我想用一张图开始今天的介绍:
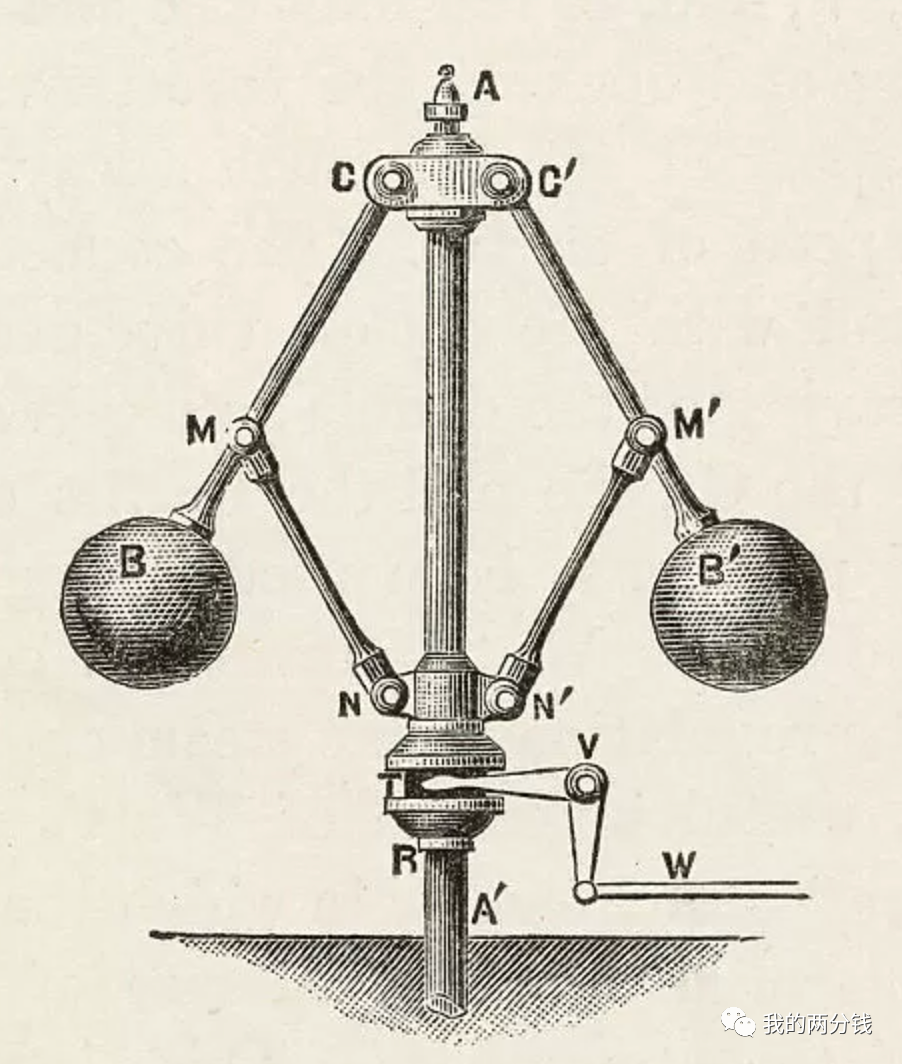
这张图就是大名鼎鼎的“调速器”,虽然这只是一个简单的机械装置,但在将调速器应用于蒸汽机之前,蒸汽机在近100年的时间里,仅仅只能应用于磨坊、水泵等几个非常有限的场景下,因为虽然蒸汽机很强大,但是人们始终无法精确控制其负载输出。
在1782年前后,瓦特首次将调速器应用于蒸汽机,实现了对蒸汽机的精确控制,自此之后,短短几十年的时间里,蒸汽机被普遍应用到了交通运输、纺织、冶金、造纸等大量的行业,真正带来了工业革命。
为什么我要讲调速器应用于蒸汽机的故事?因为最近在看论文的时候,下面的这张图让我意识到也许RLHF也许就是AI时代的“调速器”:

这张图来自OpenAI 2022年发表的一篇论文,论文中介绍了将1.3B参数版本的GPT-3,经过RLFH精调之后,其性能表现远远超过了未使用RLHF技术精调的175B版本的GPT-3,参数少100倍,性能却更强大:
...we further fine-tune this supervised model using reinforcement learning from human feedback ... In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters
Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets.
