最近几周,Alpaca、Vicuna、 Dolly、 Koala、 Baize、GPT4All等ChatGPT的开源平替层出不穷,他们虽然各有特点,但大致都是基于某一个开源的大语言模型,通过一些专门的训练数据精调而成。

模型精调听起来有点吓人,像是只有专业选手才能干的事,但实际上如果你不追求数学推导,只是想做一些自己的应用的话,模型精调是一件很简单的事。
模型精调的另一个门槛是费用,就算是Alpaca这个把成本压倒极致的模型,准备数据和训练模型也一共花了600美刀,对普通人来说,这个成本还是有点高,好消息通过站在前人的肩膀上(薅羊毛),以及一些优化技术(LoRA)的加持,这个成本可以降到几块钱。
我之前写过一篇标题为《以小博大:Alpaca,您个人电脑上的ChatGPT》的文章,介绍了如何把Alpaca在本机跑起来,但原始版的Alpaca对中文支持不太好,下图是个例子

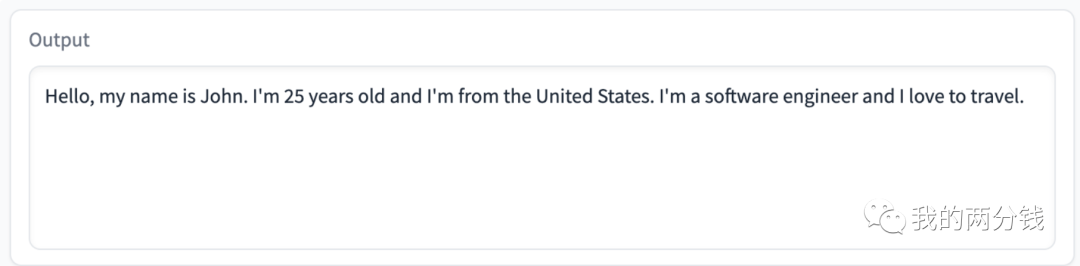
本文就以教会Alpaca中文为目标,详细展示用一杯奶茶的成本,如何一步步精调出一个定制的语言模型,了解了这个过程,当您在您的业务场景下需要定制模型的时候,就可以如法炮制了。
要教会Alpaca中文,第一步就是要准备中文的训练材料,这个材料最好要有足够的多样性、数据质量要足够好,同时数据量还不能太少。
方案1,最直接的思路是手工准备数据,但对我来说,手写几十条数据也许可以,手写成千上万的数据,还要保证多样性和质量,显然是个不可完成的任务,方案1 pass。
方案2,思路和Alpaca一样,利用Self-Instruct技术让ChatGPT帮我们生成数据(我之前有篇文章通过代码详解了这一技术),但在Alpaca的官方介绍中提到,他们在这块花了整整500美刀,这对我来说太贵了,方案2 pass。
方案3,既然Alpaca能薅ChatGPT的羊毛,那干脆我就直接薅Alpaca的羊毛,把Alpaca开源出来的52K的数据集翻译成中文就可以了。翻译有三个选择, DeepL、Google Translate、ChatGPT。
