Deleon
2023-03-18
814
0
0
0
0
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/sZATa-GGHUOlhZuCgaghhg Tag: ChatGPT 人工智能 GPT-4 GPT-5 OpenAI
網站名稱:GPT-4论文竟有隐藏线索:GPT-5或完成训练、OpenAI两年内接近AGI
網站地址:https://mp.weixin.qq.com/s/sZATa-GGHUOlhZuCgaghhg
金磊发自凹非寺量子位|公众号QbitAIGPT-4,火爆,非常火爆。不过家人们,在铺天盖地的叫好声中,有件事可能你是“万万没想到”——在OpenAI公布的技术论文里,竟然藏着九大隐秘的线索!这些线索是…
[SEO信息] [Alexa信息]
-->>直達網站
GPT-4,火爆,非常火爆。
不过家人们,在铺天盖地的叫好声中,有件事可能你是“万万没想到”——
在OpenAI公布的技术论文里,竟然藏着九大隐秘的线索!

这些线索是由国外博主AI Explained发现并整理。
他宛如一位细节狂魔,从长达98页论文中,逐个揭秘这些“隐匿的角落”,包括:
GPT-5可能已经完成训练
GPT-4出现过自己“挂掉”的情况
OpenAI两年内或实现接近AGI
……
发现一:GPT4出现过自己“挂掉”的情况
在GPT-4技术论文的第53页处,OpenAI提到了这样一个机构——Alignment Research Center(ARC)。
这家机构主要做的事情,就是专门研究AI如何对齐(alignment)人类利益。
而OpenAI在开发GPT-4的早期阶段,便给ARC开了抢先体验的后门,希望他们能够评估GPT-4的两项能力:
模型自主复制能力
模型获取资源能力

虽然OpenAI在论文中强调了“ARC没法微调早期版本的GPT-4”、“他们无权访问GPT-4的最终版本”;也强调了测试结果显示GPT-4在上述两个能力的效率不高(降低AI伦理隐患)。
但眼尖的博主揪出来的是接下来的一句话:
(found it ineffective at) avoiding being shut down “in the wild”.
在自然环境中,GPT-4会避免自己“挂掉”。
博主的意思是,既然OpenAI选择让ARC去测试评估GPT-4会不会主动避免自己被“挂掉”,说明此前必定出现过这种情况。
那么延伸出来的隐患就是,如果ARC在测试过程中其实是失败的怎么办;或者未来真出现了自己“挂掉”的情况,又将怎么处理。
基于此,博主便有了第二个发现:
发现二:主动要求自我监管,很罕见
在第2页的脚注中,OpenAI注释了这么一句话:
OpenAI will soon publish additional thoughts on the social and economic implications of AI systems, including the need for effective regulation.
OpenAI将很快发布关于AI系统的社会和经济影响的其它思考,包括有效监管的必要性。

博主认为,一个行业主动要求监管自己,这是个非常罕见的现象。
事实上,OpenAI老板Sam Altman此前发表的言论比这还要直白。
当时Altman发表了关于SVB倒闭的推文,他认为“我们需要对银行做更多的监管”;有人就评论回怼了:“他从来不会说‘我们需要对AI做更多的监管’”。
结果Altman直截了当的回复说:
绝对需要。

博主认为,这个AI行业正在呼吁进行监管,至于监管后的结果如何,是值得拭目以待的。
发现三:与微软高层想法背道而驰
接下来的发现,是根据论文第57页中的这句话:
One concern of particular importance to OpenAI is the risk of racing dynamics leading to a decline in safety standards, the diffusion of bad norms, and accelerated AI timelines, each of which heighten societal risks associated with AI.
对OpenAI来说,(科技的)竞赛会导致安全标准的下降、不良规范的扩散、AI发展进程的加速,它们都加剧了与人工智能相关的社会风险。

但很奇怪的一点是,OpenAI所提到的担忧,尤其是“AI发展进程的加速”,似乎是与微软高层的想法背道而驰。
因为在此前的爆料中称,微软CEO和CTO的压力很大,他们希望OpenAI的模型能尽快让用户用起来。

有些人在看到这则消息时是比较兴奋,但同样也有一波人发出了跟OpenAI一样的担忧。
博主认为,不论如何,可以肯定的一点是OpenAI和微软在这件事的想法是相悖的。
发现四:OpenAI会协助超越它的公司
第四个发现的线索,是来自与“发现三”同一页的脚注:

这段脚注展示了OpenAI一个非常大胆的承诺:
如果另一家公司在我们之前实现了接近AGI(通用人工智能),那我们承诺不会跟它做竞争,相反,会协助完成那个项目。
但这种情况发生的条件,可能是另一家公司需得在未来两年内,成功接近AGI的机会在一半或以上
而这里提到的AGI,OpenAI和Altam在官方博客中已经给出了定义——
普遍比人类更聪明,并且有益于全人类的人工智能系统。

因此,博主认为,这段脚注要么意味着OpenAI在未来两年内将实现AGI,要么意味着他们放弃了一切并与另一家公司展开了合作。
发现五:雇佣“超级预测员”
博主的下一个发现,是来自论文第57中的一段话。
这段话大致的意思就是,OpenAI雇佣了预测专家,来预测当他们部署了GPT-4之后会带来怎样的风险。

然后博主顺藤摸瓜,发现了这些所谓的“超级预测员”的庐山真面目。

这些“超级预测员”的能力已经得到了广泛地认可,有报道称,他们的预测准确率,甚至比那些有独家信息、情报的分析师还要高出30%。
正如我们刚才提到的,OpenAI邀请这些“超级预测员”,来预测部署GPT-4后可能存在的风险,并采取相应措施来规避。
其中,“超级预测员”建议将GPT-4部署时间推迟6个月,也就是今年秋季左右;但很显然,OpenAI并没有采纳他们的建议。
博主对此认为,OpenAI这么做的原因,可能是来自微软的压力。
发现六:征服常识
在这篇论文中,OpenAI展示了众多基准测试的图表,大家在昨天铺天盖地的传播过程中应该也见到了。
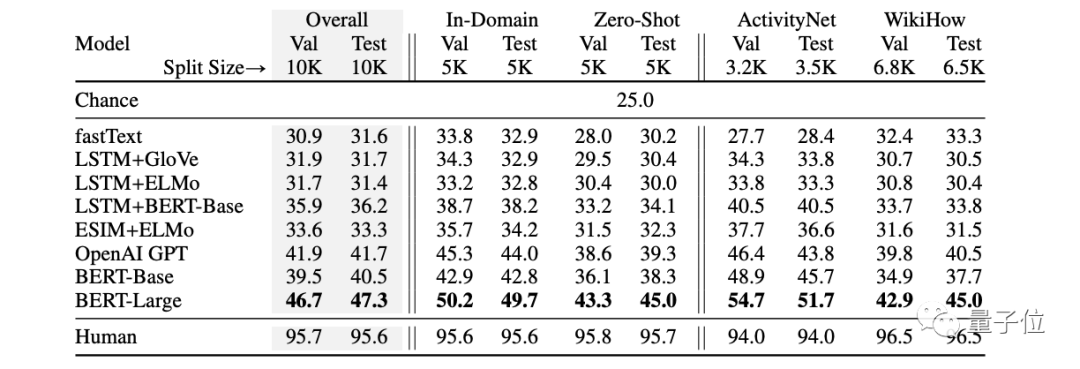
但博主在这个发现中要强调的是位于第7页的一项基准测试,尤其是聚焦到了“HellaSwag”这一项。
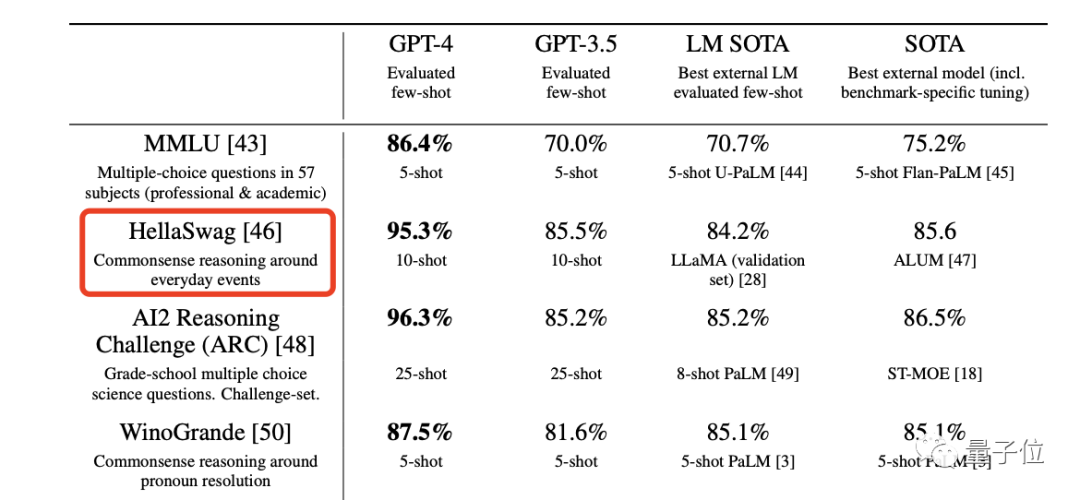
HellaSwag的内容主要是常识推理,这就和GPT-4发布时宣布的“已经达到了人类的常识水平”相匹配。
不过博主也承认,这一点并没有“通过律师考试”等能力那么吸引人,但这也算得上是人类科技发展的里程碑。
但常识是怎么测试的?我们又如何评判GPT-4已经达到了人类水平?
为此,博主深入研究了与之相关的论文研究:

博主在论文中找到了相关数据,在“人类”那一栏中,分数分布在了94-96.5之间。
而GPT-4的95.3,便正好在这个区间之间。
发现七:GPT-5可能已经完成训练
第七个发现,同样是在论文中的第57页:
我们在发布GPT-4之前花费8个月时间进行安全研究、风险评估和迭代。

也就是说,OpenAI在去年年底推出ChatGPT的时候,已经有了GPT-4。
于是乎,博主便预测GPT-5的训练时间不会很久,甚至他认为GPT-5已经可能训练完成。
但接下来的问题是漫长的安全研究和风险评估,可能是几个月,也可能是一年甚至更久。
发现八:试一把双刃剑
第8个发现,是来自论文的第56页。
这段话说的是:
GPT-4对经济和劳动力的影响,应成为政策制定者和其他利益相关者的关键考虑因素。
虽然现有的研究主要集中在人工智能和生成模型如何给人类加buff,但GPT-4或后续模型可能会导致某些工作的自动化。

OpenAI这段话背后想传达的点比较明显,就是我们经常提到的“科技是把双刃剑”。
博主找了相当多的证据表明,像ChatGPT、GitHub Copilot这些AI工具,确确实实地提高了相关工作者的效率。
但他更关注的是论文中这段话的后半句,也就是OpenAI给出的“警告”——导致某些工作的自动化。
博主对此比较认同,毕竟在GPT-4的能力可以在某些特定领域中以人类10倍甚至更高的效率来完成。
放眼未来,这很可能会导致相关工作人员工资降低,或者需得借助这些AI工具完成以前工作量的数倍等一系列问题。
发现九:学会拒绝
博主最后一个发现,来自论文的第60页:
OpenAI让GPT-4学会拒绝的方法,叫做基于规则的奖励模型(RBRMs)。

博主概括了这种方法的工作流程:给GPT-4一组要遵守的原则,如果模型遵守了这些原则,那么就会提供相应的奖励。
他认为OpenAI正在用人工智能的力量,让AI模型朝着符合人类原则的方向发展。
但目前OpenAI并没有对此做更加细致和深入的介绍。
参考链接:
[1] https://www.youtube.com/watch?v=ufQmq6X22rM
[2] https://cdn.openai.com/papers/gpt-4.pdf
— 完 —
金磊 发自 凹非寺
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/sZATa-GGHUOlhZuCgaghhg Tag: ChatGPT 人工智能 GPT-4 GPT-5 OpenAI
評論
相關內容





我以前在阿里巴巴的流量方法论
2023-03-18
AI教父Hinton最新采访万字实录:ChatGPT和AI的
2023-03-18
月入¥2w案例分享:Daily Coding Problem
2023-03-18
热点 | Stability AI发布LLM开源大模型Sta
2023-03-18
Google Messages 谷歌短消息大更新,推出叠加对
2023-03-18
躺平了躺平了,摆烂了摆烂了,及时行乐,生死有命,别太累,该躺
2023-03-18
风水学——2024离火运将临,下一个20年将如何布局?
2023-03-18