前言
ChatGPT很强大,但要在业务中真正落地却并不便宜。如果你的业务已经越过了Demo阶段,有了稳定的用户群,那么OpenAI API的调用成本将吃掉你很大一块利润空间,如果出于业务考虑,你需要一个微调一个专属模型,那么成本将会更高。如果为了降低成本从开源入手,目前完全可商用的大模型并不多,而且其训练、部署、运维的复杂性和成本也都不低。
实际上,在处理很多具体业务问题时,我们并不需要一个像ChatGPT这么强大的模型就能很好地解决问题。比如,假设你在业务中能收到很多用户反馈,你想把用户的吐槽都筛选出来,以便改进业务,这就是一种不需要ChatGPT这么强大的语言模型就能处理的很好的问题。
之前我在《从N-gram到GPT,AI语言模型的成长之路》一文中,介绍过ChatGPT是基于Transformer架构实现的,而在Transformer之前,最流行的自然语言处理架构是RNN,本文就和大家一起看看如何用几行代码、免费的GPU、几十分钟训练一个基于RNN架构的专属模型以解决文本分类的问题。之后,我们还将一起看看解决这类问题的一般过程,以及如何进一步提升模型的表现。
快速拥有我们的专属模型
首先,我们需要先准备好开发环境,代码如下(本文介绍主要基于fast.ai API):

大家都知道IMDB上有很多影评,接下来我们就用几行简单的代码来训练一个自己的模型,然后用这个模型来判断一条影评是不是在吐槽:
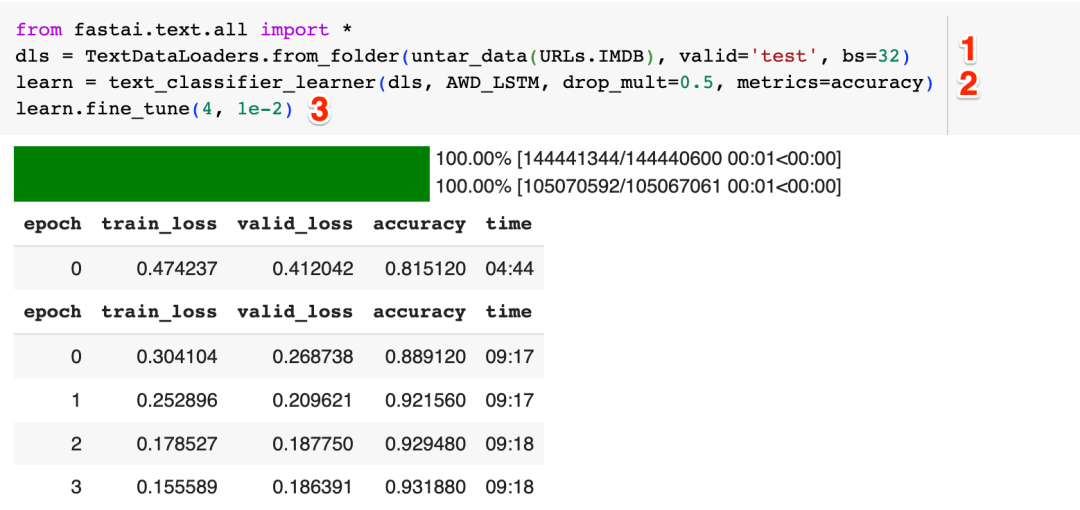
上图中的标注"1"的这行代码负责加载IMDB上的影评数据,标注为"2"的这行代码创建了一个基于AWD_LSTM(RNN的一种实现)架构的模型,标注为"3"的这行代码则对模型进行训练,在Colab上免费的T4 GPU上训练了大约40分钟后,我们的模型训练完成。
我们来看看效果:

下面是对美剧《巫师》第三季的一条评论:

让我们的模型来判断一下这是不是在吐槽:
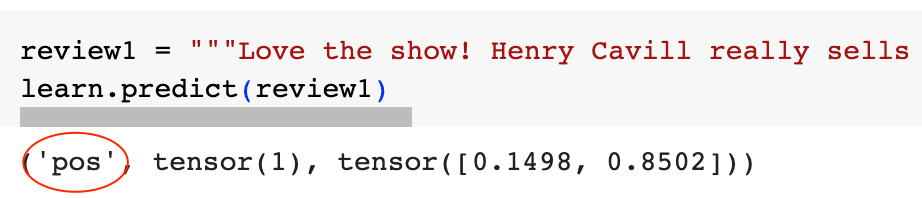
可以看到模型正确地判断出这是一条正向评论。
我们再来试一条负面评论:


