这是本系列的第6篇文章,在这个系列中,我将尝试尽量用大白话的方式,来解释一些AI领域的基本概念,让更多像我一样的数学白痴也能理解AI。我相信不论AI背后的数学有多复杂,其基本思路一定是清晰的,可以用数学无关的方式讲清楚的。
ChatGPT这几个月可以说吸引了全世界的目光,在惊叹其卓越表现的同时,也有很多人把目光放在了其背后的训练过程上,看过相关文章的同学一定对下面这张图很熟悉:
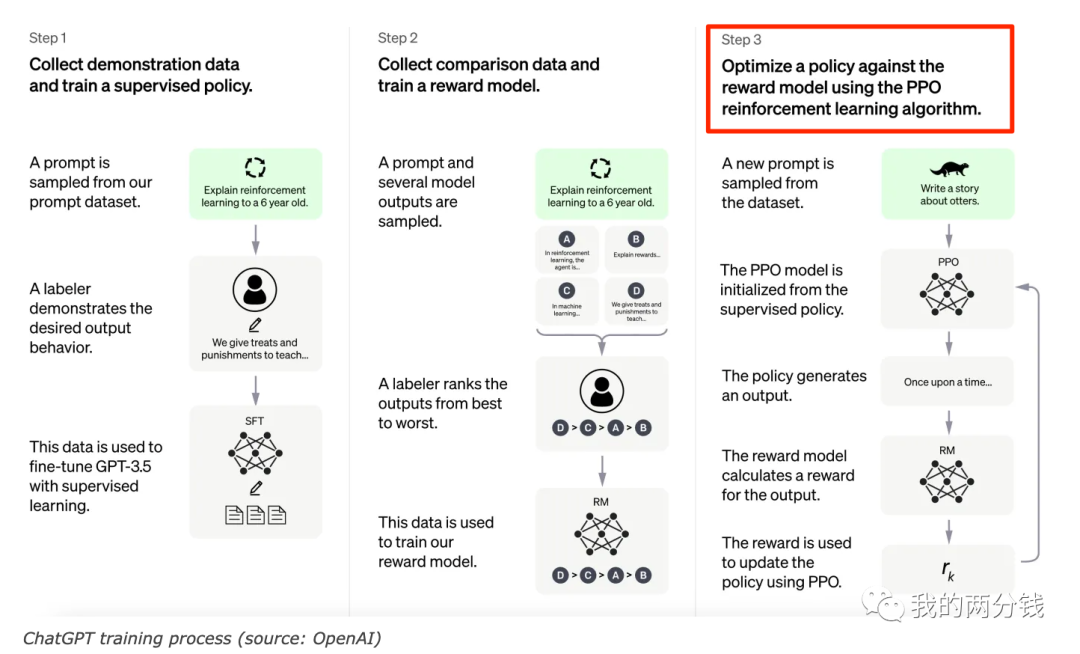
这张图就是ChatGPT使用的RLHF(Reinforcement Learning from Human Feedback)的工作过程,我会写一篇文章来专门详细介绍RLHF,作为一个基础,我们需要先了解图中第3步使用的PPO算法,和系列中其它文章一样,本文也将同样会尝试用非数学的方式把这一算法讲明白。
什么是强化学习(Reinforcement Learning)
要了解PPO,首先要了解它的使用场景:强化学习。强化学习背后的基本哲学是,知识是在同环境的互动中产生的,就像我们训练小狗,通过在和小狗的互动中给出的奖励或惩罚,我们能教会小狗期望的行为,在这个过程中小狗是学习的主体,环境就是它的主人以及训练场,互动就是它听到口令后采取的行动,而学到的就是比如听到口令就坐下等知识。
强化学习也是类似的工作过程,如下图所示:
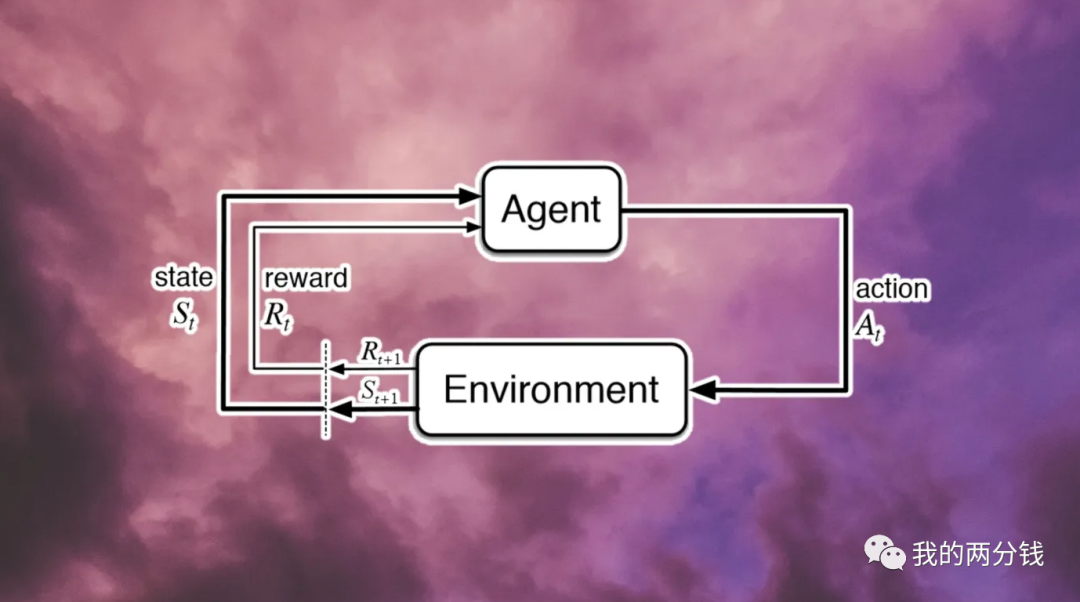
这里的Agent是学习的主体,它通过Action和环境进行互动,导致环境从当前状态S(t)进入到S(t+1)状态,同时环境对这个Action产生一个反馈R(t),Agent通过得到的反馈调整其行动策略Policy,这个循环进行很多轮之后,Agent就可以学习到一个比较好的Policy,也就是说从训练中学习到了知识。
强化学习和传统机器学习的区别
