如今,Prompt是玩转各种大语言模型(LLM)的关键,Prompt工程师成了一个新兴职业,有公司甚至为此开出了百万年薪。之前我专门有两篇文章介绍了一些常见的Prompt技巧:
要写出好的Prompt入门虽然不然,但要成为大师则很不容易,这在一些垂直的业务领域更是如此,我们不但要有开阔的思路和创意,同时还需要对具体的业务有全面和深入的理解。
为了找到一个好的Prompt,有时候,我们常常要反反复复进行几十、上百遍修改才能找到理想的Prompt;还有些时候,即使进行了无数次的尝试,也总是找不到那个最优的Prompt。
当我们穷尽了所有的Prompt技巧却依然找不到答案时,我们还有什么办法?
Prompt Tuning就是对这一问题的答案。
本文将介绍Prompt Tuning的思路,并通过简单的代码为大家一步步演示其具体工作过程,并在最后简介这一方向几个类似的解法。
什么是Prompt Tuning
我们都知道LLM的能力很强,给出好的Prompt,它就能给出好的答案。那么我们能不能反过来,让LLM来帮我们来找到好的Prompt呢?这实际就是Prompt Tuning的基本思路。
正常使用LLM的过程是:
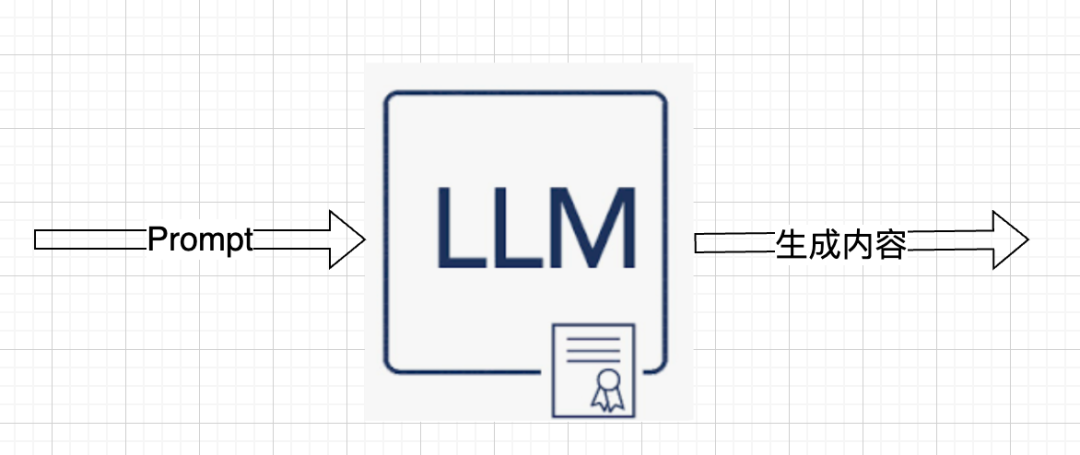
而Prompt Tuning的工作过程是:
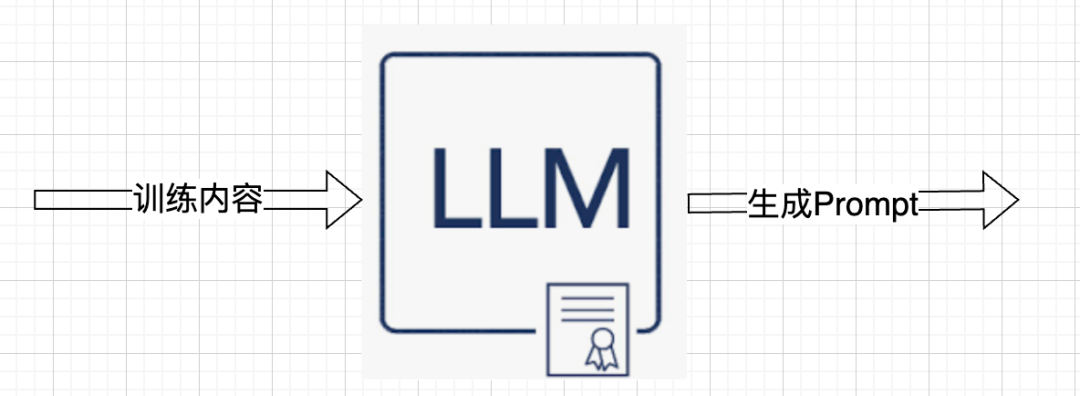
就像LLM本身的训练过程一样,Prompt Tuning首先给LLM一些例子,告诉LLM碰到什么问题,应该给出什么结果,LLM在看了一些这样的例子之后,就会返回一段Prompt(咒语),之后当我们真正向LLM提问的时候,把这段Prompt作为前缀,拼接在我们自己的Prompt上,就可以让LLM给出好的结果了。
举个例子,假设我们的任务是拿到一个tweet,判断用户是不是在吐槽(complaint, no complaint),我们首先给LLM看一些例子,
Tweet text : @nationalgridus I have no water and the bill is current and paid. Can you do something about this?
Label :complaint
Tweet text : @HMRCcustomers No this is my first job
Label :no complaint
...
之后LLM就会给我们生成一个Prompt,下次我们想让LLM帮我们做判断的时候,就把这个Prompt拼在我们自己的Prompt前面,类似下面这样:
[LLM 生成的Prompt]
Tweet text : @denny the grocery price is soaring, even milk is becoming unaffordable, could you do something?
Label :
在拼接的Prompt前缀的助力下,LLM就可以判断这条tweet是不是在吐槽了。
Prompt Tuning和Few Shot有什么区别
熟悉Prompt技巧的同学马上会发现,这好像和Few Shot很像。是的,从底层思路上两者有相似之处,都是通过让LLM学习例子,然后更好地回答问题。
但Few Shot有一些天然的局限性:
各种LLM的上下文(context)长度都是有限的,我们只能在Prompt中给出有限几个例子,这在业务比较复杂的时候,并不足以教会LLM需要的知识。而Prompt Tuning则没有这个限制,我们可以对LLM进行充分训练
在向LLM提问时,过多的例子不但会降低LLM的响应速度,而且其费用是和问题长度成正比的,在业务中每天多次带着长长的例子提问,累积起来成本会大幅上升。而Prompt Tuning只需要在训练LLM的时候一次性给它看足够的例子,之后提问时,只需要带上一个短短的Prompt前缀(一般8~20个token)就可以了,一个例子都不需要再向它提供
Few Shot更大的问题是不稳定性,业界的研究已经发现,例子的顺序对结果有很大的影响,LLM总是倾向给出和最后一个例子接近的答案;研究还发现,例子的样本分布对结果也有很大影响,以上面判断一条tweet是否为吐槽的情况为例,如果给出的例子中大多数是吐槽,那么LLM给出的答案也会倾向于吐槽。而Prompt Tuning则可以完全避免这些问题,让LLM的输出稳定可控
Prompt Tuning和Fine Tuning有什么区别
做过模型精调的同学可能会问,Prompt Tuning需要训练LLM,这不就是Fine Tuning吗,要精调一个模型成本很高啊。
Prompt Tuning和Fine Tuning最大的区别就是,Prompt Tuning是完全冻结LLM的,LLM的权重完全保持不变,真正要训练的是一个Prompt前缀,这个前缀一般只有几十个Token,其训练成本比Fine Tuning要低若干个数量级,在后面要为大家展示的例子里,我训练了一个8个token的前缀,保存在硬盘上一共才33K。
为什么8个Token需要33K空间,难道不应该是几个字节吗?
我们知道,在向LLM提问的时候,我们的输入首先会被转化为向量表示(关于向量可以参考这篇文章),简单说向量就是语言在高维空间中的表示,其中既蕴含着如语气、情绪、环境、语法等我们能理解的维度,也蕴含着只有LLM才能理解的维度(这也是LLM动辄几百、上千亿参数的原因)。
就像三体里面智子的二维展开一样,当一个字或一段话被转化为向量表示后,其占用的空间也会大大增加,假设一个Token是一个1024个维度的向量,每个维度上的取值用4个字节来表示,那么一个Token就会占据4K空间。
敏锐的同学可能会问,我上面说的是“我训练了一个8个token的前缀”,那么是不是Prompt Tuning返回的"Prompt"实际并不是文字,而是一些向量?
确实如此,Prompt Tuning返回的的确是向量而不是文字,虽然这些向量有时候可以被反向翻译回文字,但也有可能并没有和这些向量直接对应的文字。但这并不影响LLM,因为我们的文字输入也是首先被翻译成向量,然后才由LLM对其进行处理的。
返回向量而不是文字,这带来Prompt Tuning的一个缺点,那就是其可解释性下降,虽然我们可以找到一些文字,其向量表示和Prompt Tuning返回的向量接近,但这毕竟不直接。Prompt Tuning能让LLM更好地发挥其潜力,但我们也不得不接受这一瑕疵。
具体Prompt Tuning应该怎么做?
这里还是以上面判断一条tweet是否是吐槽为例,我将通过代码为大家一步步展示其具体工作过程(实际很简单),对代码不感兴趣的同学可跳过这一部分,我在文末也提供了colab的链接,喜欢动手的同学也可以copy一份自己试一下。
首先我们需要安装必要的开发库:

接下来我们import需要的类和函数,并进行基本配置:

这里为了方便演示和实际动手实践,我选择了一个只有5.6亿参数的模型bigscience/bloomz-560m,并用PromptTuingConfig对象来设置Prompt Tuning相关的配置,注意这里我用num_virtual_tokens指定Prompt前缀为8个token,这些token的初始化可以是随机的,但研究表明用一些和任务相关的文字来初始化效果更好,所以这里prompt_tuning_init_text我使用了“Classify if the tweet is a complaint or not:",其它是一些细节配置,大家可以参考我的colab自己动手实践。
然后加载训练数据,并使其可读性更好:

下一步是对训练数据进行预处理,准备开始训练:
这一步略繁琐,大致是把tweet和其是否为吐槽的标签进行长度对齐,使得每条训练数据大致是这样的格式(具体细节请参考文末colab链接):

其中的"attention_mask"和tweet对应,tweet中每个单词对应1,表示应该关注,其它为了对齐而填充的pad字符对应0,表示处理时忽略,tweet对应的label用数字-100来填充,使其长度和tweet对齐。
我们定义一个函数preprocess_fn来进行上述数据格式整理,之后把数据分为训练和评估两组数据:

接下来训练LLM:
先加载模型,并打印一下需要训练的参数量作为参考:

其输出为:
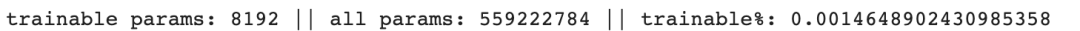
可以看到模型参数有5.6亿,而需要训练的参数仅仅只有8192个。
训练代码很简单,把之前准备的训练、评估数据和模型等作为参数传入即可:

因为需要训练的参数很少,模型也只有5.6亿参数,训练很快收敛,2分多钟训练完成:
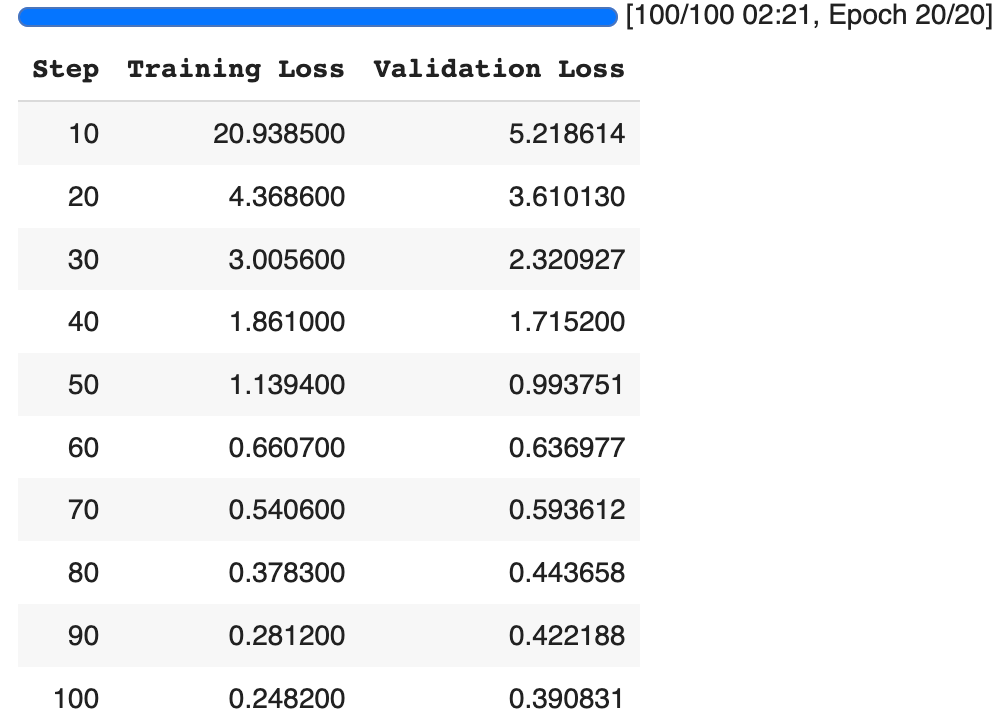
把训练结果保存到硬盘以备后用(只有33K):


终于可以看看效果了:
先定义一个推理函数:

为了对比效果,先看看原始模型:



可以看到其输出完全不可用,我们再在原始模型上试试Few Shot技巧:


可以看到有很大进步,模型按期望打出了标签,但在后面又添加了一些莫名其妙的内容。
现在让我们看看Prompt Tuning训练后的效果:
首先还是把模型加载起来,注意这里我们的基础模型是一样的,但是从硬盘加载了之前的训练结果:

然后看看效果:

可以看到在0提示的情况下,模型完全按期望完成了工作。需要注意的是,我们并不需要自己手动拼接Prompt前缀,模型会自动帮我们完成这一工作。
以上就是Promp Tuning的完整过程,可以看到只需要很少的代码,我们就找到了充分发挥LLM潜力的Prompt前缀。
和Prompt Tuning相似的技术还有哪些?
Prompt Tuning并不是这一方向的首创,其鼻祖名为Prefix Tuning,顾名思义,Prefix Tuning也是通过训练LLM找前缀,它和Pompt Tuning一样都不需要修改LLM本身,它和Promp Tuning的不同在于,它不但要在用户输入这一层找到一个前缀,它实际在LLM的每一层都要找到一个前缀附加上去,这导致它比Prompt Tuning更加复杂,训练成本也略高一样,可以认为Prompt Tuning是一个简化版的Prefix Tuning.
另一个类似的技术叫做P-Tuning,Prompt Tuning是找到一个前缀,而P-Tuning则认为,我们不但可以在用户输入的前面附加信息,也可以在中间或者结尾附加信息,附加信息的位置可以更灵活。P-Tuning同样不需要修改LLM参数,但它比Prompt Tuning更加复杂,训练成本也要略高一些。
这两个技术都和Promp Tuning相似,效果也都不错,有兴趣的同学可以参考相关论文。
以上就是Prompt Tuning的介绍和完整的代码实现,喜欢动手的同学可以参考我的colab(https://colab.research.google.com/drive/1lhUovh4Rl7DZqqeopnSZHb5I-AX4baZo)
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/C1lrOJUMkcngOnEE3qrEhA Tag: ChatGPT使用技巧 Prompt ChatGPT提示词