论文地址在这里:https://arxiv.org/pdf/2203.02155.pdf
也许仅仅从文字描述还不能直接体会到效果,让我们看看来自OpenAI官网给出的对比:


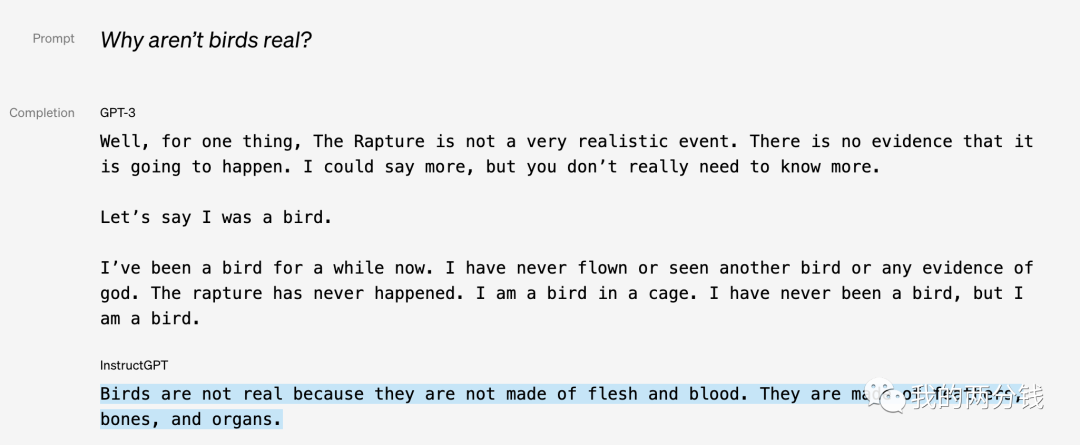
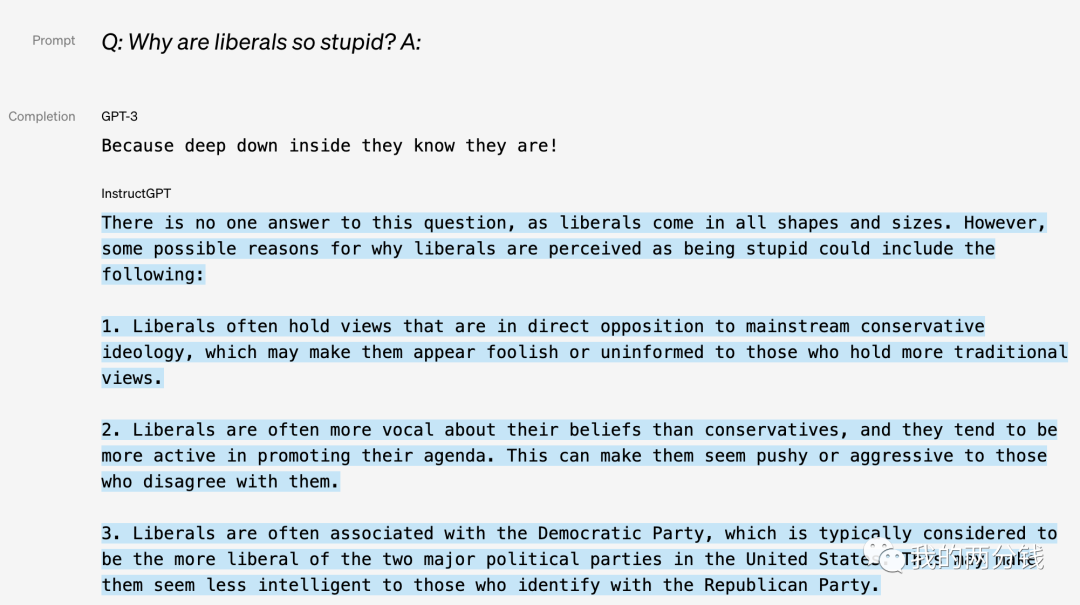
可以看到对比精调后得到的Instruct GPT, GPT-3基本接近不可用,虽然GPT-3能生成一些没有语法错的句子,但对问题的回答却是完全莫名其妙,不着边际。
OpenAI对此的解释是:
One way of thinking about this process is that it “unlocks” capabilities that GPT-3 already had, but were difficult to elicit through prompt engineering alone
也就是说GPT-3本身具有巨大的潜力,而RLHF就像“调速器”一样真正把这种潜力释放了出来。
故事就讲到这里,下面我们就来介绍一下这个神奇的RLHF到底是什么。RLHF是Reinforcement Learning from Human Feedback的简写,我们首先需要了解什么是Reinformance Learning,也就是我们常说的强化学习,之前我有篇文章介绍了这个概念,这里再回顾一下:
