这是本系列的第7篇文章,在这个系列中,我将尝试尽量用大白话的方式,来解释一些AI领域的基本概念,让更多像我一样的数学白痴也能理解AI。我相信不论AI背后的数学有多复杂,其基本思路一定是清晰的,可以用数学无关的方式讲清楚的。
OpenAI不Open,这导致ChatGPT的开源平替层出不穷(Alpaca, Vicuna, Dolly...),
我在之前的一篇文章也详细介绍了《如何用一杯奶茶的钱打造自己的专属ChatGPT》,各种开源平替、以及我自己的实践能够低成本实现的关键原因,在于一些优化技术能让训练成本大幅降低。
今天我就来介绍一下LoRA这个目前非常流行的优化技术。
LoRA是Low-Rank Adaption的简写,这个优化技术能让我们需要训练的参数降低近万倍,但训练效果却基本不受什么影响,以我自己训练Alpaca学会中文的例子,底层LLaMA 7B版要占用10多G的空间,而微调后的参数文件却只有60M+。接下来我们就详细看看LoRA为什么这么神奇。
Low-Rank是什么意思?
我们知道在模型的训练过程中要做大量的矩阵运算(别慌,我不会讲数学推导),我们可以把这些矩阵理解成训练对象(如文本对象)在高维空间中的表示,我们来先理解一下矩阵。
以人这个对象为例子,一个人可以有身高、体重、年龄、职业、性别等很多个维度的属性,这些属性中有些是相关的,比如根据一个人的身高 + 年龄 + 性别大致可以推算出他的体重,因此我们可以说体重不是一个人的根本属性,而一个人的职业则和身高、年龄等相关度很小,所以我们说职业是一个根本属性,一个对象根本属性的数量就叫做Rank,中文专业的说法叫做"秩"。
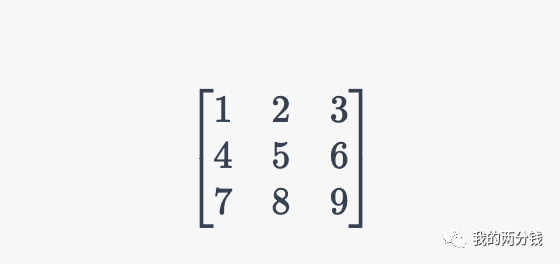
通过类比弄明白了Rank的含义,我们看一个具体的矩阵:
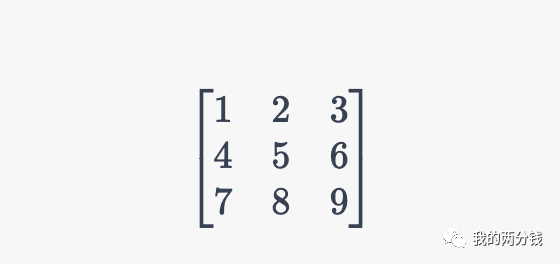
这个矩阵第3行的数字等于第2行的数字乘2再减去第1行的数字得到,假设矩阵的每一行代表一个属性,则第3个属性不是根本属性,所以这个矩阵的Rank为2。
如果一个矩阵本身很大,但是其Rank却很小,那么我们就说这个矩阵是一个Low-Rank矩阵。
大语言模型是不是Low-Rank的?
