最近ChatGPT的问答对话在网上真是赚足了眼球,想必大家都已经见识到了。
不知道大家有没有这样的疑问,ChatGPT的实现原理到底是什么,他的能力边界又在哪里?
为了解决这一问题,我进行了大量的网上冲浪,但网上很多内容要不就是讲了跟没讲一样,要不就是讲的过于专业,理解起来比较困难。
如果你希望能够以通俗易懂的方式去理解ChatGPT的实现原理,那么就请继续往下看吧。
ChatGPT是Chat和GPT两个词的组合,实际上是GPT在聊天场景下的应用,所以要理解ChatGPT首先要从理解GPT开始。
一、理解GPT(Generative Pre-Trained Transformer)
我们可以把GPT理解为一个会做文字接龙的模型。当我们给出一个不完整的句子,GPT会接上一个可能的词或字。类似我们在使用输入法时,我们输入上文,输入法会联想出下文一样。
举个例子:
当你输入“我们”,GPT可能会给出“去哪”;
当你输入"我们去哪",GPT可能会给出“吃饭”;
当你输入“我们去哪吃饭”,GPT可能会给出“呀”
... ...
以此类推。最后可能生成一句话“我们去哪吃饭呀?”
用GPT的好处是:
它可以利用互联网中大量的文本内容进行学习,这种学习可以自动进行,不需要人工标注。
然而GPT也有他的弊端:
1.GPT不是以问答的形式进行内容输出的。
例如:当你输入“中国最高的山是哪座?”,GPT输出的可能是“谁能告诉我答案呀?”。显然这并不是你想要的答案。
2.GPT是按照概率对结果进行输出的,因此它可能会输出各种各样的结果。
还是以上面那个那句话为例,当你输入“我们”时,GPT可能会输出多种结果,比如“我们今天放假”“我们交个朋友吧”等等。
怎么解决这个问题呢?那就需要来引导GPT的输出方向了。
二、引导GPT的输出方向。
图中为ChatGPT的原理图,这个引导的训练过程我们可以分为三步来理解:
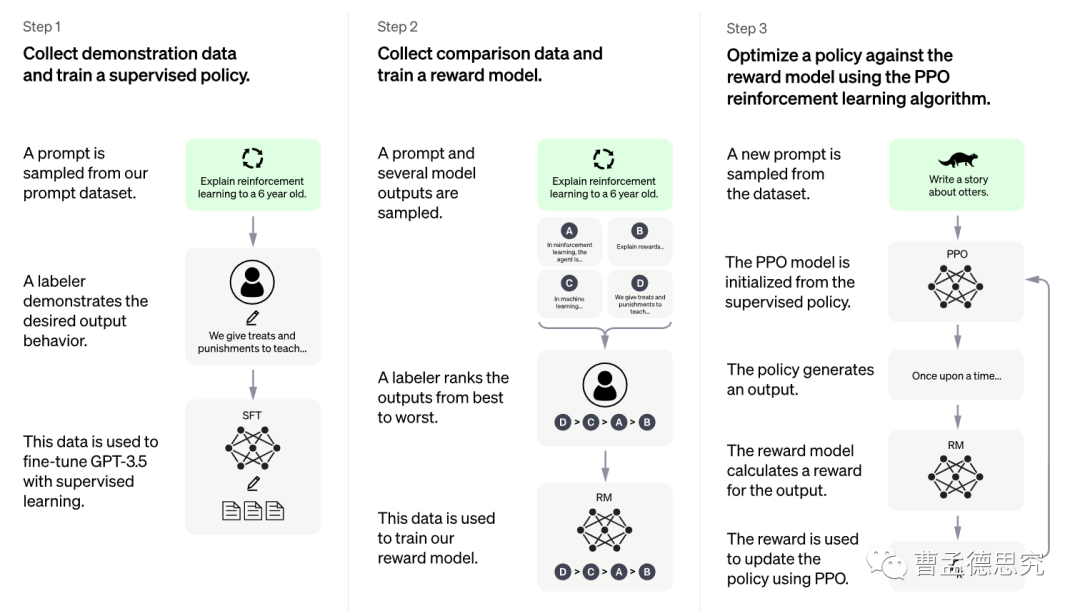
第一步(STEP 1):
采用问答式的样本对GPT模型的输出方向进行监督训练,引导GPT采用问答对话的形式进行内容输出。
第二步(STEP 2):
训练一个奖励模型(RM)。这个奖励模型就好比一个老师,当给出一个问题和四个答案,老师负责按照人类的偏好给这些答案进行打分,将答案进行排序,如图所示就是D>C>A>B。
用问题和四个答案作为奖励模型的输入,人工打分作为问题的输出,通过一定数量样本的训练,可以让这个奖励模型模仿人类老师对结果进行打分。
第三步(STEP 3):
通过以上两步,我们有了一个具备对话能力的GPT,和一个能够按照人类偏好进行打分的奖励模型。从而便可以构建一套强化学习模型对GPT进行进一步的训练。
强化学习的过程我们同样可以用老师和学生的例子来进行理解。GPT就好比一个学生,他会针对问题给出自己的回答。而奖励模型就是一个老师,会对GPT的答案进行打分,学生为了得到更高的分数,就要学着去给出老师更喜欢的答案。从而便实现了GPT的自我训练。
通过以上的训练后,一个ChatGPT的模型就产生了。
三、ChatGPT在生活中的应用
其实我们生活中的一些场景非常适合用于ChatGPT的训练。
当你在网上搜索一个问题时,搜索引擎会给出多种结果。在众多的结果中,你选择了其中的一部分进行浏览,同时在浏览完成之后可能会有点赞、评论或转发的操作。
搜索出的多种结果可以类比为GPT输出了几种不同的答案。人类的浏览、点赞、评论或转发的行为便是奖励模型。
GPT为了在互联网中获得更多的认可就需要不断调整自己生成的内容去迎合人的喜好。而在这个训练过程中,我们每个人都扮演了老师的角色。
所以我认为国内能够利用这项技术实现腾飞的,还得是掌握的大量用户入口和用户数据的应用,例如:百度、头条、B站、腾讯、抖音、知乎等。此外,由于这些算法模型对大算力的要求,可能会对硬件产品如服务器、算力芯片等能带来一波新的刺激。
四、ChatGPT未来演化的方向
关于ChatGPT未来的演化方向,我觉得一个可能的方向是要通过大数据去构建一个评价“谁才是好老师”的模型,让好老师的认可比水军老师的认可更有价值,这样才会让社会向着正确的方向继续发展。
其实到目前为止,很多互联网中的评价体系中并没有引入这个“谁才是好老师”的模型,利用水军或好评返现刷评价的情况仍蔚然成风。
最后我们不妨再来看一下人工智能的演化模式:
1.学生自我学习;
2.建立一个老师模型来对学生进行引导;
3.建立一个考核模型来对老师进行引导;
4.建立一个更高层级的模型对考核模型进行引导;
... ...以此类推
其实这个过程和数学中的一个概念很相似
1.有一个函数f(x);
2.用f(x)一阶导数对f(x)的方向进行引导;
3.用f(x)二阶导数对f(x)一阶导数的方向进行引导。
... ...按照这个思维,目前我们的人工智能的训练模式才进行到一阶导数的模式,未来还有无限次求导的可能,至于未来是否要这么做,则需要结合成本与收益进行综合考量。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/qD1IIrbijbGOixaKDxz4cA Tag: ChatGPT 人工智能