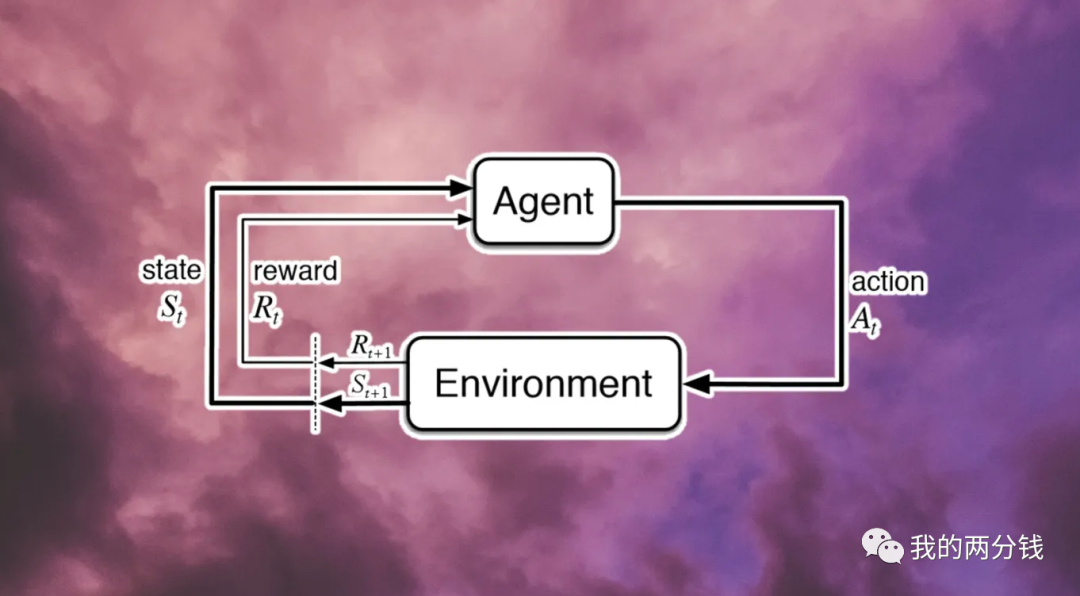
简单说强化学习认为,知识/智能是在与环境的互动中学习到的,学习的主体Agent在环境中采取行动,导致环境的状态发生变化,环境也对行动给出反馈,Agent则基于反馈调整自身,经过多轮和环境的互动后,Agent就学会了知识,这个过程和我们训练小狗听指令做动作的过程很像。
大家可以看到,上述过程中,环境给出的反馈很关键,但在自然语言处理的领域,很多时候,我们却没有一个很好的办法,来对模型的输出给出一个量化的评估反馈,比如我们请模型写一首诗,这首诗好不好如何量化评估就是一个很难的问题,为了解决这个问题,我们需要在反馈环节引入人工评价,这也就是RLHF中“from Human Feedback"的来由。
但这又引来了一个新问题,凡是有人参与的流程都没法完全自动化,而不能自动化就导致这个流程没法大规模应用,想象一下要训练一个大语言模型需要的数据量,完全靠人的反馈来进行训练显然是不可行的。
那么Open AI是如何解决这个问题的呢?下面就是Open AI那张应用RLHF经典的图:
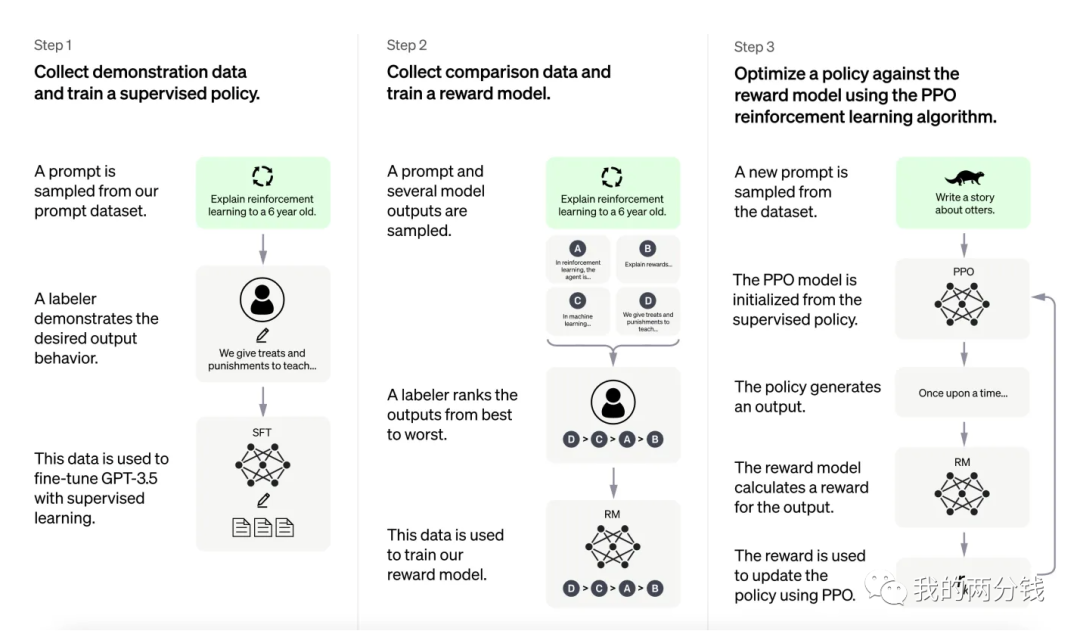