DeepL的翻译效果最好,但在亚洲只在日本和新加坡提供服务, pass。
Google翻译的价格是20美刀1百万字符,Alpaca的52K的数据大概有1,800万字符,算下来需要大约390刀,太贵,pass。
ChatGPT的价格是$0.002一千个token,一个token大约等于4个字符计算,Alpaca52K的数据1,800万字符,ChatGPT是输入输出双向收费,算下来大概要花大约20美刀,挠头...。
我还是不想花钱,我注意到Google翻译每个月可以免费翻译50万个字符,所以我想,也许教会Alpaca中文并不需要那么多训练数据,我干脆就用这个免费的额度来翻译好了,为了翻译尽可能多的训练数据,我把Alpaca的52K训练数据集按字符数从少到多排了个序,最后调用Google API翻译了5,000条训练数据,基本都是类似下图这样的小任务:

方案4,这个方案是我在调用Google API翻译完5,000条数据后想到的,我当时想也许有人也在和我做同样的事呢?于是简单一搜,发现早就有人调用ChatGPT把翻译这事干完了,并且把数据分享了出来,于是我就再次薅羊毛下载到了本地。
至此,数据的准备工作就完成了,很啰嗦地详细介绍了准备数据过程中的各种想法,目的是想以此为例子告诉大家,精调模型的过程中,实际准备数据是最麻烦的一个环节,教会Alpaca中文只是一个很简单的小目标,在实际项目中,任务往往要复杂很多,如何平衡好成本、质量、数据量是需要花巨大成本的,这个环节直接决定了项目的成败。
接下来,我们需要准备训练环境。
到目前为止,我们的花费为0,但是训练必须用到GPU,终于到了不得不花钱的环节,经人介绍,我选择了vast.ai (https://cloud.vast.ai/create/):
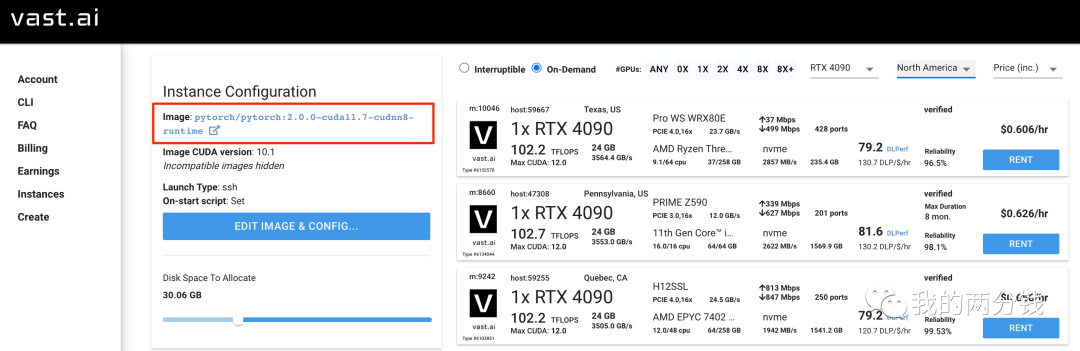
