ChatGPT虽然很强大,但在业务中实际落地成本也不低,而很多实际问题,其实不用ChatGPT这么强大的工具就能解决,我们在上一篇文章中,通过几行代码就实现了基于RNN(循环神经网络)架构的专属模型。但RNN到底是什么?它的工作原理是什么?本文将试着回答这些问题,并会和大家一起一步步地从头实现一个RNN模型。
RNN背后的基本思想
我一直相信任何复杂的事物背后,都有一个简单的想法,对RNN也是如此,在我们深入细节前,我们先来直观地理解一下RNN背后的思路。
在NLP领域中,最常见的问题形式类似于填空题,比如给出"the sky is __",然后模型预测缺少的单词是"blue"。其它类型的问题大多都可以转换为这种填空题,比如上篇文章实现的影评分类问题,假设影评为 "I love the movie, because ...", 这就可以转化为 "I low the movie, because..., it is __",然后模型预测缺少的单词是positive 或 negative。 再比如类似ChatGPT这种对话问题,也可以转化循环预测下一个单词的问题。
这种填空题的一个明显特点是,问题的答案依赖于句子前面的单词,比如把"the sky is __"换成"the milk is __",答案则会从blue变成white。这里让我们思考一下,如果让我们自己来找一个解决方案,我们会怎么做?
一个最直接的想法就是,统计训练语料中各种词组的出现频率,然后把出现频率最高的词组作为答案。比如我统计两个单词组合的频率,在语料中可能有“is blue", "is white", "is great", "is possible"...等这些组合,假设"is blue"的出现频率最高,我只要看到前面的单词是"is", 我就预测下一个单词是"blue"。
这个办法的缺点也很明显,只要碰到"is"就输出"blue",这在很多情况下是不靠谱的,比如我们说"the milk is blue"就很奇怪,出现这个问题的原因是我们的上下文太短,所以直接的想法就是,那我们就不但统计两个单词组合的频率,我们还统计3个单词组合的频率,如果效果还是不好,就统计4个,5个...单词组合的频率。
上面的这个思路实际就是我在"从N-gram到GPT,AI语言模型的成长之路"中介绍的N-gram,但N-gram也有很大的局限性,假设我们的词表有10,000个单词,那么单词排练组合几乎是无限的,所以我们只能限定组合中单词的数量,这也就是N-gram中N的来由,但限定了N的大小,又会影响模型的性能,所以虽然N-gram虽然曾经一度是NLP领域的主流解法,但效果一直差强人意。
我们仔细思考一下N-gram,可以发现这个解法是从统计角度入手,完全忽略了句子的语法、语义,而实际上语法、语义对预测下一个单词有着关键作用,比如"I grown up in China, so I an speak __",根据语义,我们很容易预测下一个单词是"mandarin",但N-gram忽略了语义,所以就很难给出正确预测。
考虑到语法、语义,一个自然的想法就是,我们在进行预测时,如果能获取之前句子中的关键信息,那么就容易做出正确的预测,比如"I grown up in China, so I an speak __",最后一个单词是speak,如果我们知道句子前面的关键信息是"china",那么做出正确的预测就不难了。