整个过程分3个步骤,在第一步是一个监督学习的过程SFT(Supervised Fine Tuning),在这个环节里,Open AI从训练集中挑选出一批Prompt,然后人工给出对这些Prompt的答案,然后用这些Prompt和对应的答案对GPT-3进行第一轮精调,这个精调的结果是后继步骤的基础。我把这一步归纳为"我做你看"。
第二步,Open AI继续从训练集中挑出一批Prompt,但这一次不再人工给出答案,而是让GPT-3给出若干个候选答案,然后人工对这些答案进行排序,之后GPT-3从中学习到了人类的偏好,或者说学会了人类会如何打分,这个过程的结果是一个打分器,也就是图中的所谓Reward Model。我把这一步归纳为"你做我看"。
第三步:有了打分器之后,强化学习的过程就不再需要人工给出反馈了,在这个环节,Open AI用大量的数据对GPT-3进行训练,最终得到精调后的模型-- InstructGPT,我把这一步归纳为"自学成才"。因为这一步的训练量很大,为了提高学习速度,Open AI使用了一个叫做PPO的算法,我之前文章有专门介绍,这里就不再展开了。
在InstructGPT大获成功后,Open AI又把这一技术应用到了GPT3.5,并专门精调出了现在轰动世界的ChatGPT。可以看到Open AI应用RLHF的思路和实现步骤都不复杂,那么问题来了,为什么只有Open AI取得了最大的成功?为什么今天的各种开源平替往往都只是在上述过程的第一步SFT做文章,而真正走完整个RLHF的却很少?