可以看到,模型准确地判断出了这条影评在吐槽。
魔法的背后
通过几行简单的代码,我们就得到了一个自己的专属模型,那么这几行代码背后到底发生了什么呢?
实际上我们并没有完全从头训练一个RNN模型,感谢fast.ai,它已经帮我们封装好了一个用Wikipedia的数据初步训练好的模型,当我们在代码中创建模型的时候,fast.ai就把这个预训练好的模型下载到本地,然后以此为基础,进一步训练成为了我们的专属模型。
在上面的例子中我们通过一行代码就完成了模型的训练,但这个训练过程背后又到底发生了什么? 如果我们在业务中需要深入到模型的训练过程,其中又有哪些需要注意的地方呢?
如前所述,我们的专属模型是基于一个预训练模型得到的,而这个预训练模型是用Wikipedia上的数据进行训练的,我们都知道,影评中会大量地提到影片、导演、演员等,同时影评的风格也不会像Wikipedia那么正式和严肃,所以,如果能让这个预训练模型首先熟悉一下IMDB的风格,然后再去训练它来对影评分类,效果应该更好:
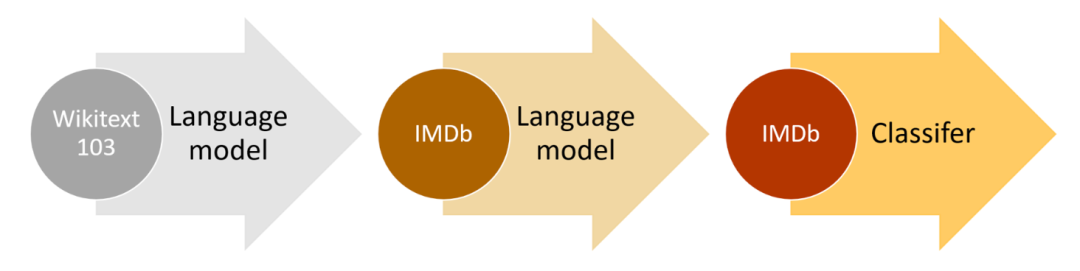
接下来,我们就来实现这一工作过程,并在这一过程中回答上面的问题。
把影评变成Token
就如同我们人类会把句子分解为单词一样,RNN模型要消化一个影评,也需要首先把影评分解为可消化的单元 -- Token。我在"拆解Token:深入了解ChatGPT背后的构建单元"一问中对Token进行了深入的介绍,这里我们直接动手实践。
方法1:直接按单词拆解Token
把影评Token化最简单的方法就是直接把句子拆解为单词,首先我们还是先加载IMDB影评数据:

这个数据集下有很多文件夹,影评主要在"train", "test", "unsup"这三个文件夹下,我们先随便取一条影评看看:

接着我们用拆解句子为单词的方式,来把这条影评token化:
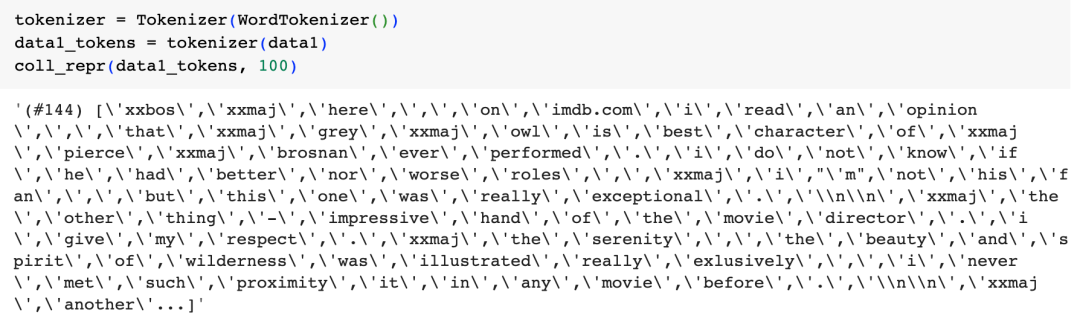
可以看到除了句子中的单词外,还出现了一些特殊的token,如"xxbos"(表示句子的开始)、"xxmaj"(表示下一个单词首字母大写)等,我们知道句子开始、首字母大写等在语义都有其意义,所以这里我们通过一些特殊的Token来把这些信息传递给语言模型。
直接按单词拆解Token的一个弊端是我们的词表会变得非常大,以Wikipedia为例,Wikipedia上所有的文本都拆解为单词并去重后,我们的词表会有几十万个单词,而过大的词表会极大地增加模型的训练成本。
按单词拆解Token的另一个弊端是,有很多语言(比如中文),字和字之间并不会像英文单词一样有个空格来分隔,所以这种情况下,按单词拆解Token就不可行了。
方法2:按子单词(Subword)拆解Token
拆解Token的另一个方法就是从训练文本中统计出概率最高的N个单词或子单词做词表,然后用这个词表来拆解文本。
我们以前2000条影评为例:

把词表大少设定为1,000:

然后创建我们的Tokenizer

接着来看看把第一条影评Token化的效果:

可以看到由于词表设定的较小,很多正常的单词都别切碎了,我们再来看看把词表增大10倍,大小设定为10,000的效果:

可以看到,这次很多单词都保持了正常,同时像"browsing"这个词则被拆分成了"brow", "s", "ing"这三个字词。
在实践中,我们一般会选择一个大小适中的词表大小。词表如果比较小,则需要很多token才能表达一个句子,而且有可能一些有意义的单词会被切碎从而失去了其语义。如果词表比较大,则只需要较少的token就能表达一个句子,但词表太大,模型的训练成本也会比较高。
把影评Token数字化
RNN是神经网络的一种,我们都知道神经网络的输入、输出都是数字,因此我们需要把拆解出来的Token进一步变成数字。
这一工作过程很简单,我们把一个Token集合中的所有Token去重,然后用Token在集合的下标作为其对应的数字即可。
为了便于说明,我们使用前200条影评为例子,直接用单词拆解Token:

然后创建数字转换器:

接下来看看Token数字化的结果:
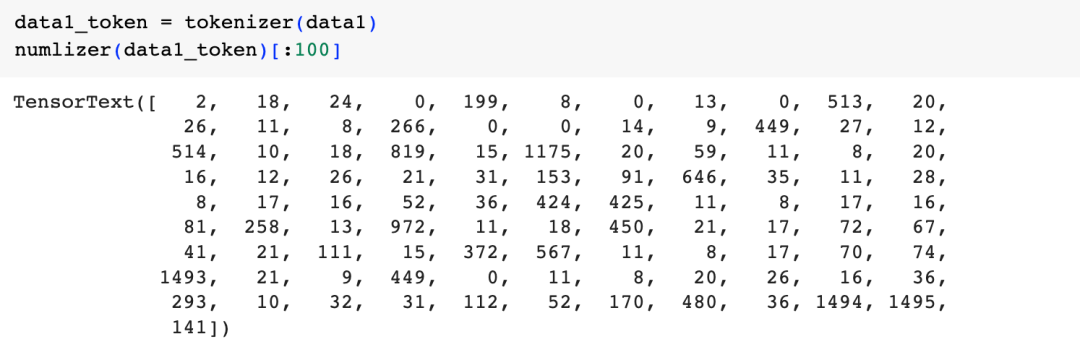
可以看到最初的影评已经被转化一个数字张量了。
把训练数据分成小的批次
我们都知道神经网络的训练过程中需要大量的计算,为了提高计算效率,我们会借助GPU进行并行计算,因此我们在训练模型的时候,会把训练数据分成若干个批次(batch),每次给模型输入一个批次的数据,假设一个批次中有64条数据(batch_size),那么这64条数据就会被并行处理,然后再处理下一个批次的64条数据。
作为一个简化的例子,假设我们有如下token化的一段文字:

这段文字一共有90个Token,假设我们想让模型每次并行处理6条数据(batch_size = 6),那么我们可以把这90个Token切分为6个长度为15的序列(sequence length = 15):

