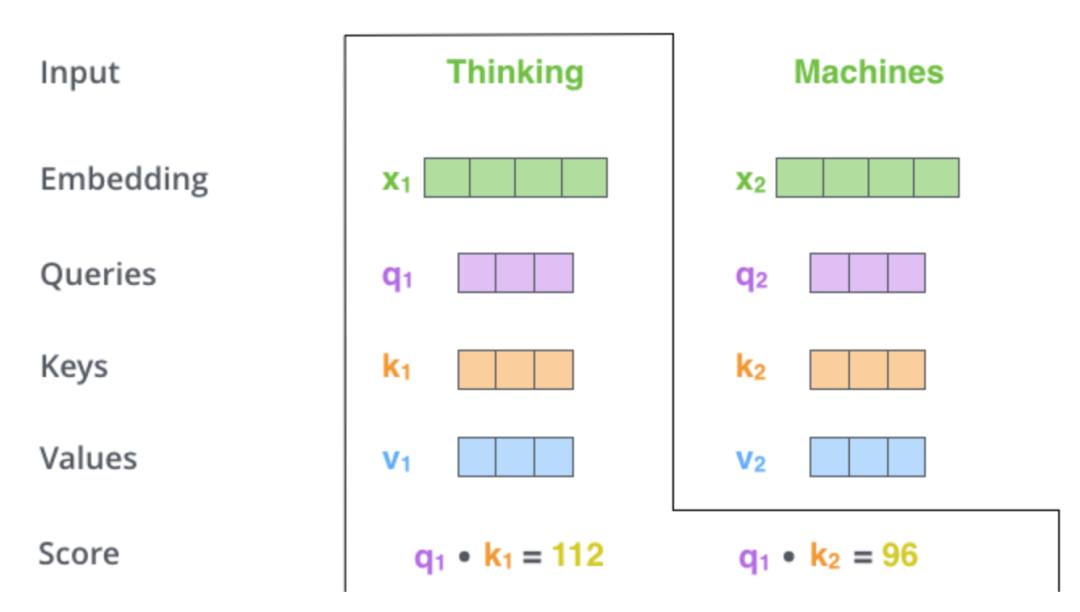
为了数学上好处理,我们把得到的相似度得分做个除法平滑梯度(一般取Key向量维度的平方根),然后再用Softmax函数处理一下:
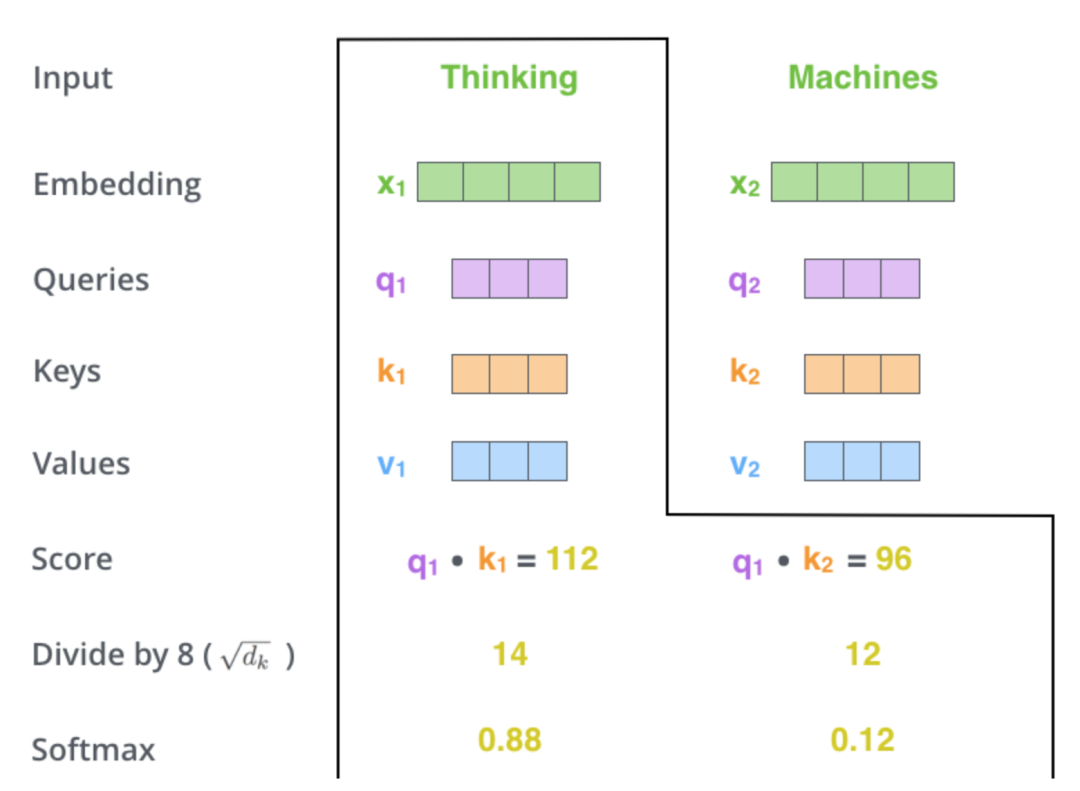
接着再用这个相似度得分,分别乘以各个单词的Value向量并加总得到当前注意力模块的输出,越是相关的单词,因为其相似度得分高,所以其Value对最终结果的影响也比较大,也就是得到的关注度就越高,反过来,得分越低的单词就越被忽略:
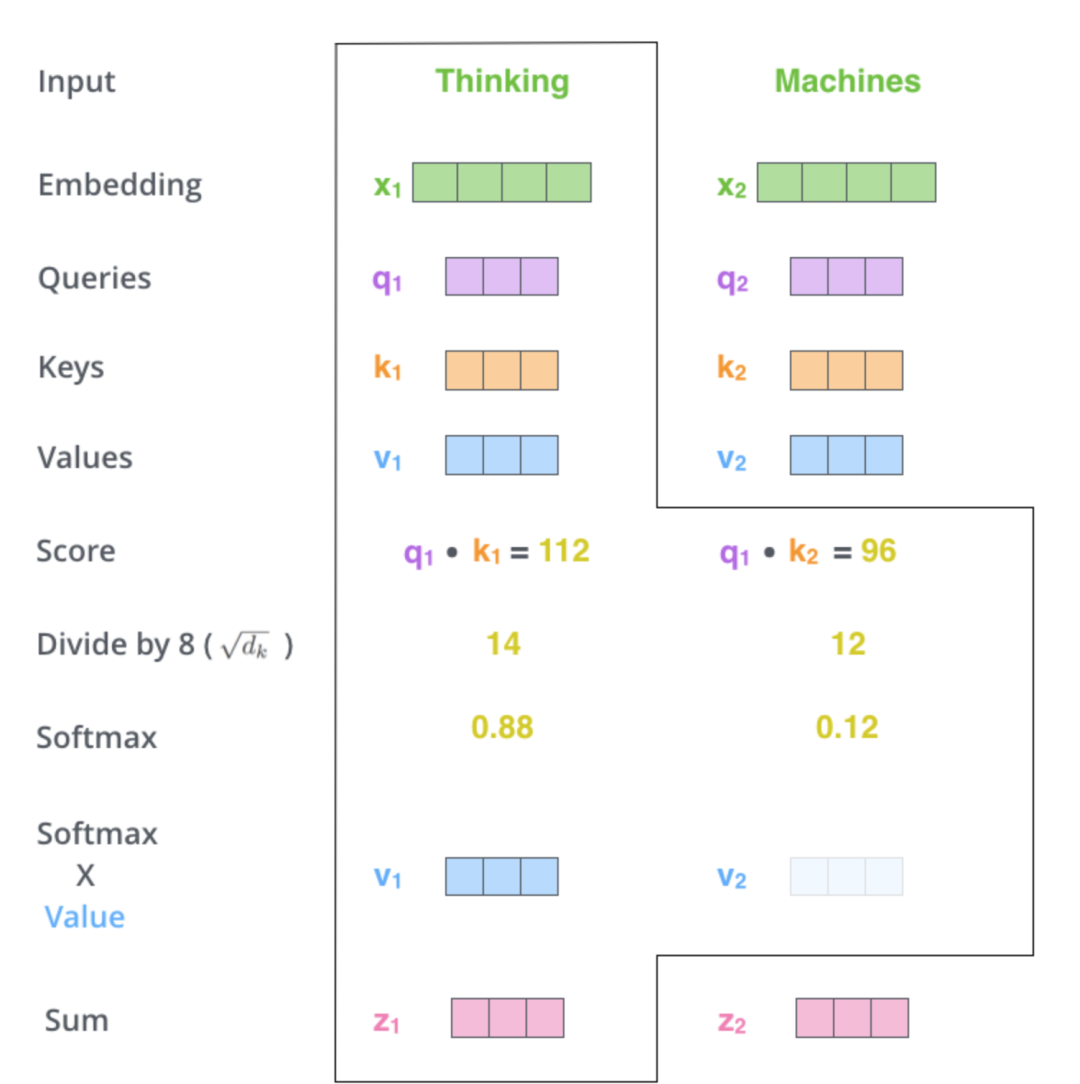
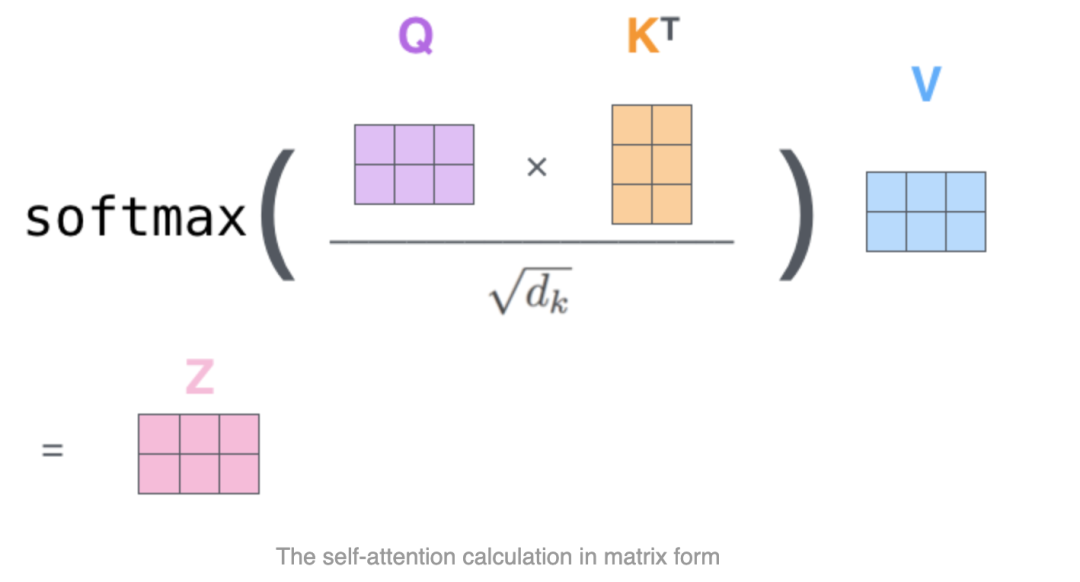
其整个工作过程可以表达为如下公式:
GPT-3是如何应用注意力机制的