我选择了单卡4090,因为训练要用到GPU以及PyTorch, 这里我选择的Docker Image是"pytorch:2.0.0-cuda11.7-cudnn8-runtime", Alpaca的基础模型要占不少空间,所以我选择了30G硬盘,最后选择了远程SSH的方式登录机器:
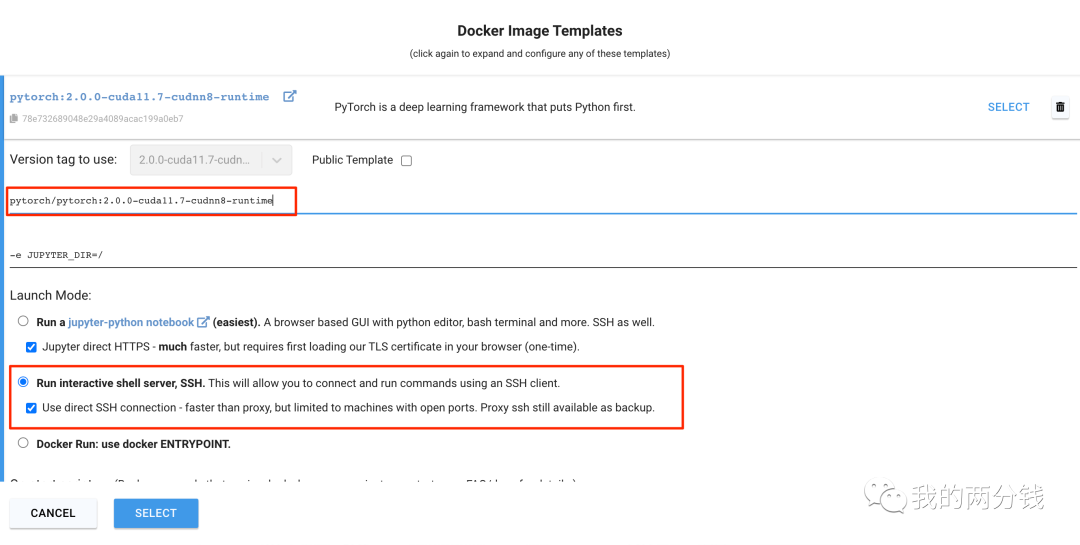
这里的价格是动态变化的,在我训练的时候,我幸运地找到了一台每小时0.4美刀的机器,选择好机器后点击"RENT",一两分钟后租用的机器就加载起来了,然后SSH登录机器,训练环境的准备工作就完成了(注意,此时计费就开始了,接下来操作手速要快,暂时不用机器的话,要及时Stop机器)。
数据和环境都Ready了,接下来就到了训练环节。
之前提到原始版的Alpaca训练环节花了大概100美刀,这个训练成本还是有点高,幸运的是有一种叫做LoRA的优化技术(我之后会写一篇文章详细介绍),可以大大减少需要训练的参数量,极大地降低训练成本,因此,我们就不从原始版的Alpaca开始训练了,我们从Alpaca-LoRA开始,命令行执行如下命令clone Alpaca-LoRA项目,并安装相关的第三方库:
git clone https://github.com/tloen/alpaca-lora.git
cd alpaca-lora
pip install -r requirements.txt
第三方库中有一个叫做“bitsandbytes”的库,有的环境下会有点问题,执行如下命令避免:
cp /opt/conda/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda117.so /opt/conda/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cpu.so
接下来上传训练数据到训练环境:
scp -P /your_data.json root@:alpaca-lora/your_data.json
训练脚本finetune.py在Alpaca-LoRA项目中已经准备好了,执行如下命令开始训练:
python finetune.py --base_model="decapoda-research/llama-7b-hf" \
--data-path="your_data.json" \
--num_epochs="2"
这里请保持base_model的名字为"decapoda-research/llama-7b-hf"不变,把"your_data.json"替换为你的数据文件,训练脚本默认是训练3轮,实际2轮训练就足够了,所以这里指定"num_epochs"参数为2,少一轮训练可以节约不少训练时间。
我在训练中使用的是数据准备方案4中的全量数据,整个训练时间大约是4个小时,可以看到其实在第一个epoch结束后就模型就训练的不错了(loss收敛),但是为了保证效果,我还是建议训练至少两个epoch.
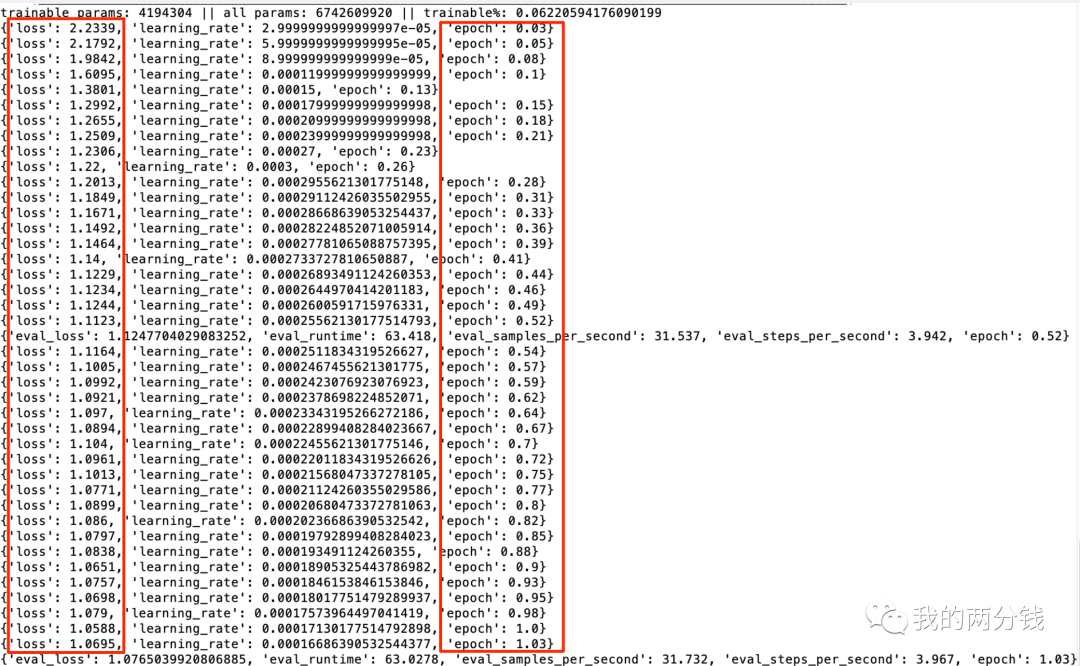
在喝了好多杯咖啡后训练终于完成了,因为租的Instance一销毁就啥也没有了,所以第一步是赶紧把训练好的模型下载到本地(只有60多兆):
apt-get install zip
zip -r alpaca_finetuned.zip lora-alpaca/
scp -P root@:alpaca-lora/alpaca_finetuned.zip ./alpaca_finetuned.zip
接下来就可以试一试Alpaca到底有没有学会中文了,Alpaca-LoRA项目里自带了一个generate.py,为了可以远程访问,找到如下这行代码(第195行):
queue().launch(server_name="0.0.0.0", share=share_gradio)
改成:
queue().launch(share=True)
然后执行如下脚本启动训练后的Alpaca:
python generate.py --base_model='decapoda-research/llama-7b-hf' --lora_weights="./lora-alpaca/" --load_8bit