上面的图虽然看起来很简单,但很关键的是,知识需要多轮循环才能学习到,每一轮循环都是一个[s, a, r] (state, action, reward),经过若干个这样的[s, a, r]后才能完成学习。就好像我们下棋,每走一步棋就是一轮循环,而只有走了若干步后我们才能下完一盘棋有个输赢的结果,我们要优化的是整体的下棋策略,而不仅仅是其中单独某一步棋的好坏。
在传统机器学习比如图片分类问题中,每输入一张图片(或一个Batch),我们就可以计算损失函数从而调整模型参数。但在强化学习中,我们要优化的是若干个[s, a, r]组成的序列,假设在每一步可以采取的action都有2个选择,那么组合起来,一个长度为10的序列,就有2^10种可能性,如果序列每走一步我们就调整一次参数,只要序列稍长我们的计算资源就不够了。
这种对整体而非局部的优化就是强化学习和传统机器学习最大的区别。
还是拿下棋举例子,假设走了一步好棋就加分,走了一步臭棋就扣分,强化学习的目的就是找到一个策略,让最后的总得分最高,尽管棋局的每一步都很关键,但有可能为了最后的胜利,我们需要在有些步骤丢分(在当时的局面是臭棋,但是事后看可能是好棋),才能最终能整体得分更高。
强化学习的工作过程
理论上只要我们穷举[s, a , r]所有可能性,我们就可以找到一个最优解,但就如上文所说,随着序列长度的增加,可能性是呈指数级增长的,在复杂问题上进行穷举是不可能的,那么怎么办呢?
此时就要祭出我们大杀器了 -- 蒙特卡洛,说白了就是既然不能穷举,我们就采样,只要采样率足够,一定量的样本就可以代表整体的数据分布。
所以强化学习的过程就是,进行若干次采样,每次采样得到一个[s1, a1, r1] ...[sn, an, rn]的序列,然后计算其总得分,如果其得分为正,就调整模型参数增加其出现概率,反之则调整模型参数降低其出现概率。这样经过足够多轮的学习后,我们就可以得到一个不错的策略了。
大家可以看到,实际上述过程和求解梯度下降的过程是很类似的,实际上这个工作过程就叫Policy Gradient (PD).
