“知行合一”:大语言模型距离通用人工智能最欠缺的一步
近期 ChatGPT/GPT-4 系列产品引发全球关注和讨论,以其为代表的大模型在语言方面表现出了一定的通用性,使通用人工智能的概念浮出水面,进入了大众视野。
业界很多人认为大模型是通往通用人工智能的必经之路,然而大模型真的如业界所追捧的一样 “无所不能” 么?以 GPT-4 为代表的大语言模型究竟离通用人工智能还有多远?
北京通用人工智能研究院朱松纯教授团队最新发布了一份针对大模型的技术报告,系统回顾了现有使用标准化测试和能力基准对大型语言模型(LLMs)进行的评估,并指出了当前评估方法中存在的几个问题,这些问题往往会夸大 LLMs 的能力。报告进一步提出通用人工智能(AGI)应具备的四个特征:能够执行无限任务,自主生成新任务,由价值系统驱动,以及拥有反映真实世界的世界模型。
研究人员在技术报告中指出,“知行合一”(认识和行动的内在统一)是大模型目前所欠缺的机制,也是迈向通用人工智能的必经之路。研究人员认为,概念的学习依赖于与真实世界的交互,且知识的获取并不完全依赖于被动输入,在新环境中获取知识的关键途径更应该是主动探索和试错而非被动接受。

论文链接:https://arxiv.org/abs/2307.03762
一、大语言模型无异于缸中之脑
缸中之脑是由哲学家 Hilary Putnam 提出的一个著名思想实验,该实验假设人的大脑从身体剥离,放在一个能够维持其机能的营养液缸,由一个超级计算机联结大脑神经元制造出各种幻象,让人觉得一切正常,就像《黑客帝国》所演的那样,那我们该怎么知道自己不是缸中之脑呢?
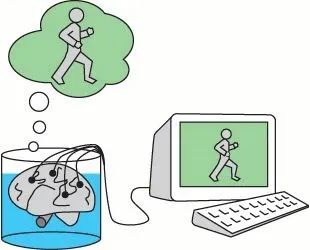
基于语义学的分析,Putnam 反驳道,当缸中大脑里的人声称自己是 “缸中之脑” 时,缸和脑的所指已经发生了变化。如何理解这一观点呢?举个简单的例子 —— 假设存在一个孪生地球,其居民和我们生活方式、语言均相同,但他们的 "水" 分子组成为 XYZ,与我们的 H2O 不同。尽管这两种 "水" 在外观、用途和名称上无异,且两地居民对 "水" 的心理感知相同,但指向的实质却不同,因此其含义也应有所区别。这也启发研究者从符号落地(symbol grounding)的视角看待大模型。论文认为,大模型无异于缸中之脑,因为大模型本身并不在真实世界中 (living in the world),它无法像人一样实现从” 词语 (word)“到” 世界 (world)“的联结。这一点是由它的内在构造机制所决定的 —— 通过统计建模在大量文本上进行训练,学习文本之间的语言学相关关系,从而根据上个词汇预测下个词汇。