命令行会打出远程访问地址,浏览器访问,再次请Alpaca自我介绍:

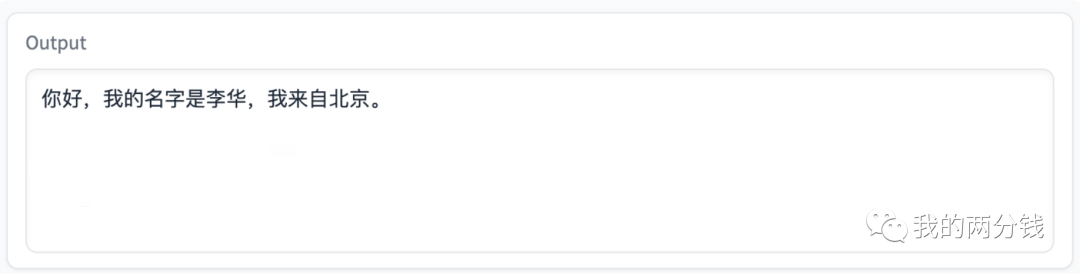
这次会用中文回答了,再问点简单的:

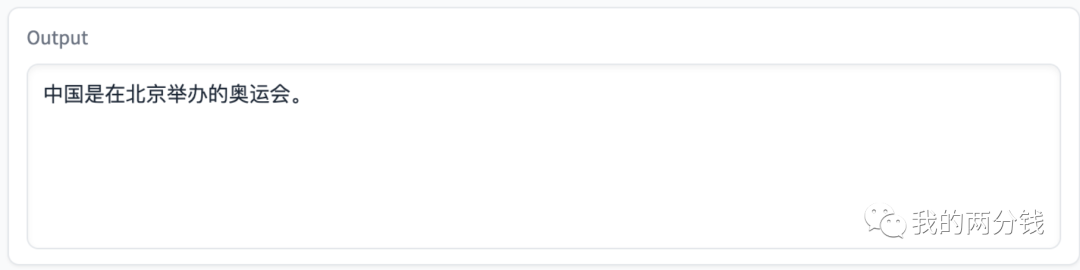
再问个稍微复杂点的:

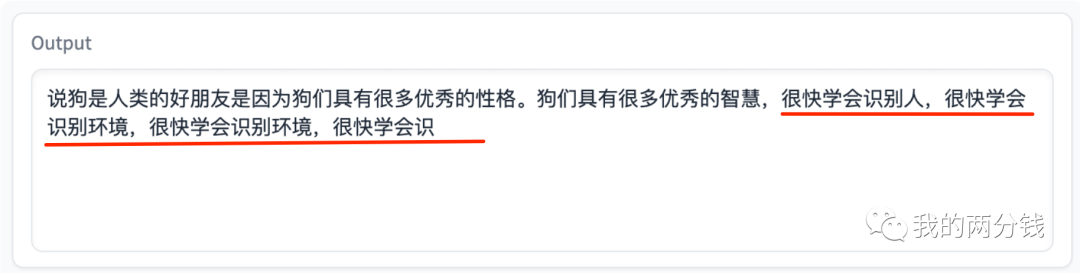
可以看到Alpaca已经有点不太行了,再试试更难的:

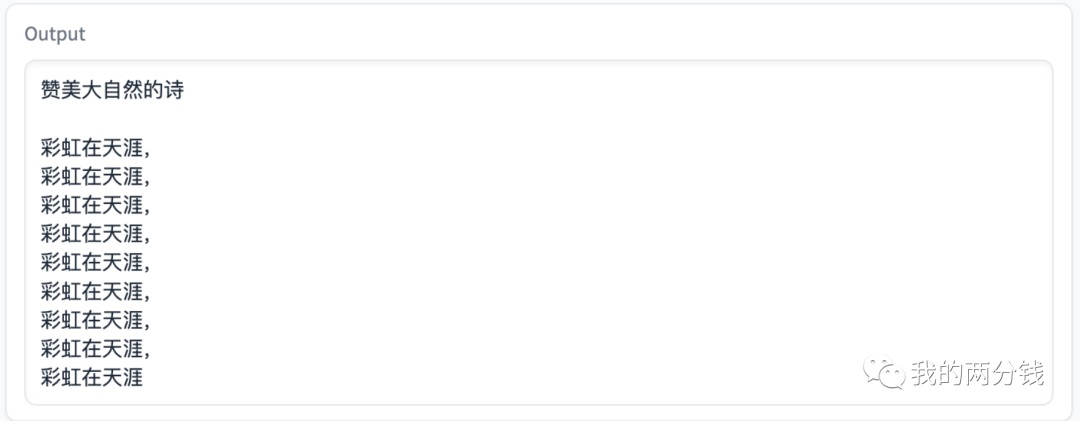
对比一下同样的问题在英文上的表现:

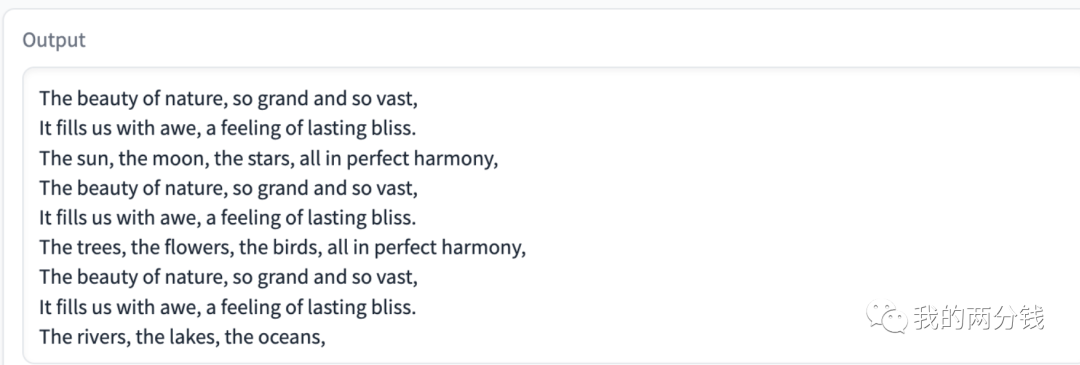
虽然英文回答也是有不少重复,但比中文明显好很多。这也可以理解,毕竟Alpaca底层LLaMA的训练语料中只有2%的中文数据。
至此,我们的训练和试验就完成了,在准备数据环节,我们的花费为0,在训练和最后的试验环节一共耗时大约5小时,共计花费不到3美刀,大约是一杯奶茶的钱。
以上就是一个低成本训练自己语言模型的全过程,在本文的例子中,训练目标比较简单,虽然实际业务场景中,业务目标的复杂性和对模型的质量要求会高很多,但其工作过程和训练Alpaca学习中文的过程是一样的,只要我们有数据,我们就能精调出我们自己的专属模型。
后记:
我也试了一下仅仅用数据准备方案3中的5,000条数据来训练,训练不到半个小时就结束了,我简单地试了一些提问,感觉效果并不比52K的全量训练效果差,也许还需要更多测试才能精确评估。
我还试着先下载Alpaca在英文训练数据集上精调完的模型,然后再在这个模型上用中文训练,训练了两个epoch耗时4个小时,loss一直没有收敛,也许这就像让一个人同时学会英语和中文一样,更大的难度需要更多的训练吧。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/rRS5-6g_8eYGLuKSUNddUw Tag: ChatGPT 人工智能