问题来了,对任意一个句子,我们如何知道什么信息对预测下一个单词是关键的呢?因为我们碰到的句子千变万化,所以很难有一组明确的规则来描述如何提取关键信息。这个问题困扰了业界很多年,直到神经网络的出现,才出现了转机。
我们知道,神经网络很善于表达这种难以用明确规则描述的问题,举个例子,虽然人类一眼就能判断出一幅画里面有没有鸟,但是我们却很难定义一个识别鸟的明确规则,而神经网络则能轻易解决这个问题。所以,当神经网络出现后,人们很快就将其应用到了提取关键信息预测下一个单词的问题上,这也直接带来了RNN的出现。
RNN的思路也很简单,对于一个句子从前到后,每看到一个单词,我们就动态地提取一下关键信息,然后把这个关键信息传递到下一个单词,当我们看到下一个单词后,就结合这个单词和之前传递过来的关键信息,再次更新关键信息,然后再向下传递...,当我们需要预测的时候,就结合最后一个单词和这个关键信息进行预测:
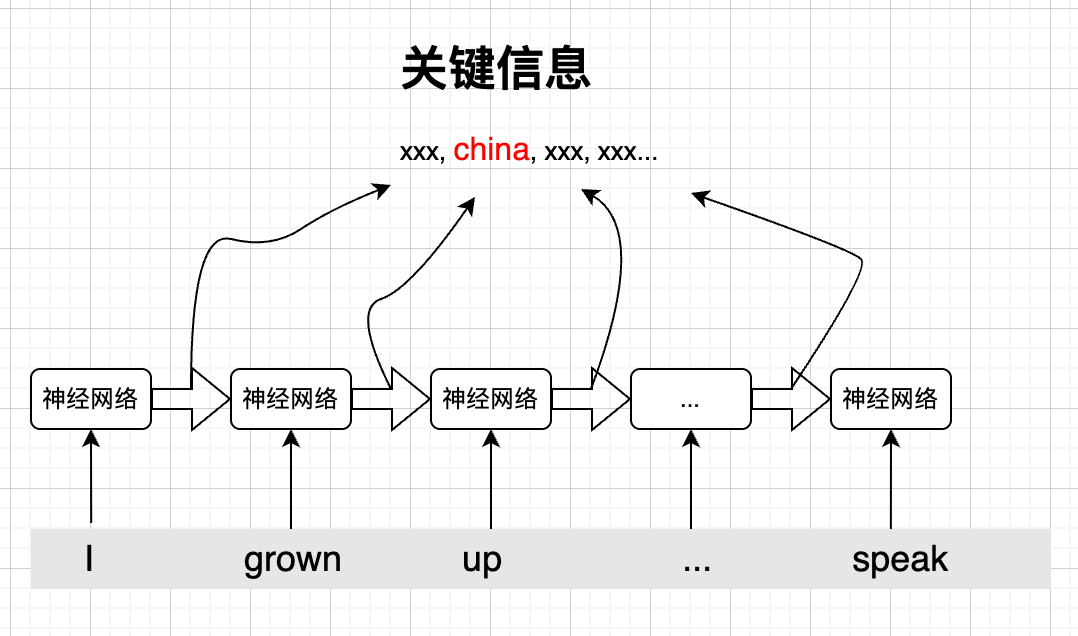
RNN的模型架构
理解了RNN的思路后,我们来看看真正的RNN模型架构:
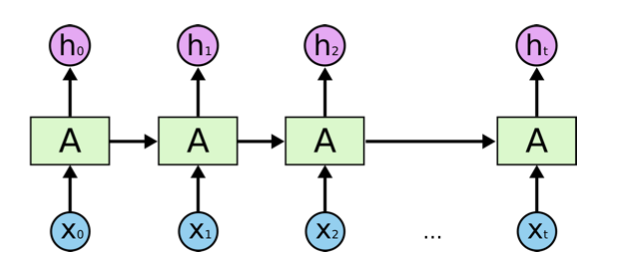
可以看到,其架构模型和上面介绍RNN思路时的示意图很像,这里的X0, X1, ... Xt对应句子中的单词,图中绿色的方块就是神经网络单元,而h0, h1, ... ht就是传递的关键信息,这里和我们的示意图的区别是,关键信息不但在神经网络单元间传递,同时也向外输出,这么做的原因是,不但在最后一步我们可以对下一个单词进行预测,实际上,在这个循环的每一步我们都可以对下一个单词进行预测,所有这里每一步也都把关键信息对外输出。
如果我们把这个图放大,想看得再详细一点,那么我们将会看到:
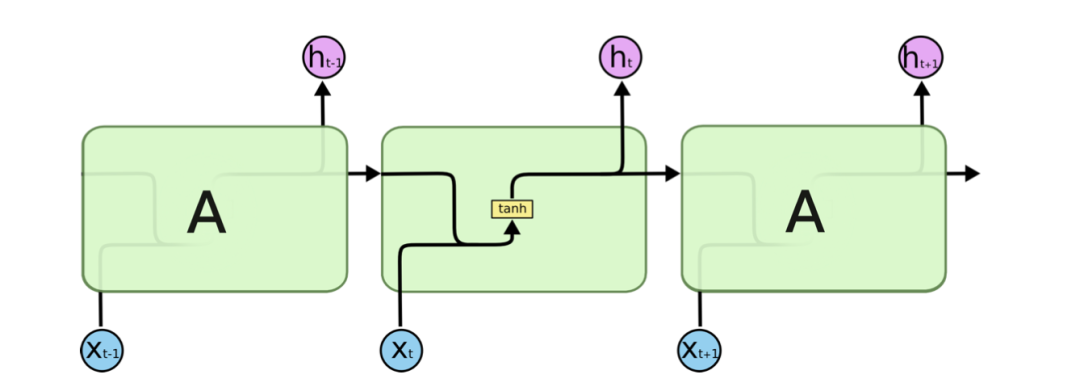
这里,我们可以明确地看到,同样一份关键信息,既向下传递也向外输出,这里我们还能看到一个细节,那就是关键信息在输出和传递前经过了一个叫做tanh函数的处理,这是一个神经网络的实现细节,主要目的是为了把两个神经网络单元连接起来。
在实际实现RNN的时候,这些不同的神经网络单元,使用同样一套参数(权重),所以上面这个长长的链条可以卷起来,如下图所示:
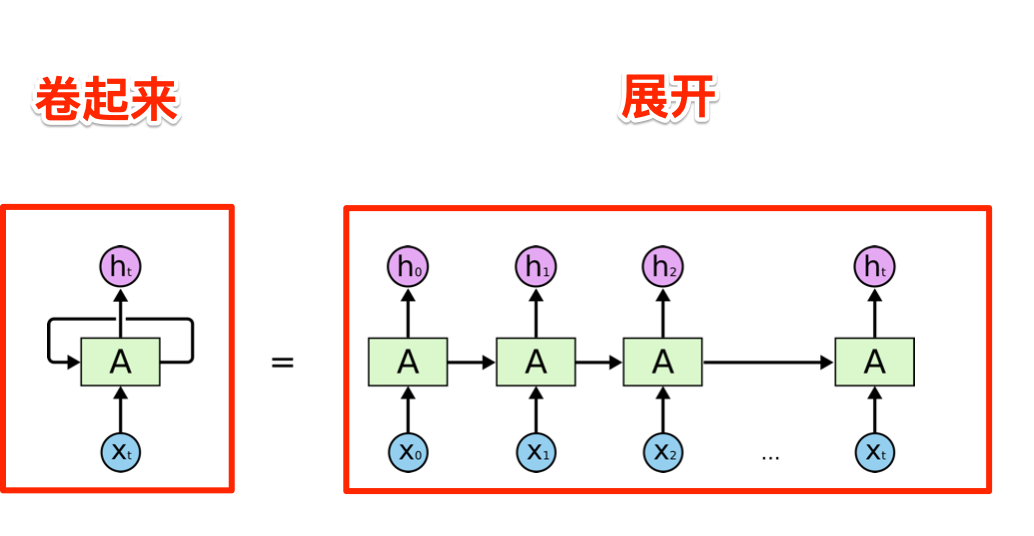
基本上,这就是RNN的架构,当我们明白了其背后的基本思路后,RNN还是非常好理解的。
在理解了RNN架构的基础上,要彻底把握RNN,最好的办法就是自己动手实现一个,接下来,我们就来一步步从头打造一个我们自己的RNN,我们将用这个RNN来预测给出句子的下一个单词。
首先,准备数据
作为一个例子,我们将再次使用fasi.ai事先为我们准备好的数据集,这个数据集里面是从1到10,000中间所有数字的英文单词,比如9,999就是"nine thousand nine hundred ninety nine",我们还是首先准备好开发环境:
接着把所有的数据全部加载进来:

我们把所有这些数字用"."连接成一个大的字符串:

Token化,数字化,批量化
如我在上篇文章的介绍,要训练一个神经网络,我们首先需要把训练数据Token化,数字化和批量化,因为我们的训练数据比较简单,所以Token化也很容易,只需要用空格分割字符串即可:

而建立词表也只需要把所有的token去重即可:

数字化则取各个token在词表中的下标即可:

为了由浅入深,咱们稍后再实现在序列的每个位置上都预测下一个单词,我们暂时先实现看到3个连续的单词后再做一次预测,相应地,我们也把我们的Token切分成若干个长度为3的序列集合,然后用紧跟着的单词作为预测的目标:

如前所述,神经网络需要数字输入,所以我们需要把上述过程数字化:

这样我们的Token化、数字化的工作就完成了,接下来我们需要把数据批量化:

准备工作完成了,终于可以开始动手实现我们的第一个RNN模型啦。
动手实现第一个RNN模型
因为是第一次自己实现RNN,在敲代码前,我们先用一张图进行一个详细的说明:
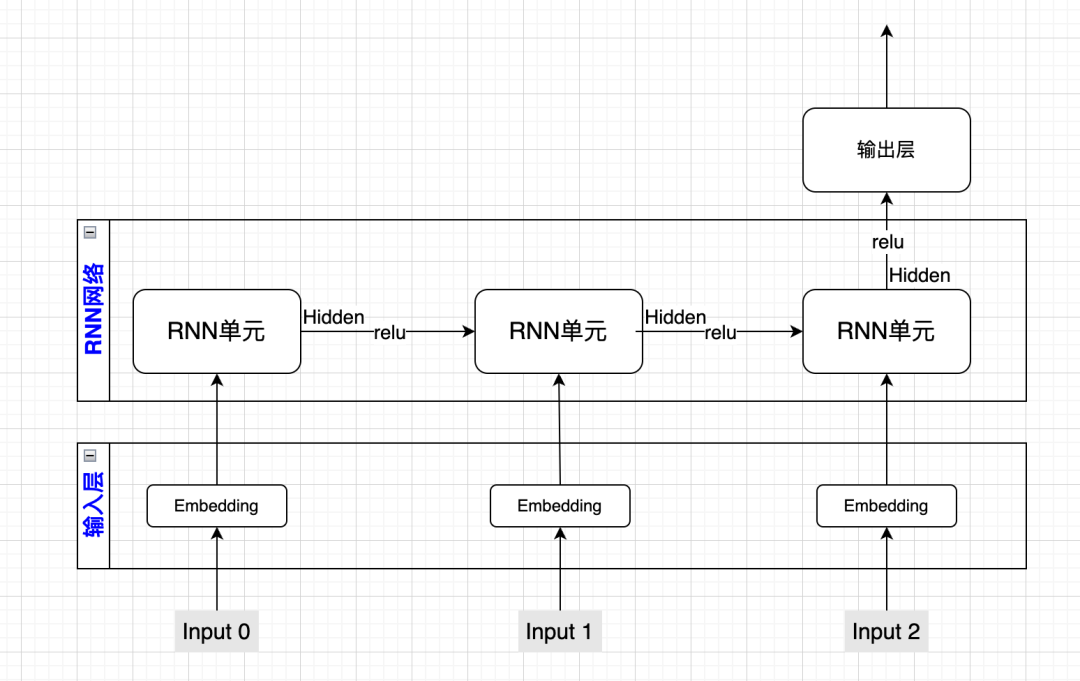
因为我们的序列长度为3,所以图中有3个input,对应序列中3个token的数字化结果,为了表达token更丰富的语义,我们用一个输入层把input映射为Embedding(词向量)。
接着我们把Embedding作为输入交给RNN单元,RNN单元把之前的Hidden态(就是要传递的关键信息)和Embedding加起来,乘以RNN单元的权重参数作为新的Hidden态(向下继续传递的关键信息)输出。
为了把两个RNN单元连接起来,我们用relu函数对Hidden态做一个变换,然后输入给下一个RNN单元。(在前面思路介绍时,我用的是tanh函数,relu函数实测效果更好,所以这里没有用tanh)
我们把最后一个RNN单元输出的Hidden态,作为输入交给输出层,由输出层根据这个Hidden态给出最终的预测。
下面我们就把这张图实现为代码:

接下来,让我们看看模型的效果:
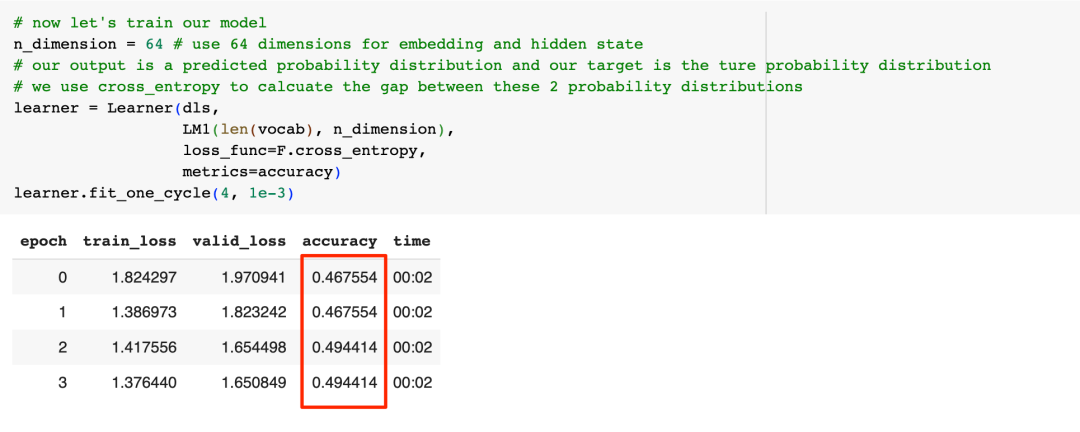
可以看到,经过4轮训练后,我们模型的准确率是49%,这个结果到底好不好呢?瞎蒙是不是也可能准确率不低呢?
如果我们瞎蒙的话,最靠谱的方法就是把验证语料中所有的目标词都取出来,然后找到出现频率最高的那个词,然后每次都输出这个词,让我们看看这种瞎蒙策略的准确率:

可以看到,目标词中出现频率最高的是"thousand",占比为15.17%,而我们模型的准确率是49%,看起来RNN网络确实还是有一定效果的。
为了说明问题,我们第一版的RNN实现有不少重复的代码,现在让我们重构一下,让代码看起来更加RNN风格一些,回忆一下,一个卷起来的RNN网络是这样的:
所以我们的代码也可以是这样的:

再次训练看看效果:
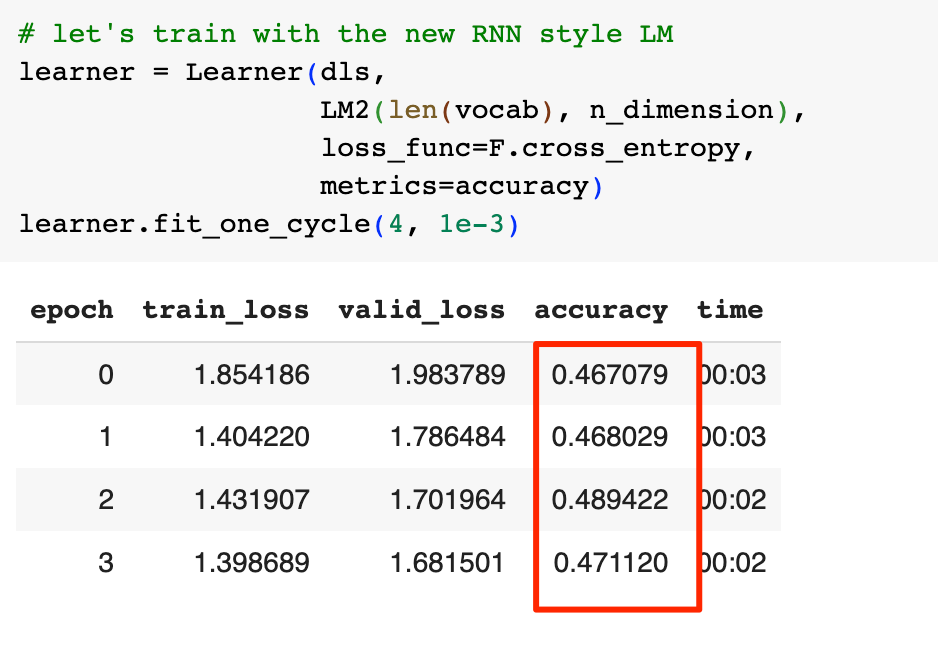
准确率略有下降,在神经网络的训练中,由于一些随机因素,结果略有波动是正常的。
优化我们的RNN模型
虽然RNN的效果比瞎猜要好,但是不到50%的准确率依然不能说优秀,这样的一个准确率在实际业务中也肯定是没法落地的,那么我们有什么办法进一步优化模型呢?
仔细看LM2的代码就会发现,每次处理完一个序列的3个token我们就会把Hidden State清零,仔细想想,这不就是个N=3的N-gram吗?我们做预测时的上下文太短了,更好的做法是,让我们的Hidden State能跨序列传递,这样当我们做预测时,就可以有更长的上下文了。
实现方式也很简单,只需要把Hidden State的初始化挪到类的构造函数就可以了,需要注意的是,在训练模型计算梯度时,如果Hidden State跨越了太多的序列,梯度的计算会很缓慢而且还会耗费大量的内存,我们可以在处理完一个序列后,通过detach只保留最后3个RNN节点的梯度,同时这并不影响跨序列传递Hidden State,具体代码如下:

接下来,我们是不是就可以开始训练模型了呢?看过上一篇文章的同学,可能会很犀利地指出,既然我们现在跨序列保持了Hidden State,那么保持序列的顺序就很重要了。(能想到这个问题的同学,我要给你点赞)
序列顺序的问题,简单说是因为,为了提高计算效率,我们训练模型时总是一批一批地消化训练数据的,而这些数据是被并行处理的,这种并行会打乱文本的原始顺序,我们的解决办法是提前把序列按一定规则重新排列,这样负负得正,最终并行处理时文本的顺序得以保持。在上篇文章中,我对此有详细介绍,这里就不展开了。
重排文本序列的代码如下:

我们用group_chunks函数实现重排功能,然后创建一个新的数据加载器,现在我们可以开始训练改进后的模型了:
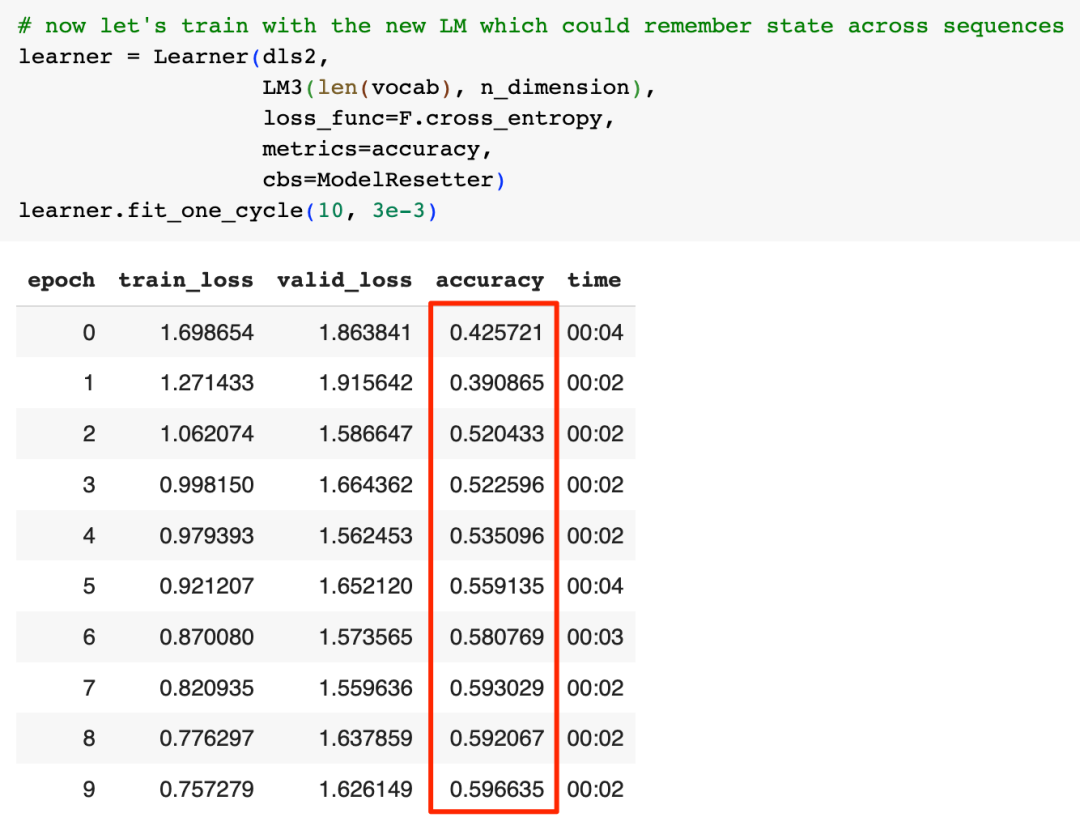
我们的准确率从接近50%提高到了接近60%,看起来更长的上下文确实是有帮助的,但60%的准确率实际也不够好。
进一步优化我们的RNN模型
我们有什么办法进一步优化模型呢?回想一下我们自己学习新知识的时候,如果得到的反馈越多,我们往往学得更快更好,把同样的思路应用到我们的模型,现在是每3个单词做一次预测,如果我们每看到一个单词,就做一次预测,我们将得到3倍的反馈量,这对训练模型应该有帮助:

另外一个实现细节是,之前我们通过只保留最后3个RNN节点的梯度,避免了梯度计算过慢,消耗内存较多的问题,但3有点小,也许适当增加保留的梯度能更好地训练模型,同时不增加过多的资源消耗,所以这次,我们把序列长度增加到16。
由于我们改变了序列长度,并且在每个节点都要做一次预测,所以我们要重新组织一下训练数据:

要注意的是,现在模型输出的维度是[batch_size, seq_len, vocab_size],而我们验证集的维度是:[batch_size,seq_len],所以我们需要调整一下损失函数,把batch_size和seq_len这两个维度压扁到一维:

终于可以再次训练模型了:
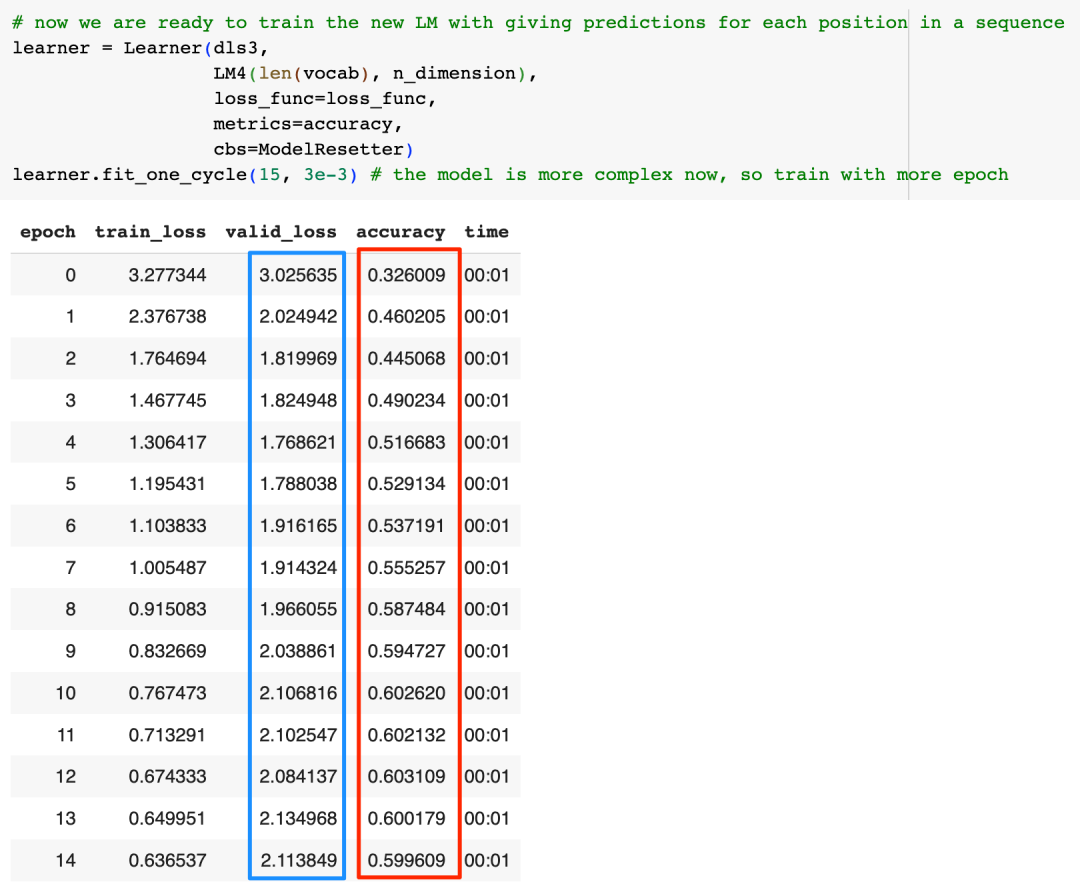
我们的准确率这次勉强维持在了60%,提升并不明显,更大的问题是,如果我们看一下valid_loss,可以看到这个loss明显地先下降后上升,这意味着我们可能出现了过拟合问题,为什么会这样?可能的原因是随着反馈增加,我们模型逐渐开始"死记硬背"了,模型的泛化能力开始下降。而模型效果提升不明显的原因则有可能是因为序列变长,模型训练时出现了梯度消失的问题(我将在下一篇文章中详细介绍这个问题)。
那么到底合适的序列长度应该是多少?深度学习是一个重实践的学科,大家可以自己动手试一试。但总体而言,更多的反馈会带来更好的学习效果这个思路应该还是对的,所以我们还是暂时保持目前的代码。
进一步优化我们的RNN模型
除了前面想到的这些改进模型的策略,我们还有没有其它方法呢?在神经网络中有一个常见的策略是,如果模型效果不好,那就再加一层,所以我们也来试试把两个RNN网络叠加在一起的效果,我们先画张图解释一下:
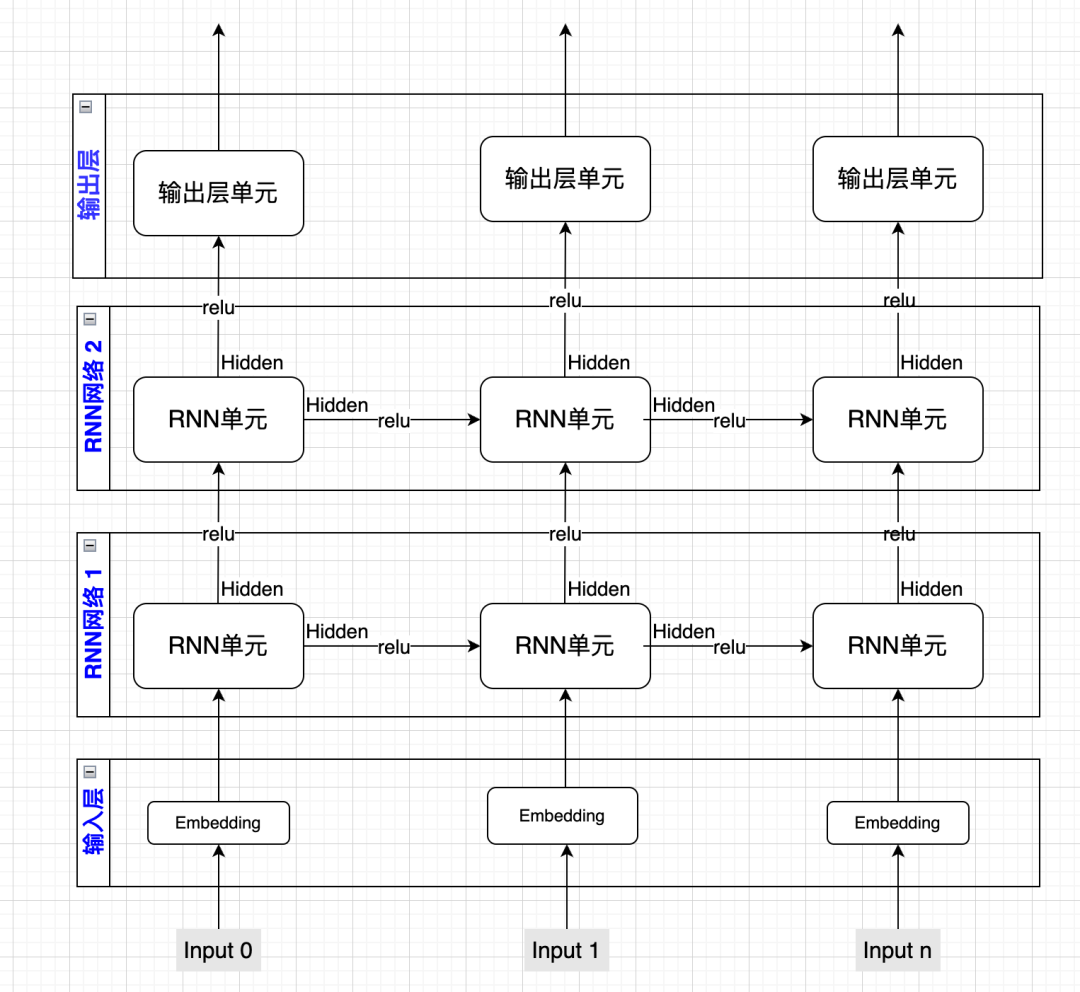
这里第一层的RNN网络和之前没有变化,第二层RNN网络的输入则为第一层RNN网络的输出,同时我们在序列的每个位置都做一次预测,由输出层输出,具体实现代码如下:

接着训练模型:
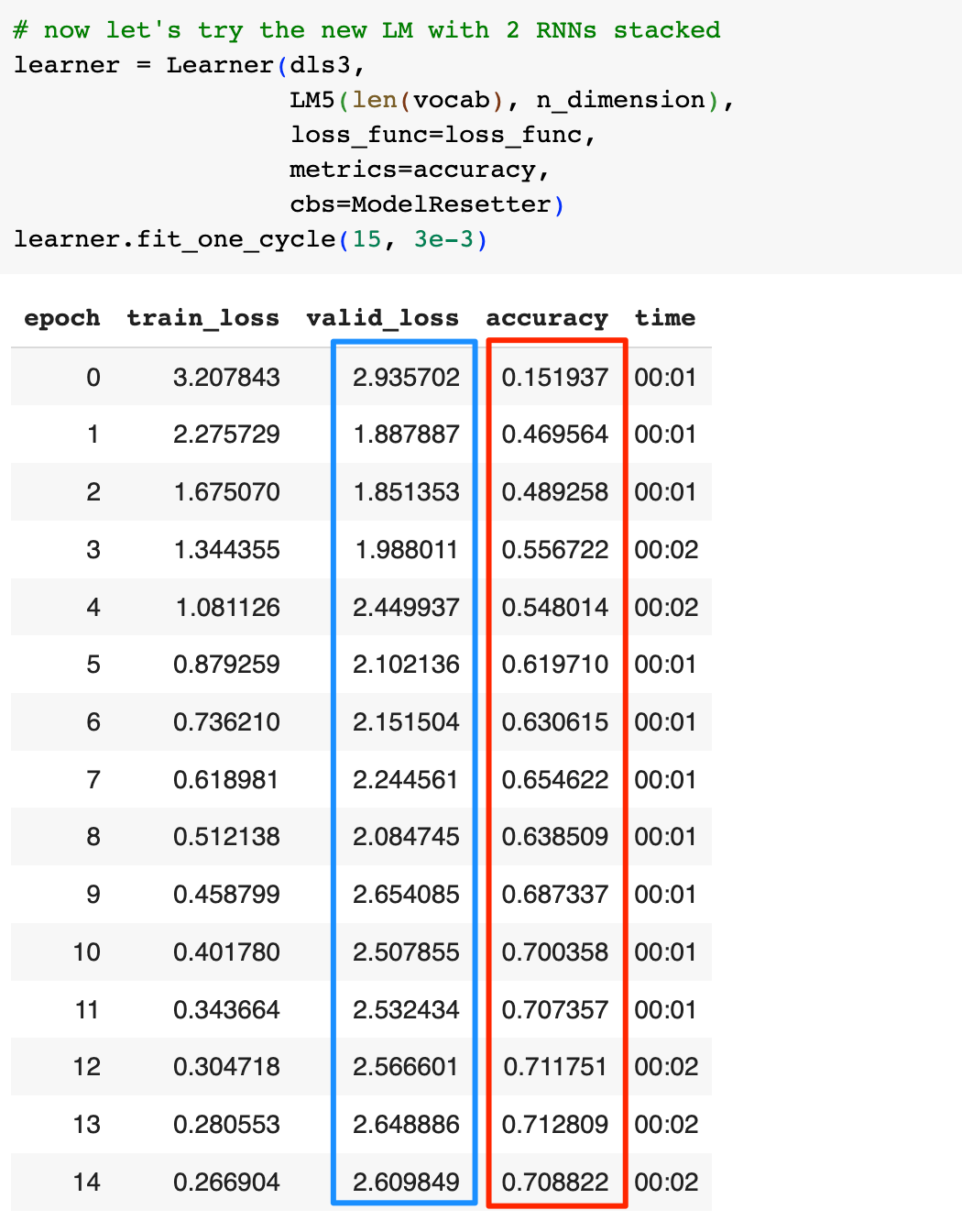
这次我们的准确率提升到了70%,但是观察valid_loss,我们能看到更明显的过拟合现象。我们增加了一层RNN网络,类似于给了模型更大的记忆空间,所以模型死记硬背的能力更强了,如果看一下valid_loss最低那一轮的准确率,实际上只有55%,这比之前的结果还要差一些,为什么会这样,我将在下一篇文章介绍。
上面是我们纯手工自己实现的RNN,我们可以用PyTorch类库提供的RNN库来简化代码:

然后看看效果:
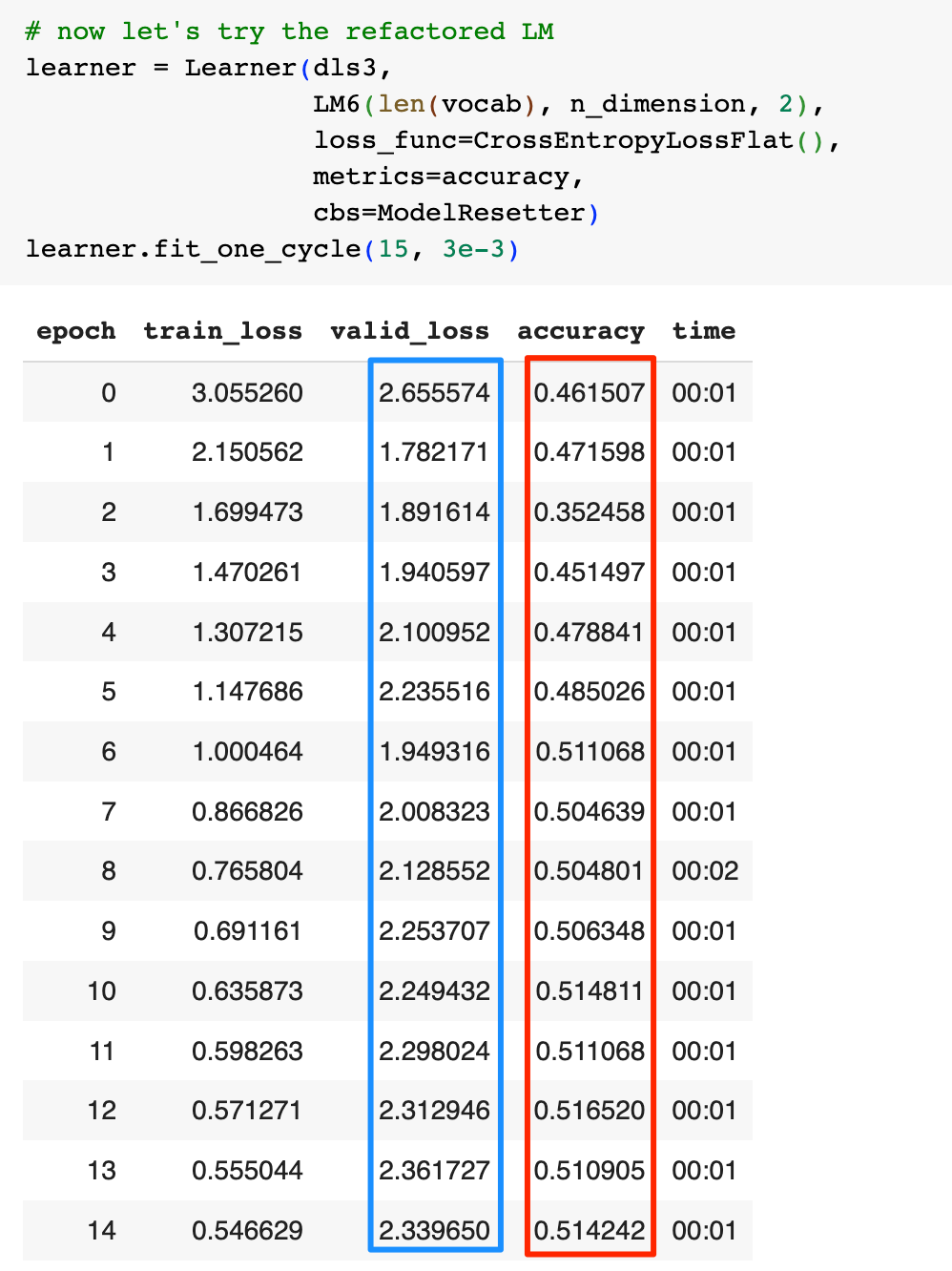
有可能是PyTorch的类库中做了一些处理,可以看到过拟合不那么明显了,但是模型的准确率也出现了大幅下降,我同样会在下一篇文章中介绍为什么看起来有效的策略并没有带来好的结果。
总结一下,我们首先介绍了RNN的背后的基本思路,相比于N-gram,RNN借助神经网络,可以通过更大的上下文来进行预测,接着我们又用代码从头打造了自己的纯手工RNN,并进行了一系列优化,这些优化措施使得RNN网络的层数变得越来越深,我们开始看到了过拟合现象,而优化的效果却并不明显。
本文就到此为止,我将在下一篇文章中讲解RNN的缺陷,并介绍一种改进型的RNN -- LSTM。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/GOrosX8g3tmQ8lWo1eLFLg Tag: 人工智能 ChatGPT 人工智能原理