缺乏符号落地使得大模型很容易陷入绕圈圈的境地。研究者尝试给 GPT-4 一个引子,让它跟自己对话,然而在有限回合之后,GPT 就开始重复自己说的话,无法跳脱当下的语义空间。

大模型的 “智能” 与其说是内在的,不如说是人类智能的投影。大模型生成的文本并不先天具有意义,其意义来自于人类用户对于文本的阐释。例如语言学家乔姆斯基曾经尝试挑战语言学界构造了一个符合语法规范但无意义的句子 ——“无色的绿思狂暴地沉睡”(“Colorless green ideas sleep furiously”),然而中国语言学之父赵元任在他的名文《从胡说中寻找意义》中给予了这个句子一个充满哲思的阐释。
二、大模型的局限性
大模型训练数据集的不透明以及人类评估时所采取的指标差异可能使得人类高估了大模型的真正表现。一方面,大模型的训练数据集通常是规模巨大且高度易得的互联网数据,这些训练数据可能会包含后续用于评估的数据集。由于当前我们并不知道 GPT-4 等大模型的训练数据集构成,泛化这一概念变得模糊,即我们无法判断大模型是真的学习到了核心概念,还是仅仅从它的训练产生的 “隐藏记忆” 中进行检索,这种不透明性阻碍了学术界对其公正和可靠的评估。另一方面,有研究发现大模型的涌现能力并非源于模型行为的本质变化,而是由于使用的评估指标导致大模型看起来突然变得很强大。简单地说,在使用非线性度量(如 X 的 n 次方)时,曲线上稀疏的采样点可能让人感觉到存在某种涌现现象,然而如果换成线性度量,这种现象就不存在了。
在回顾了数十篇大语言模型的评估研究后,研究人员发现:
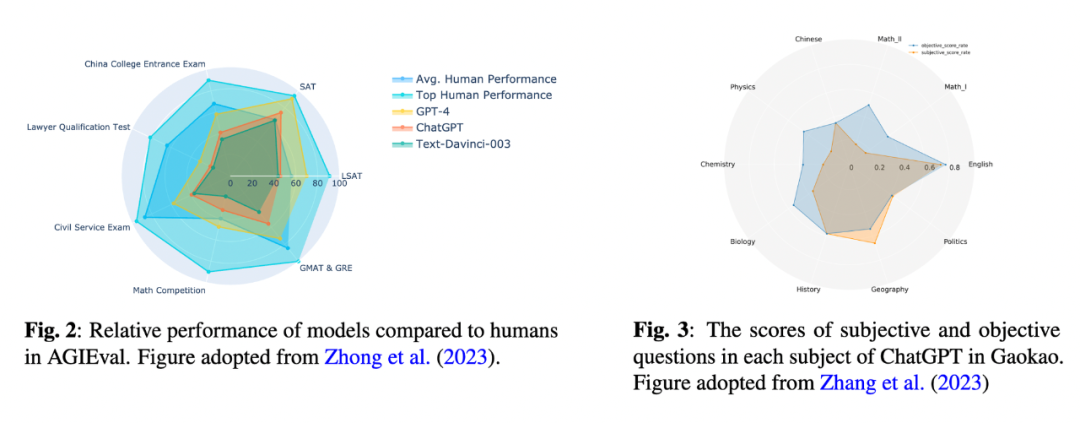
1)虽然某些研究声称大语言模型能够在标准化测试(SAT,LSAT)中取得超越普通人类考生的卓越成绩,但一旦引入非英语的其他语言同类型测试,比如中国高考、印度升学考试、越南高考时,GPT 的表现显著下降,且其在需要应用推理的考试(数学、物理等)的成绩显著低于强语言依赖学科(英文、历史)的考试。GPT 的表现看上去更像是采取了一种题海战术,通过重复的记忆来做题,而非习得了如何进行推理。
2) 大语言模型的数学推理能力仍然有待提高。Bubeck 等人(2023)在《Sparks of Artificial General Intelligence》这篇文章中采取了单个案例展示的方式尝试说明 GPT-4 能够解决 IMO 级别的问题,但研究者在仔细检视了 GPT 所提供的解决方案发现 Bubeck 等人的结论具有很强的误导性,因为测试的题目被极大程度地简化了,在让 GPT-4 解决 IMO 数学题原题时, GPT-4 的数学逻辑链条是完全错误的。另有研究发现,在 MATH 训练数据集上,即使把模型设置为 MathChat 的模式,其准确率也只有 40% 左右。