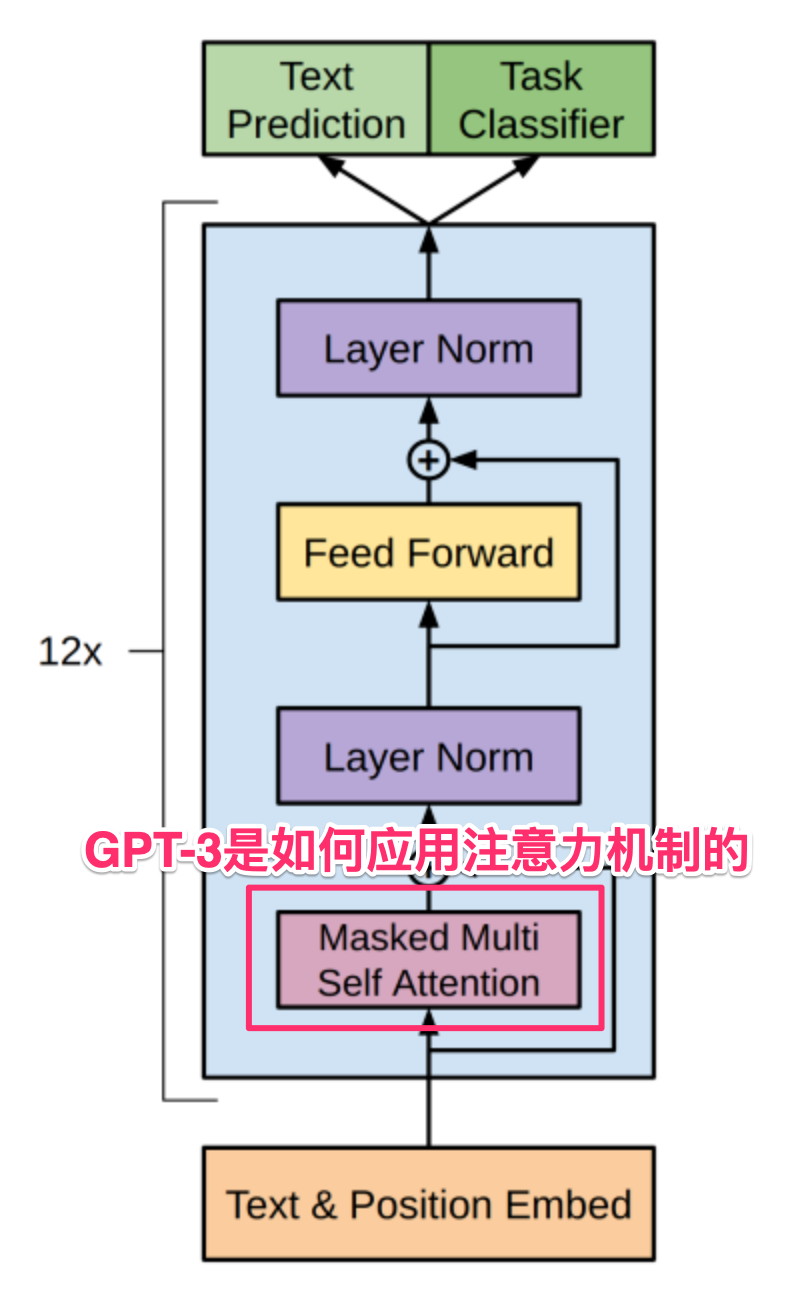
理解了注意力机制的工作过程后,我们再来看看GPT-3对它的应用。在GPT-3中,上述Query, Key, Value向量的维度是128维。
此外,在上面注意力工作机制的介绍中,我们只是举例了从情感分析的角度看当前词需要关注哪些单词,实际上,我们可以同时从多个角度来进行分析,事实上,GPT-3一共使用了96个分析角度(Attention Head)来判断需要关注的单词:
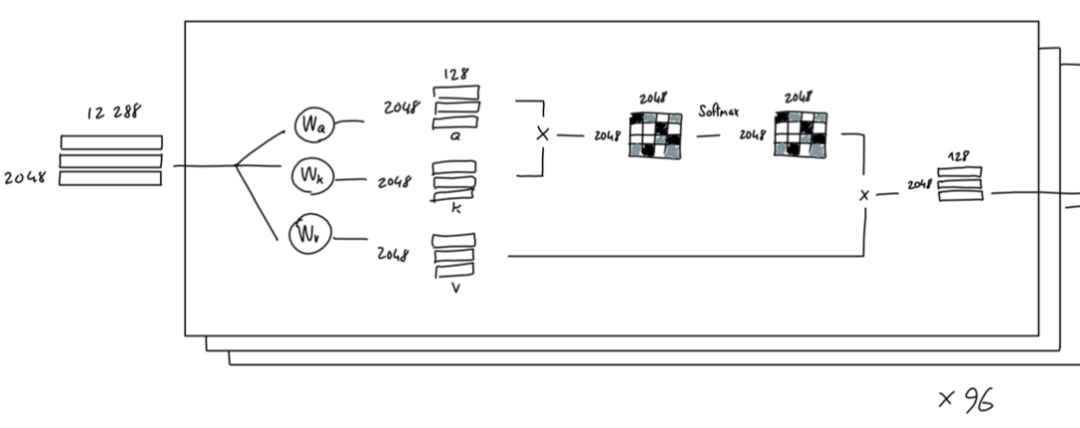
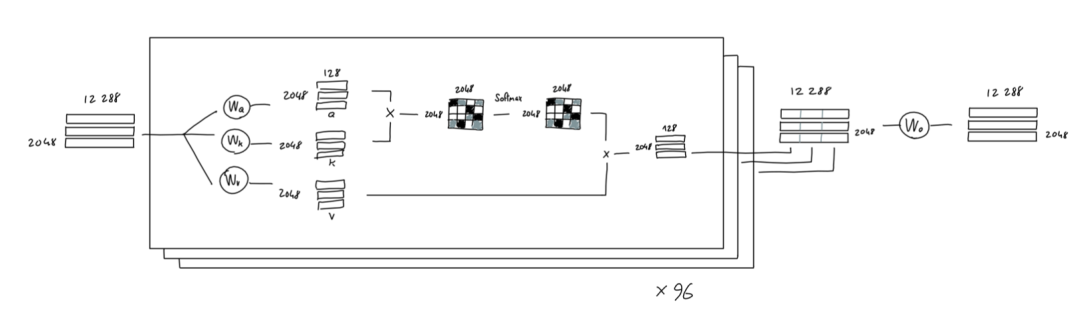
问题来了,96个分析得到的是96个矩阵,而下游处理期待的输入是和原始输入尺寸一样的一个2048 * 12288的矩阵,怎么办?