但GPU往往内存有限,一个序列太长GPU消化不了(GPU实际消化15个Token没问题,这里为了说明问题进行了简化),所以我们需要把这6个序列再竖着切分一下,假设sequence length为5,其切分效果如下:
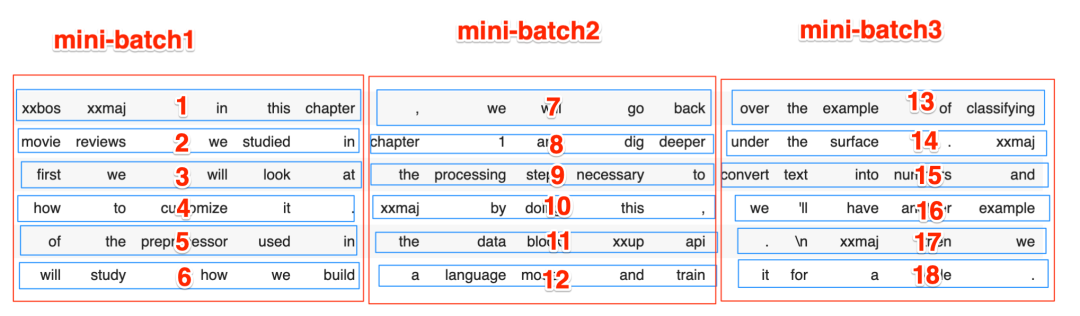
我们处理文本任务的时候,保持单词的顺序很重要,在切分成上图的3个批次后,模型首先会并行处理[1, 2, 3, 4, 5, 6]这6个文本序列,然后是[7, 8, 9, 10, 11, 12]这6个文本序列,最后是[13, 14, 15, 16, 17, 18]这6个序列。因为这些序列是被并行处理的,所以当1这个序列处理完后,紧接着的序列是7,然后是13,文本的顺序被保留。
但模型是在数据集上按顺序来切分批次的,如果不做处理则切分出的三个批次为[1, 7, 13, 2, 8, 14], [3, 9, 15, 4, 10, 16], [5, 11, 17, 6, 12, 18],当这些数据被并行处理的时候,1这个序列处理完后,接着被处理的序列是3,5,文本的顺序被完全打乱了。
所以当我们把影评交给模型进行训练前,我们需要先调整一下原始文本的顺序,把上图中原始的1, 7, 13...18这样的顺序调整为1,2,3...18这样的顺序,从而保证模型在训练时能保持文本的原始顺序。