3)大语言模型的推理与其说是来自于理解逻辑关系,不如说是来自于大量文本的相关性。朱松纯团队的另一篇研究发现,一旦将自然语言替换为符号,大语言模型在归纳、演绎、溯因任务上表现骤降,无论是否使用思维链(thought of chain)的策略。
一个简单的例子如下图所示:图左用动物(熊、狗、牛等)生成了一系列陈述(比如 “熊喜欢狗”、“牛的属性是圆”、“如果某个动物的属性是圆,那么他们喜欢松鼠”),而后给 GPT-4 一个新的陈述(比如 “牛喜欢松鼠”)让其判断正确与否,研究者发现当把具有明确语义的词汇替换成抽象符号时,(比如用 e4 替代熊,e5 替代狗,e2 替代圆),大语言模型的表现将会显著下降。另一个对大模型的因果推断能力的研究揭露了相似的发现 —— 当将大模型的语义转化为符号时,大模型的表现将下降到几乎同随机回答无异,哪怕在微调之后,大模型也只能应对之前出现过的类似的符号表达,而无法泛化到新场景中。

4)大模型做不好抽象推理,当面对那些仅依赖于几个小样本演示从而找到潜在规律的任务时,大模型的表现较为一般。如下图所示,在瑞文测试数据集(RAVEN) 中,测试者需要根据已有的 8 个图形(形状、颜色、数量、大小)寻找暗含的规律,然后推理出最后一个图形。
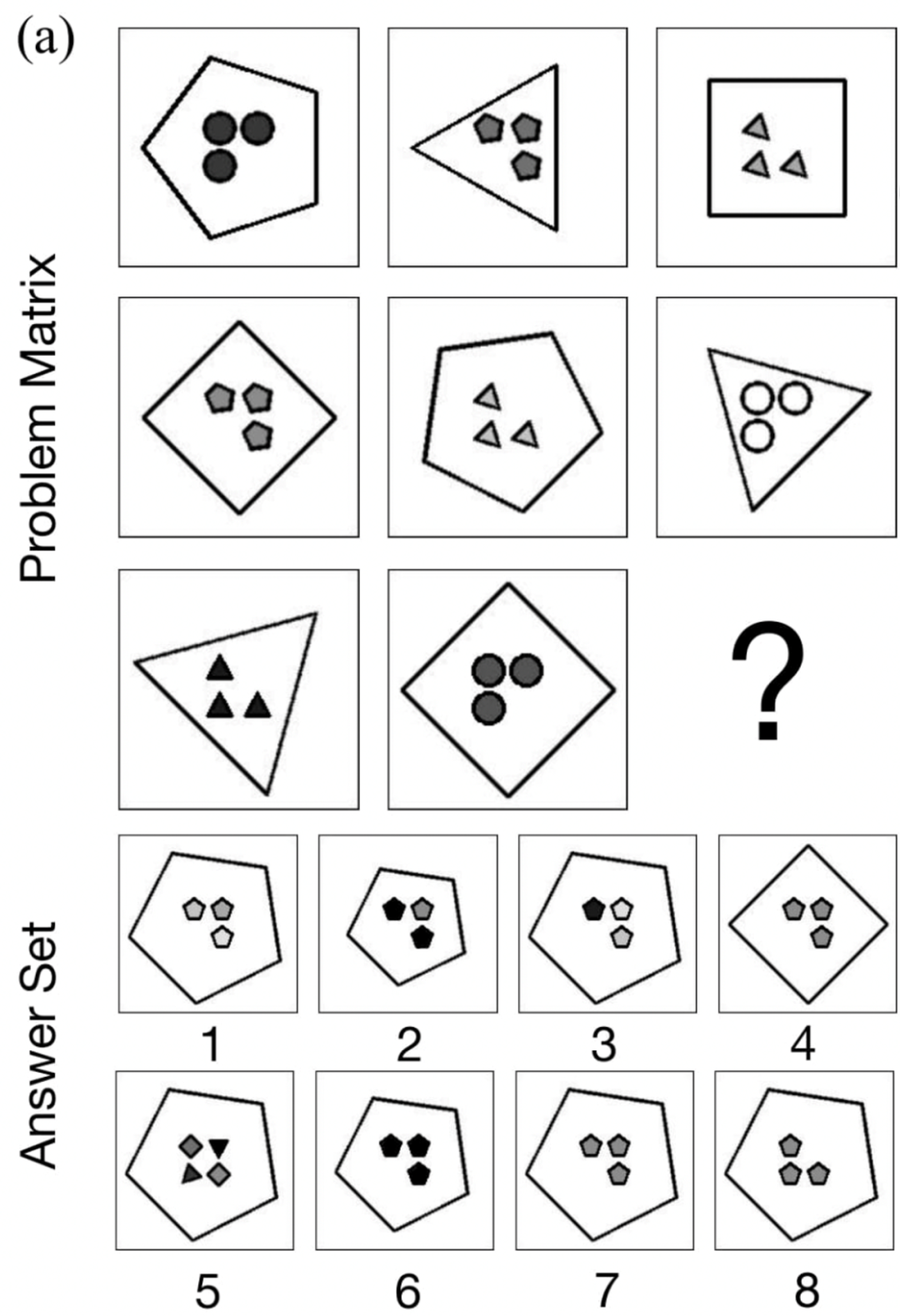
另外一个例子来自于 Evals-P 数据集,如下右图所示,大模型需要能够在缺少大量训练样本的前提下找到出现 foo 或者 bar 的规律,即当首字母包含在之后的字符串里时是 foo,不包含时为 bar。对于某些大模型,这些任务的准确率接近于 0,而哪怕 GPT-4 的准确率也只有 30% 左右。

三、关于通用人工智能的一种观点
判断 “某某某 AI” 是不是通用人工智能的一个前提是得清楚通用人工智能的定义或者基本特征,朱松纯团队尝试刻画出了通用人工智能(AGI)的四个特征:
1.能够执行无限的任务;
2.能够自主生成新任务;
3.由价值系统驱动;
4.拥有反映真实世界的世界模型。
首先,智能体应具备在物理和社会环境中完成无穷任务的能力。如果设定一个表示达到 AGI 的任务数量阈值,那么如何确定这个阈值将始终是一个值得质疑的问题。
如果智能体在完成 N 个任务后没有展现出通用智能,我们就没有理由相信它在完成第 N+1 个任务后会突然拥有通用智能。虽然一系列具体而具挑战性的任务清单对于评估智能体的性能有所帮助,类似于教师用学生的考试分数来评估他们的学习成绩,但仅仅完成具体任务并不等同于拥有通用智能,这就像不能仅凭学生的分数判断他们真正的学习能力一样。
此外,无穷任务并不意味着智能体需要像超人一样无所不能,而是指通用智能体应能够在特定环境中自主生成新的任务,这与学生学会自我学习相仿。