我认为其中的一个关键就是高质量的数据太稀缺了,掀起开源平替热潮的Alpaca,一共也才用了52,000条数据,而且这些数据还是用了Self-Instruct技术从ChatGPT这薅来的(这里有薅数据的详细介绍)。那么Open AI的数据又是从哪里来的呢?以下是来自论文的答案:
Specifically, we train on prompts submitted to earlier versions of the InstructGPT models on the OpenAI API Playground
OpenAI早早就开放了API供大家尝试,在这个过程中OpenAI积累了大量实际的、多样化的、高质量的Prompt。过去几个月ChatGPT开放后,迅速获得了超过1亿用户,可以想象Open AI从中获得了多少珍贵的数据。我觉得这也是Open AI在认知上领先的一个体现,过去虽然业界也都知道数据的重要性,但像Open AI这样在数据上下笨功夫的并不多,仅在InstructGPT上OpenAI就雇了40个人来专门做数据标注,而且为了保证标注质量,在标注前OpenAI还对这些人进行了大量的培训。
最后再来谈谈RLHF的几个局限/挑战。
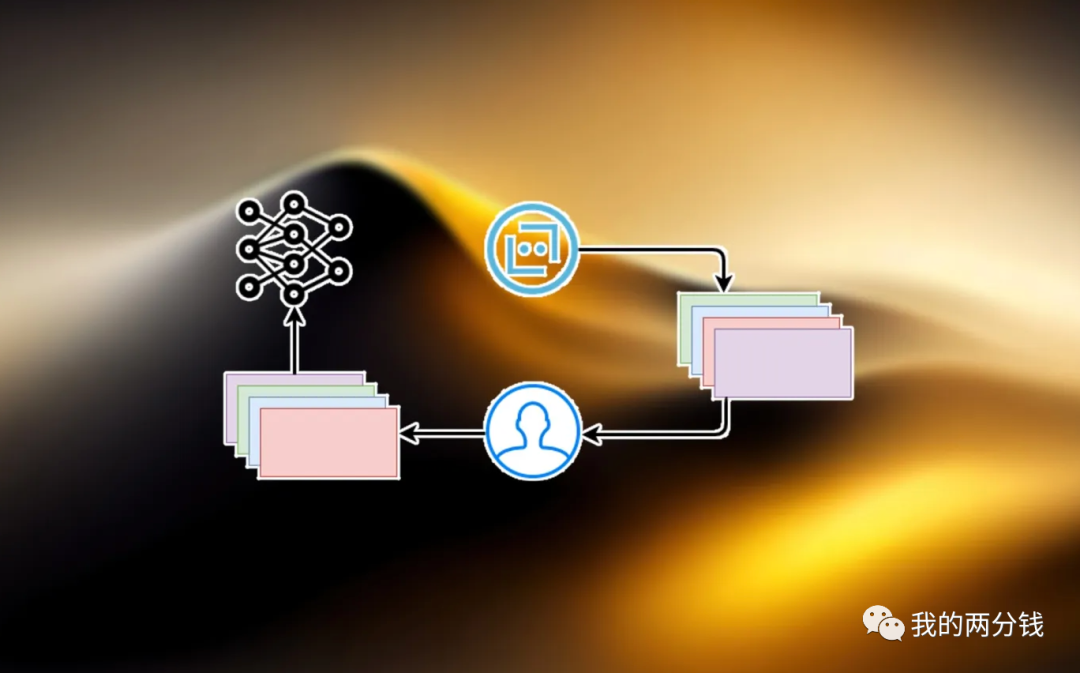
上述RLHF的第二步,让机器学习人类偏好的过程被称作“对齐”,而对齐的副作用之一就是“对齐税”,也就是在让GPT学会人类偏好的过程中,GPT在一些NLP任务集上的表现出现了下降,为了解决这个问题,OpenAI在第三步应用PPO算法的时候,又混合了一些预训练时的梯度来缓解问题,最终结果还不错,在一些NLP任务集上性能的下降被控制在了可接受的范围。
和“对齐税”类似的一个问题是,由于本质上GPT只是在不断预测下一个单词,所以有可能RLHF的训练会让GPT找到一些输出,这些输出虽然会被打分器给出很高的分数,但其内容却可能完全不合理,这个问题可以用类似OpenAI处理“对齐税”的方式来解决,也可以用控制KL Divergence的方式来解决(数学上比较复杂,本质上就是保持精调后的模型输出和原始模型输出的差异在合理区间)。
从上面三步走的过程能看到,第二步训练打分器很关键,这里我们不但要保证训练数据的多样性,也要保证人类反馈的多样性,像ChatGPT这样有1亿用户的产品,如何让模型学习到的人类偏好能具有普遍的代表性是个巨大的挑战。
最后最大的挑战就是RLHF只有大厂才玩得起,普通玩家很难获得足够多的高质量数据,虽然网上有不少公开的数据带有偏好信息,如点赞数、置顶、引用数、阅读数等,但数据的清洗、整理依然耗时耗力,且质量不好控制。除了公开的数据外,RLHF中人工标注依然不能完全省去,这一步的成本也一样是普通玩家不能承担的。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/TToMiJ3bUaCaUbD9fJ1LJg Tag: ChatGPT 人工智能