处理办法也很简单,把这96个小矩阵直接拼接到一起(128*96正好是12288,这也是为什么Q,K,V为128维度,一共取96个Attention Head的原因),再通过一个线性变换最终得到一个2048 * 12288的矩阵:
前馈神经网络(Feed Forward)
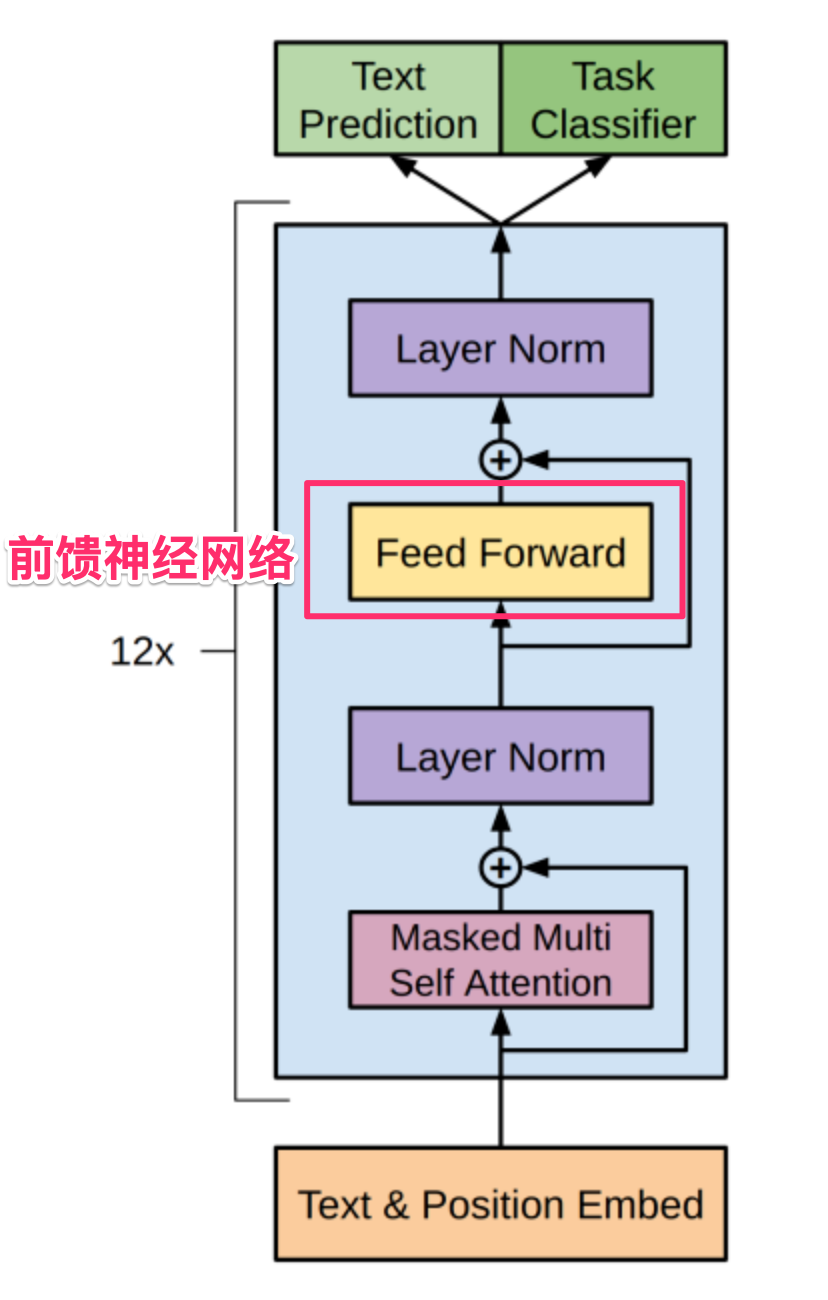
在GPT-3的注意力模块,从上面介绍的工作过程也可以看出,主要处理的是信息不同部分之间的关系,或者说是知识的内在结构,而我们知道,知识除了有其本质的结构外,还有事实性的信息,比如“中国的首都是北京”就是一种事实性的信息。在GPT的参数中,大约有1/3的参数是关于注意力模块的,而其它2/3的则是关于前馈神经网络的,有研究认为,事实性的信息就存储在前馈神经网络的参数中。
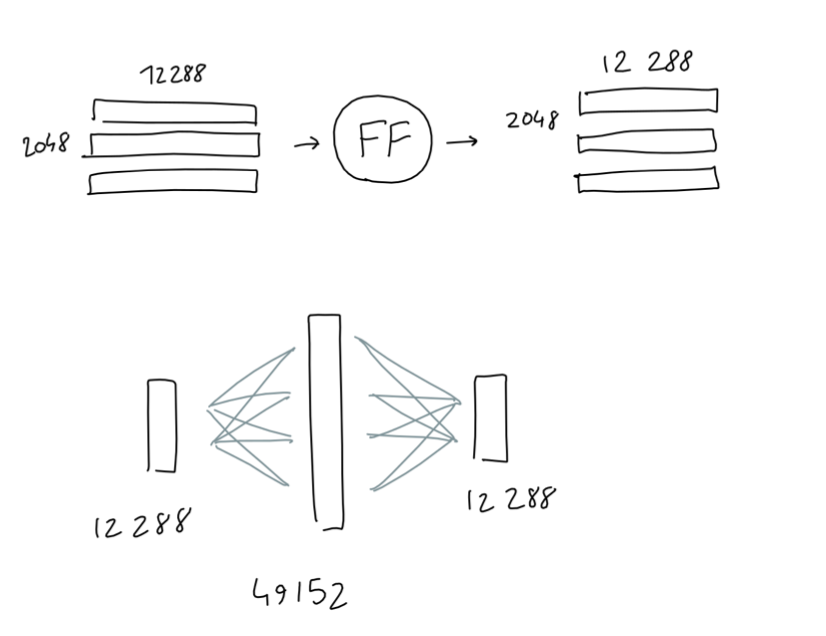