智能体生成新任务需要两个基本机制。首先,智能体需要一个驱动任务生成的引擎。例如,达尔文的进化论揭示出生存和繁衍这两个本能,它们被编码在我们的基因中,而人类的进化过程丰富了价值系统,出现了各种各样的细分价值,如利他主义、诚实和勇气等,每个人都受到一个由其与现实世界持续互动塑造的复杂价值系统的驱动。
同样的,我们可以应用这种价值系统的概念来构建通用智能体,在这种情况下,人类可以通过调整智能体的价值函数来影响其行为,而无需预先定义详细的任务步骤。其次,智能体需要一个包含真实世界中物理法则和社会规范的世界模型,来指导智能体和真实世界的交互。
这就像一个玩乐高,世界模型包含了各种积木(物体表征)以及积木之间的连接方式(物理法则和因果链等)。然而,价值函数在所有可能的选项中选择了一种蓝图,比如拼一个城堡,驱动智能体去执行任务,在乐高城堡搭建的过程中,智能体需要根据当前的进度,选择合适的积木并将其正确地放置在相应的位置(自我生成新任务)。
四、“知行合一”
王阳明曾说,知而不行,只是未知。为了解决符号落地并且诞生具有上述特征的通用人工智能,仅依赖于知识是远远不够的,整合知识和行动是必须的。此时,智能体不仅能够通过主动地行动来生成对于现实世界物体的更加完整的表征,比如整合了视觉、触觉、听觉等信号,更重要的是能够通过探索环境生成知识,并进一步泛化到新场景中。
其一,人对于世界的理解是建立在和真实世界交互中的。
符号(语言、数学符号等)只是概念的指针,只有多模态的交互信号才能真正建立概念表征。仅停留在文本空间上的大语言模型虽然能够生成符号,但无法实现理解符号所指向的概念。如同一个蚂蚁意外的行动轨迹构成了一个 “○”,但蚂蚁本身并不理解圆形意味着什么。
其二,知识并非是先天存在的,知识和行动之间有着内在的联系。
人类对世界的深刻理解并非来自于简单地阅读手册,而是通过自己亲身探索或者来自于他人探索的传递等反复的试错积累而来。在这里,知识体现了人与世界交互的能力(比如推理,问题解决,社会理解),但如果模型只是被动地接受知识并通过统计模型生成内容,无异于一个压缩了大量知识的百科全书,但却无法在新环境中通过探索世界进行新的知识生产( 包括知识抽象、知识积累和知识迁移等过程)。
五、总结
研究团队提出的大模型技术报告为接下来的人工智能研究提供了一些潜在的研究方向:
- 建立透明的评估机制和评估系统;
- 创造具有丰富可供性(大量交互可能性)的仿真环境;
- 探索一套 “知行合一” 的认知架构,从 “纯数据驱动” 的范式向 “任务驱动” 的范式转变。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/OUku0k2lRBix5ltREBkT8Q Tag: 人工智能