OpenAI为何限制ChatGPT在中国的使用,虽然官方暂时没有给出回应,但是我们也许能从斯坦福羊驼模型上发现这其中的原因。
众所周知,人工智能的三要素是模型、数据和算力。
要训练高质量的大语言模型,即使有了足够的算力,仍存在两个重要挑战,一个是要有一个强大的预训练语言模型,另一个是要有大量任务样本对模型进行训练。而最近斯坦福发布的羊驼模型可能为我们提供了一个新的解决思路。
如图是羊驼模型的训练原理。
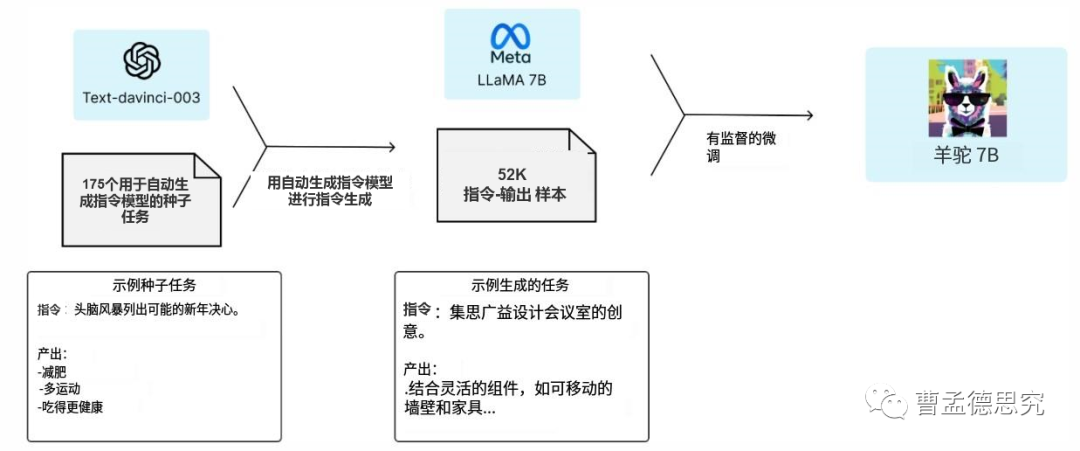
我们大体可以把它分成两步:
第一步:通过OpenAI GPT-3.5的text-davinci-003模型和175个种子任务,构建出任务自动生成模型,为预训练语言模型生成52K的样本数据。
第二步:采用meta新发布的LLaMA模型作为预训练语言模型,将第一步中生成的任务作为样本来训练这个语言模型,最终生成了Alpaca羊驼模型。
其中,第一步所采用的任务自动生成模型的结构如图所示。每个任务可以认为由指令和实例构成,而实例就是这个指令的输入和输出。例如:
指令为“在这个话题上给我引用一位名人的话”,
指令的输入为“诚实的重要性”,
对应的输出为“诚实是智慧之书的第一章——托马斯.杰斐逊”。
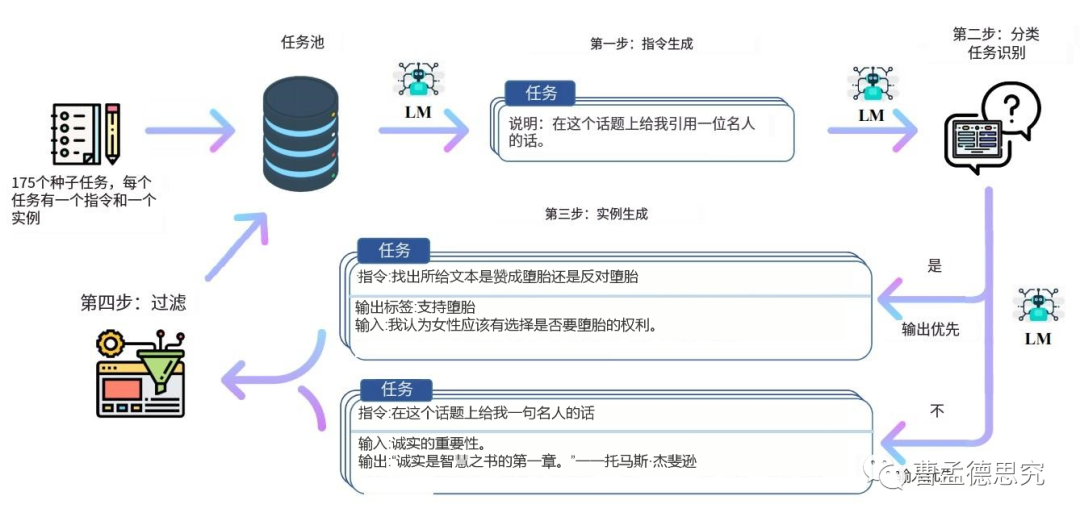
这个模型具体的做法是:
(1)利用text-davinci-003模型仿照种子任务进行指令生成。
(2)通过text-davinci-003模型为指令生成输入和输出。在这里分类任务和非分类任务的实例生成方式有些差别。
(3)对生成的任务进行过滤,将质量不高的任务剔除,其余放到任务池中。
羊驼这种模式的成功意味着,我们可以利用现有语言模型为新的语言模型生成大量的样本数据,那么在模型后续的迭代过程中,样本将不会再成为训练的瓶颈。(这可能对某些做数据标注的上市公司形成利空)
也正因如此,AI后续的进化将更加侧重于模型调优,也就需要我们对人脑的运行方式有着更深的理解,并将其原理应用到AI模型中。
可以说,斯坦福的羊驼模型改变了AI的竞赛规则,它为后来者提供了一个新的训练思路,可以用一个已有的模型去训练另一个模型。而OpenAI可能也预见到了这一点,在他们的使用条款中有明确说明:限制使用此模型的输出去训练其他模型来与OpenAI竞争。

或许正因为如此,ChatGPT才没有向国内开放,而且ChatGPT也没有提供API接口。因为ChatGPT背后的数据库是OpenAI投资数年的成果,是OpenAI的护城河,又怎能愿意让其他竞争者如此方便的获取呢?可以预见的是,后续新的AI模型只会越来越封闭,可能会采取更多的技术手段来防止竞争者的恶意利用。
而且这一训练模式的出现将加快AI模型的迭代速度,意味着AI的进化将正式进入快车道。在大国竞争的大背景下,我们的自己大模型还是要能够尽快出来才行,不然这之间的差距将会越来越大。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/32RCbvZKpdYwfr9zUUVJig Tag: ChatGPT 大陆禁用