在注意力模块处理完成后,紧接着的是一个前馈神经网络,这个前馈神经网络和经典深度学习中的前馈网络没有差别,它只有一个隐层,其输入和输出都是2048 * 12288的矩阵,隐层则为4 * 12888,其结构如下图:
残差网络和规范化
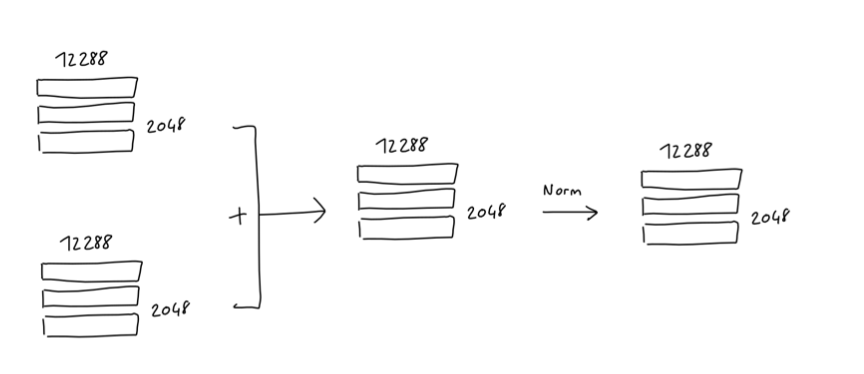
在深度学习中,当网络的层数非常多的时候,容易出现梯度消失的问题,在这种情况下,梯度变化过小以至于无法对网络进行有效训练,为了解决这一问题,一个常用的处理手段就是"残差网络",其思路也很简单:既然网络层数过多导致梯度消失,那我就跳过一些网络的层次直接把梯度传递下去,具体做法就是把N层网络处理后的结果(如上述注意力模块和前馈神经网络),直接再加上原始的输入,以增强梯度。
除了梯度消失的问题,为了提高神经网络的性能和稳定性,同时避免过拟合的问题,在深度学习中还常常使用规范化这一技巧(Layer Norm)来对矩阵进行处理。