保持文本顺序是训练语言模型时的一个关键,幸运的是,我们不用自己去实现这个繁琐的细节,fast.ai提供了的类库能自动帮我们解决这个问题。
在训练模型前,对训练数据进行Token化、数字化、批量化是三个重要的准备工作,下面我们就开始让预训练模型真正学习IMDB的语言。
精调预训练模型的一般过程
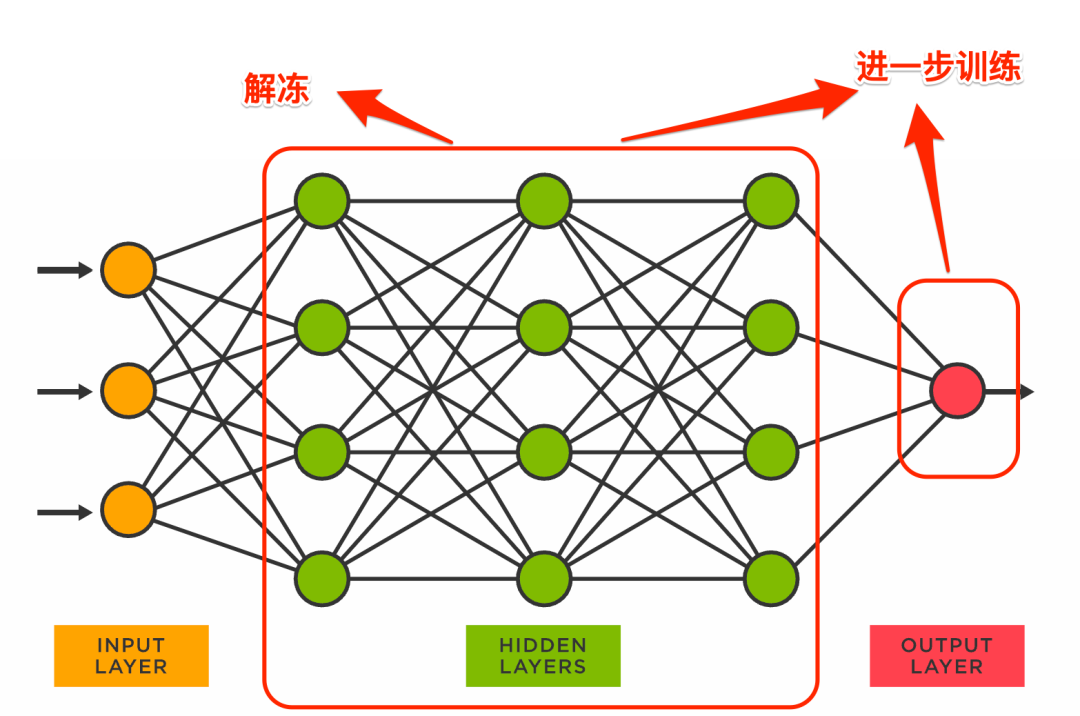
因为我们是在一个预训练模型上来进一步精调我们的专属模型的,所以我们需要了解一下这个过程,下图是一个典型的神经网络:
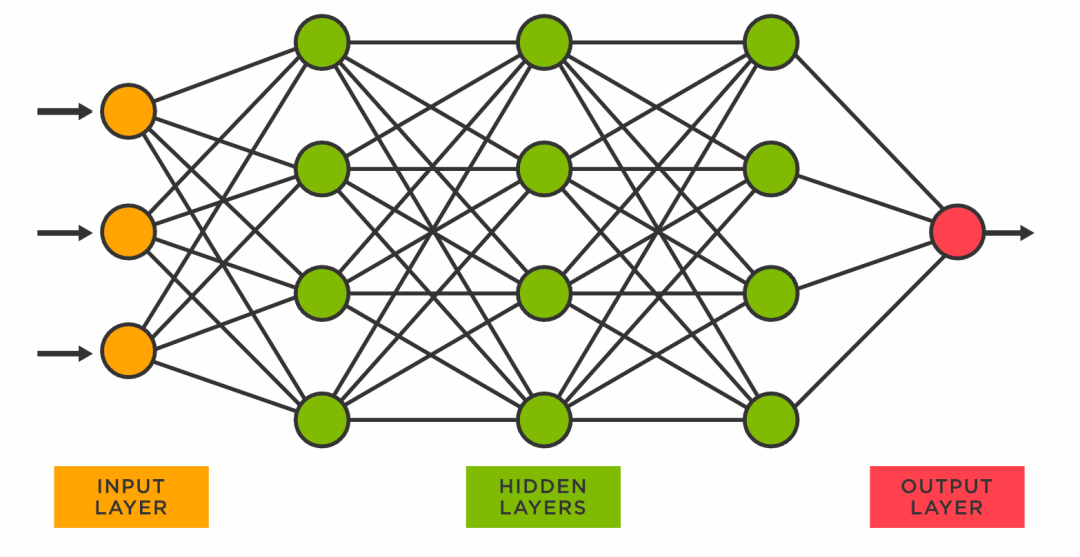
图中最后一层的output layer是和具体任务相关的,为了让一个预训练好的模型适应于我们自己的特定任务,我们一般会把最后一层替换为一个随机初始化的输出层,然后冻结所有其它层的参数,对模型进行第一轮训练:
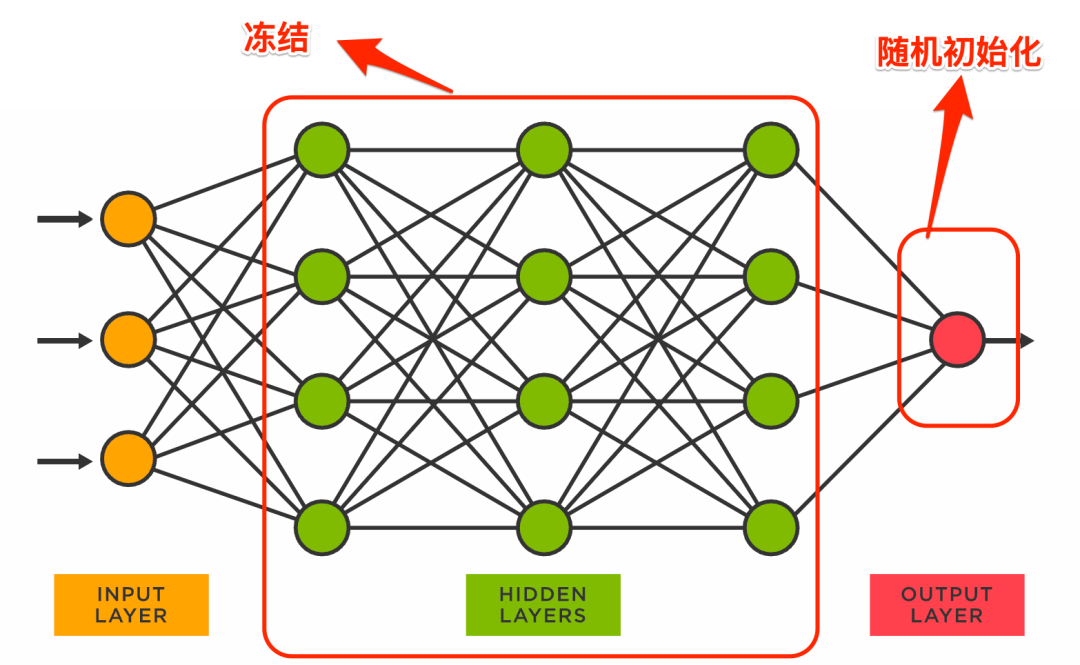
在这一轮训练完成后,我们再对之前冻结的中间层解冻,对模型进一步训练:
用影评数据精调预训练模型
首先还是准备数据加载器:

这里我们把batch_size设置为128,序列长度设置为64,fast.ai的TextBlock类则在幕后完成了上述的Token化、数字化、批量化这些工作。
为了让预训练模型学习IMDB影评的风格,我们训练模型从影评前面的单词预测影评的下一个单词,模型在不断预测影评下一个单词的过程中,将逐渐适应IMDB的影评风格。比如“I have watched the Witcher 3”这句话,我们希望模型看到“I”则预测输出"have", 看到“I have"则预测输出"watched",如果我们的输入为"I have watched the Witcher",我们期望的输出连起来则为"have watched the Witcher 3",也就是和输入偏移一个单词。
我们用fast.ai的language_model_learner来帮我们训练模型:
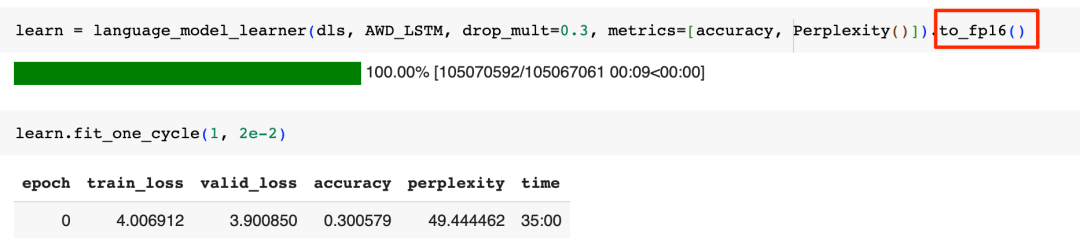
一个要注意的细节是,神经网络在计算中大量使用了浮点数,这里通过设定16位精度,可以在基本不影响训练效果的前提下,极大地节省训练所需要的内存。
上面这一轮训练完成了对随机初始化的输出层的训练,现在让我们解冻模型其它层的参数,对模型进行10轮更多的训练:

经过漫长的等待训练完成(我使用的是Colab入门级的T4 GPU,速度很慢),现在让我们看看效果,我们给出"I liked this movie because"这个前缀,让模型来瞎编一个影评:

看起来很有IMDB影评的味道了。
上面的训练过程花了很长时间,我们先把我们的模型保存下来,因为我们的最终目的是训练一个影评分类器,所以我们需要把模型的最后一层切掉,这叫做一个encoder:

用精调后的预训练模型对影评分类
首先还是准备训练数据:

这段代码和之前训练模型学习IMDB影评风格时准备数据的代码很像,但有几个关键的区别:
- 在之前的训练中我们创建的DataLoader叫做dls,这里我们把dls的词表直接拿来使用
- 之前创建DataLoader的时候,我们使用了一个is_lm=True的参数,因为这次我们是要训练一个分类器,而不是要训练语言模型本身,所以我们把这个参数去掉了
- 因为要训练的是一个分类器,所以我们增加了一个CategoryBlock参数,并用parent_label函数来获取影评的分类(影评数据集中文件夹的名字就是分类名,parent_label函数直接读取文件夹名来获取影评分类)
接下来创建模型并加载之前保存的encoder:

然后冻结模型除了最后一层外的参数,对模型进行第一轮训练:
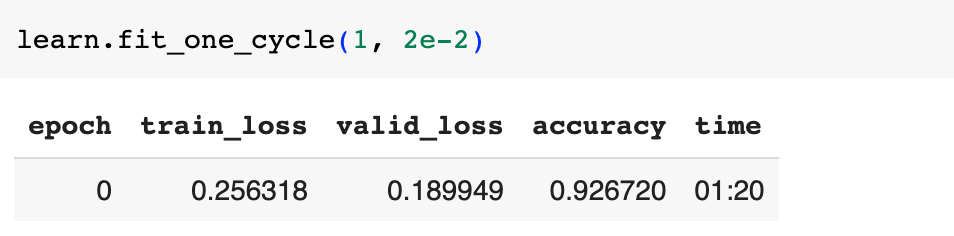
模型的准确率达到了92.67%,现在解冻模型的最后两层,再进行一轮训练:

准确率提高到了93.47%,接着解冻模型最后3层,训练一轮:

准确率提升到了94.11%,最后,解冻整个模型,训练两轮:

准确率进一步提升。
下图是本文开始时,没有让预训练模型学习IMDB语料,直接训练分类器时的效果:
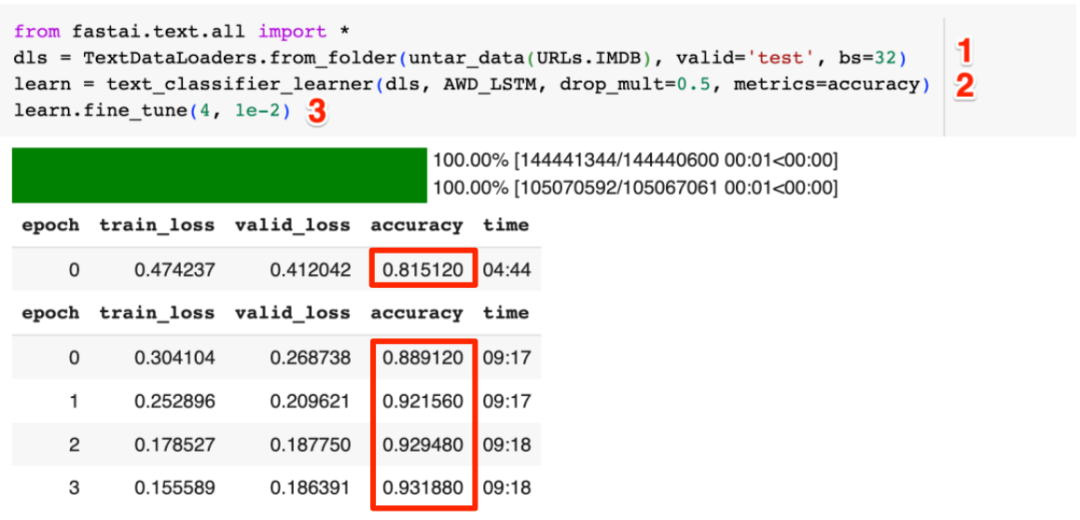
可以看到其前5轮训练后的准确率分别为: 81.51%, 88.91%, 92.16%, 92.95%和93.19%, 而学习IMDB语料后训练的模型,其5轮训练后的准确率分别为:92.67%, 93.47%, 94.11%, 94.29%和94.27%,对IMDB语料学习的效果还是很明显的。
总结一下,ChatGPT虽然很强大,但实际落地时成本也不低,实际很多业务问题可以用更简单的RNN来解决,通过借助预训练好的模型,我们用几行代码,极低的成本就能训练出我们自己的专属模型,而如果让模型学习我们的专属语料后再精调我们的专属模型,模型的表现会更好。在训练模型学习我们专属语料的时候,Token化、数字化、批量化(要注意保持文本的顺序)是3个必要的步骤。
本文比较集中在实操落地上,并没有对RNN本身进行深入介绍,俗话说要知其然更知其所以然,我将在下一篇文章中对RNN进行详细介绍。
最后,我想安利一下《Deep Learning for Coders with Fastai and PyTorch: AI Applications Without a PhD》这本书,本文的大多数内容实际上就是我的一部分学习笔记,这本书没有复杂的数学推导,它用大量实际的问题和代码,教我们一步步学会深度学习,感兴趣的同学可以在这里在线免费阅读:https://course.fast.ai/Resources/book.html

【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/Ik53FAVKEFWWOAXHbK3VDw Tag: 人工智能 ChatGPT 人工智能原理