上面对Low-Rank的介绍提到,矩阵是训练对象在高维空间的表示,Rank是对象根本属性的数量,如果根本属性很少就叫Low-Rank,把这几点结合起来,估计大家已经可以看出端倪了:那就是如果虽然模型的参数很多,但模型的根本属性很少的话,那么我们通过只训练这些根本属性,就能大大降低训练成本。
那么LLM是不是Low-Rank的呢?幸运的是在2018和2020年已经有论文证明了这一点,这使得应用LoRA降低训练成本成为了可能。
具体如何应用LLM的Low-Rank这一特点来降低成本
为了方便说明,我们假设在训练中,一个权重矩阵是3 x 3的(这里做了极度简化,实际可能是3,000 x 3,000),其Rank为2,为了降低成本,我们训练时保持这个3 x 3的权重矩阵不变,转而训练一个 3x2的小矩阵,训练结束后,再把训练结果加回到原来的权重矩阵即可。
但熟悉矩阵的同学知道 3 x 3的矩阵和 3 x 2的矩阵是没法直接相加的,那么怎么办呢?我们知道一个 3 x 2的矩阵乘以一个2 x 3的矩阵,就可以得到一个3 x 3的矩阵,所以我们实际训练的时候就可以训练两个维度分别为 3 x 2和 2 x 3的矩阵,把他们相乘加回到最初的权重矩阵完成训练。

下图是来自论文中的原图介绍:
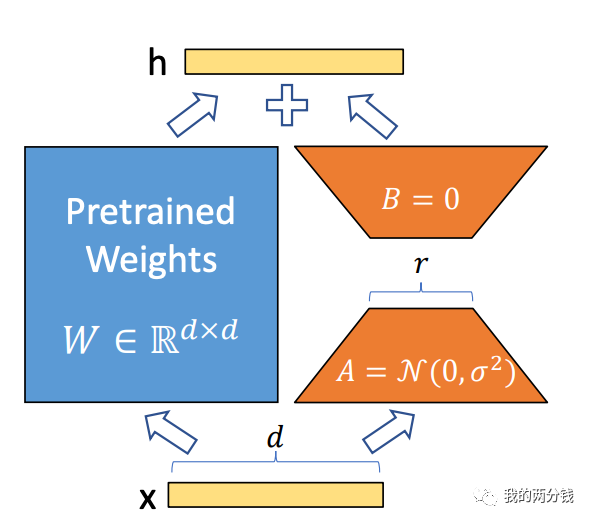
图中左边就是LLM的权重参数,右边就是要训练的两个小矩阵,图中的 r 就是权重矩阵的Rank.
有同学看了上面那个3 x 3矩阵训练的例子,可能会说这好像也没简单多少啊,这只是因为我做了简化,假设权重矩阵是3,000 x 3000的,那么其参数就有9,000K个,假设它的秩为8,那么一个 3000 x 8 加一个 8 x 3000矩阵的参数一共才48K个,可以看到需要训练的参数量大大减小了。
LoRA具体是如何应用到LLM的训练中的
在LLM的训练中,有大量的矩阵运算,理论上任何进行矩阵运算的地方都可以应用LoRA技术(所谓应用,可以理解为Adaption,这是LoRA中A的由来),我们先来看看ChatGPT这种大语言模型的架构,其背后使用的神经网络是Transformer架构,在Transformer架构中有一个注意力机制,用户的输入首先被向量化表示,然后被映射成Query, Key, Value三个矩阵,如下图所示:
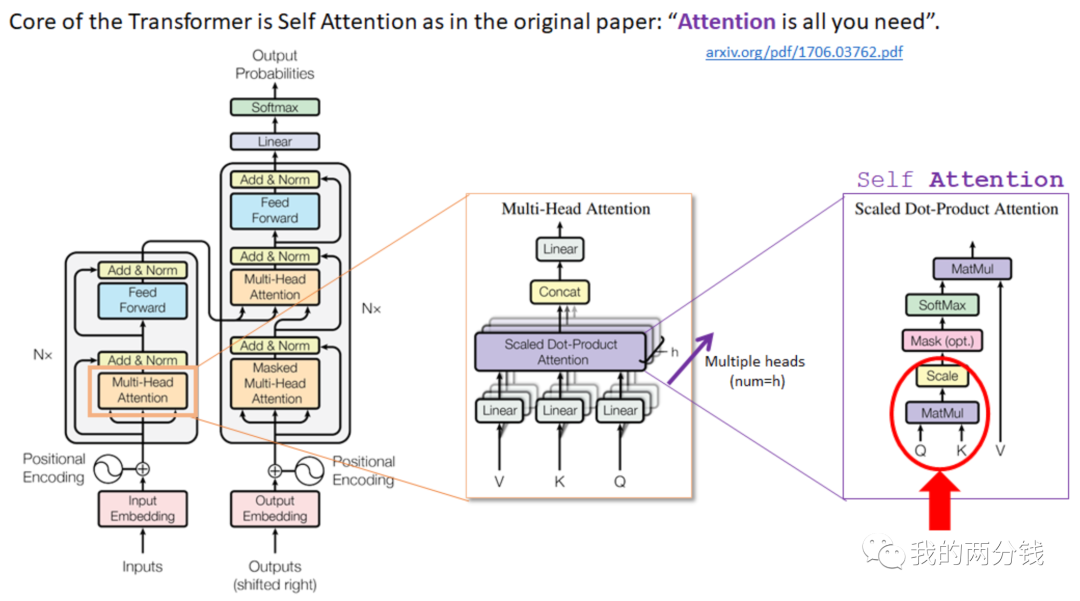
图比较复杂,但我们不用关注细节,只要知道在Transformer的注意力机制中,输入被映射到了Q, K, V这三个矩阵就好。
LoRA论文主要考虑的是Q,K,V以及注意力模块的输出矩阵W,通过试验得到的结论是,给定训练参数上限,Rank=4时,使用LoRA应用到Q, V比效果,Rank=2的时候,同时应用LoRA到Q,K,V,W比较好,如下图所示:
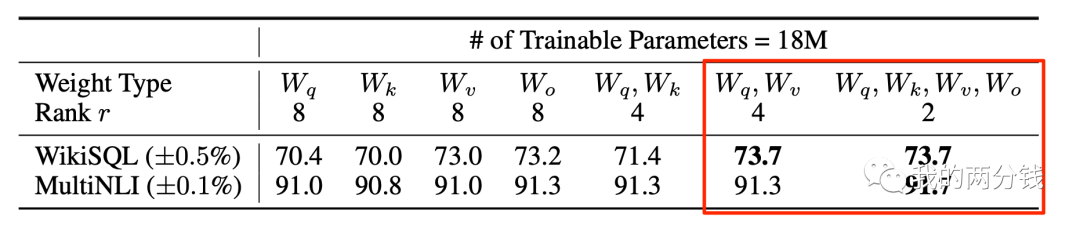
很多同学看到这里,可能会有疑问,那么大的权重矩阵,Rank的取值怎么可以这么低,论文也考虑了这一点,并尝试了更多的Rank取值,令人惊讶的是,较低的Rank取值训练效果就很好,增加Rank也并不能提高训练效果:
可以看到Rank取值为4或8就足够好了。
LoRA可以带来什么好处
首先最大的好处肯定是在不降低训练效果的前提下,训练成本大幅降低。
对比LoRA, 还有其它的两个优化流派,在锁住模型参数的前提下,一个是在LLM的Transformer架构中加入一层Adapter,由于网络层数的增加,推理性能会稍微变差一点;另一个流派(Prompt Tuning)是在Prompt中插入额外的向量,这会挤占有限的Context空间,同时其训练过程也并不稳定,而LoRA训练完成后把训练结果再加回到原始模型,这样模型大小保持不变,推理性能不受影响,而且训练过程也比较稳定。
LoRA还有一个优点是灵活性,如果您的业务场景比较复杂,需要针对不同的场景精调多个模型,那么您也可以选择只在推理时才把训练后的参数加回到原始模型,这样虽然会牺牲一点推理性能,但却能获得1个基础模型 + N个精调小模型的灵活性(每个小模型可能只有几十兆),您甚至可以在业务中根据场景动态切换模型。
以上就是对LoRA的大白话介绍,虽然在做应用的时候,我们并不直接涉及LoRA的技术细节,但知其然也知其所以然,我们才能走得更远,希望这篇介绍能帮您走得更远。
Tag: ChatGPT 人工智能