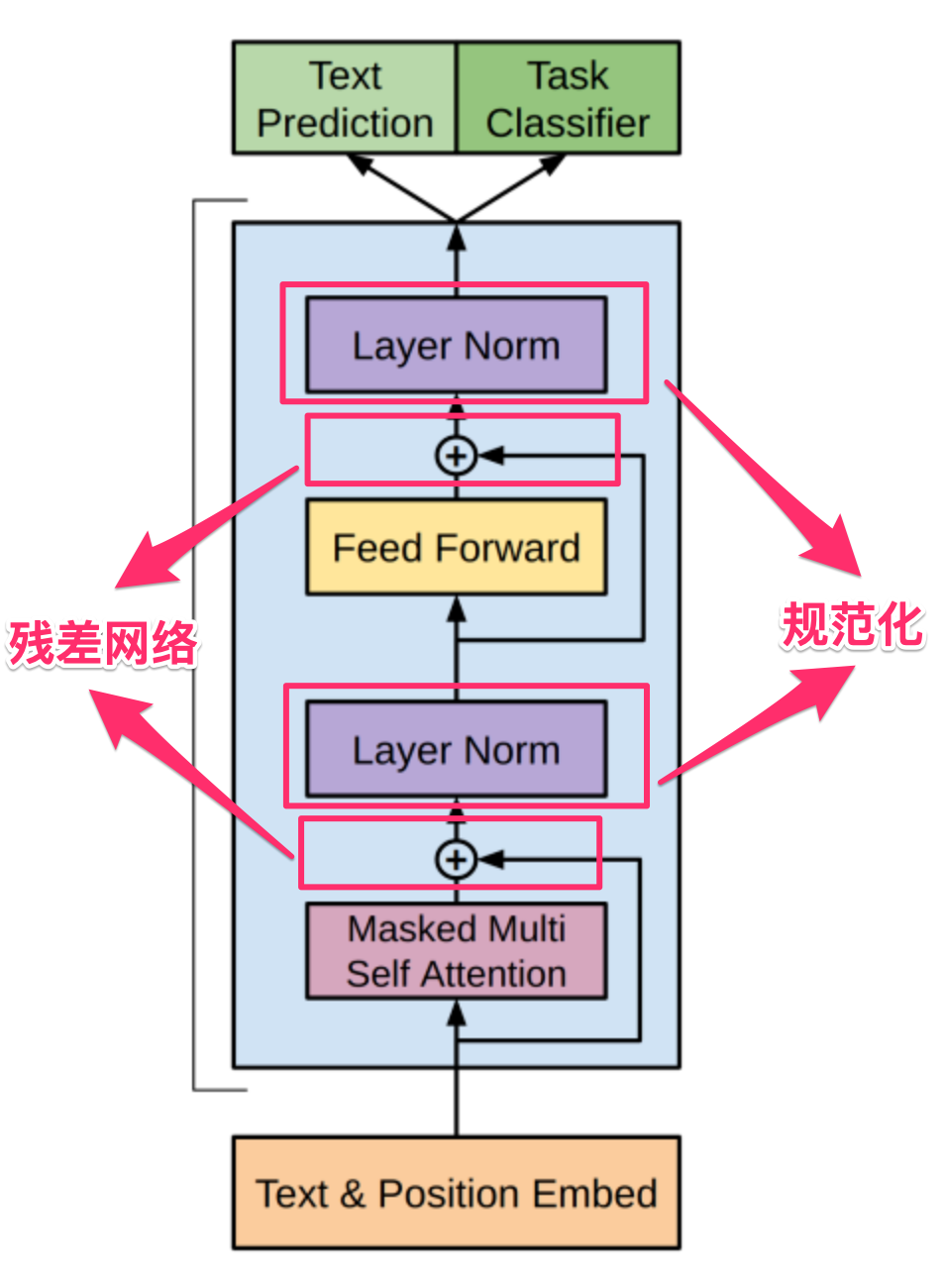
在GPT-3架构中,在核心的注意力模块和前馈神经网络模块处理完成后,都使用了上述的残差网络和规范化这两个处理技巧,处理前后,矩阵的大小保持不变:
到这里,我们就完整介绍了GPT-3中一个Decoder的完整工作过程,而GPT-3一共串联使用了96个Decoder,前一个Decoder的输出是下一个Decoder的输入。
解码得到最终输出
在GPT-3的96个Decoder完成所有处理之后,我们终于到了要计算最终结果的环节了。
在前面介绍的输入编码部分,我们把一个单词变成了一个12288维的Embedding向量,现在为了得到最终的结果,我们需要把这个过程反过来,通过一个映射把这2048个12288维的Embedding向量映射回GPT-3大小为50257个单词的词表中:
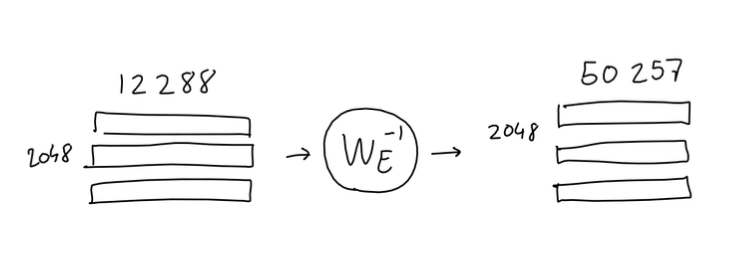
这里和处理输入不同的是,因为模型输出的下一个单词有多种可能,所以现在把Embedding映射回词表时,得到的并不是一个One-Hot向量,这里我们通过Softmax对映射得到的向量进行处理,使其不同位置上的取值为对应单词出现的概率,如果使用贪心算法,我们就取概率最高的那个词作为模型的最终输出: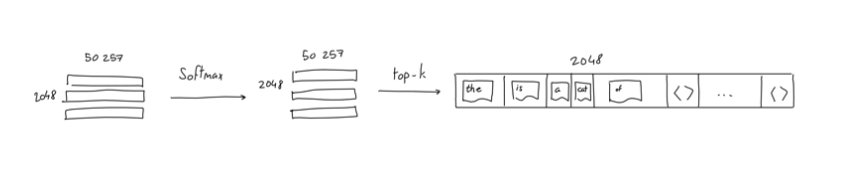
至此,我们就介绍了GPT-3的完整工作流程,把上面介绍过程中,所有的图拼到一起,就得到了如下的整体架构图(图中红色的是在训练中学习到的参数):

由于详细展示了所有的处理环节,所以图比较长,点开图片放大从左到右看就是完整的工作过程(最好是在电脑上看,图确实有点长)。
总结一下,虽然整个架构有很多细节,但其工作过程实际是比较简单的:我们首先把输入信息(包括位置信息)进行Embedding编码,之后通过注意力机制(通过投射到Q,K,V矩阵完成)获取输入信息的抽象结构,之后我们对这个抽象结构用一个前馈神经网络进一步处理得到一个输出Embedding,这个输出Embedding最后被映射为模型的最终输出。
说明:本文的内容是在阅读了大量文章和论文的基础上,结合我的理解整理而成的,文章的内容、尤其是插图很多都来自下面的参考文章,如果您想进一步深入理解GPT的工作原理,建议重点阅读如下文章和论文:
The GPT-3 Architecture, on a Napkin(https://dugas.ch/artificial_curiosity/GPT_architecture.html)
The Illustrated Transformer(https://jalammar.github.io/illustrated-transformer/)
Attention Is All You Need(https://arxiv.org/abs/1706.03762)
Improving language understanding by generative pre-training(https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf)
张俊林:由ChatGPT反思大语言模型(LLM)的技术精要(https://zhuanlan.zhihu.com/p/597586623)
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/oJriBCQ-p3URpXbHX4i9oQ Tag: ChatGPT 人工智能