平庸的多数掩盖优秀的少数的问题
对于一个强化学习问题,简化一下假设有100个可能的[s, a, r]序列,按照2/8原则,其中80个可能最终得分都比较平庸,由于我们在策略梯度中使用了采样的方法,所以大多数时候我们采样到的都是得分平庸的序列,而我们采样到这些序列后会调整模型参数增加其出现的概率,这样在训练过程中,得分平庸的序列权重会越来越高,挤占了真正优秀序列出现的可能性,这会导致我们最后学习到的策略也比较平庸。
所以我们要想一个办法让真正优秀的[s, a, r]序列脱颖而出。这里要讲一下亚马逊的招聘原则,亚马逊希望招聘进来的员工水平是越来越高的,他们采取的办法就是,当决定是否offer一个候选人的时候,不但这个候选人的能力要符合工作要求,而且其工作能力要比现在组里的中位数水平要高,虽然这个没法完全量化,但大致原则是这样。
而让优秀[s, a, r]序列脱颖而出的方法就和亚马逊很像,每次采样得到一个序列后,不但其本身得分要为正,而且它的得分还要比到目前为止、所有序列的平均分高才会调整模型参数增加其出现概率,否则就降低其出现概率。
一人得道鸡犬升天的问题
在强化学习中的另外一个问题是,每当我们找到一个优秀的[s, a, r]序列时,我们是调整权重增加这个序列整体出现的概率,但我们知道一个序列包含很多个步骤,有可能虽然这个序列整体得分很高,但其中有些步骤可能其实并不好,就像一个水平很高的棋手也会走臭棋一样,在提升整个序列出现概率的同时,这些臭棋出现的概率也增加了。
一旦问题清楚了,解决起来其实也很简单,这就是一个寻找最优子序列的问题。在此基础上,我们还可以给序列中的每一步加一些权重,使得当前步骤的得分对接下来几步的影响比较大,之后影响就越来越弱,就好像我们下棋,当前这一步棋的好坏对下面两三步棋的影响比较大一样,具体的数学推导就不在这里展开了。
学习效率太低的问题

强化学习的过程是 采样->调参数->采样->调参数-> ...这样一个不断循环的过程,当要处理的问题比较复杂的时候,这个过程收敛的速度往往很慢,需要很长的学习时间才能有一个比较好的结果。这就好像是一个学生,在一个复杂领域中摸索学习需要比较长的时间一样。
针对这一问题,业界提出了很多的解决办法,其中本文标题提到的PPO(Proximal Policy Optimization) -- 近端策略优化,就是各种解决办法中非常优秀的一个。
PPO的基本思路也很简单,既然一个学生自己学习比较慢,那我就给学生配一个老师,让老师带着学生学来加速学习。其具体工作方式是,在某一个环境状态S下,不是让待训练的目标策略(学生)自己来选择某个Action从而拿到环境的反馈,而是让一个代理策略(老师)决定采用什么Action,然后拿到环境反馈,也就是说用代理策略代替目标策略完成采样工作,然后根据采样的结果来调整目标策略的参数,因为有了老师的代领,所以学生的学习就能大大加速了。
那么问题来了,老师又是从哪来的呢?实际上老师也是训练而来的,这个代理策略(老师)往往比目标策略简单(如参数更少),但是又和目标策略相似(可选择的Action是目标策略的子集)。类比一下就像是在一个新的领域,虽然老师也不是太懂,但是他有相关领域的经验,这样在学生学习的时候,老师虽然不懂具体的问题,但是能给出很好的方向性建议一样。
由于代理策略比较简单,可以相对较快地训练得到,之后再用这个简单但类似的代理策略来辅助目标策略的学习,就能提高整体的学习效率了。
总结一下就是,强化学习是在同环境的交互中学习知识,这个交互是个多轮交互[s, a, r](环境状态,动作,反馈)的迭代,其目的是找到多轮交互的整体最优解,在实践中,我们往往使用采样的办法来应对可能交互序列指数级增长的问题,采样带来了优秀交互序列可能被掩盖的问题,我们通过类似亚马逊招聘高于平均水平员工的方式来解决,同时我们还可以通过寻找最优子序列的方法来聚焦在那些真正有效的步骤上,最后PPO借鉴老师带学生的思路大大加速了强化学习的训练速度。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/jenNBY379FOQcshcyw4n3A Tag: ChatGPT 人工智能