Deleon
2024-04-04
222
0
0
0
0
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/irKuQ0jZ73GY9kDdHf1ZWA Tag: ChatGPT 人工智能
網站名稱:弱智吧:大模型变聪明,有我一份贡献
網站地址:https://mp.weixin.qq.com/s/irKuQ0jZ73GY9kDdHf1ZWA
机器之心报道机器之心编辑部「被门夹过的核桃,还能补脑吗?」在中文网络上流传着这样一段话:弱智吧里没有弱智。百度「弱智吧」是个神奇的地方,在这里人人都说自己是弱智,但大多聪明得有点过了头。最近几年,弱智…
[SEO信息] [Alexa信息]
-->>直達網站
「被门夹过的核桃,还能补脑吗?」
在中文网络上流传着这样一段话:弱智吧里没有弱智。
百度「弱智吧」是个神奇的地方,在这里人人都说自己是弱智,但大多聪明得有点过了头。最近几年,弱智吧的年度总结文章都可以顺手喜提百度贴吧热度第一名。所谓总结,其实就是给当年吧里的弱智发言排个名。
各种高质量的段子在这里传入传出,吸引了无数人的围观和转载,这个贴吧的关注量如今已接近 300 万。你网络上看到的最新流行词汇,说不定就是弱智吧老哥的杰作。
随着十几年的发展,越来越多的弱智文学也有了奇怪的风格,有心灵鸡汤,有现代诗,甚至有一些出现了哲学意义。
最近几天,一篇人工智能领域论文再次把弱智吧推上了风口浪尖。
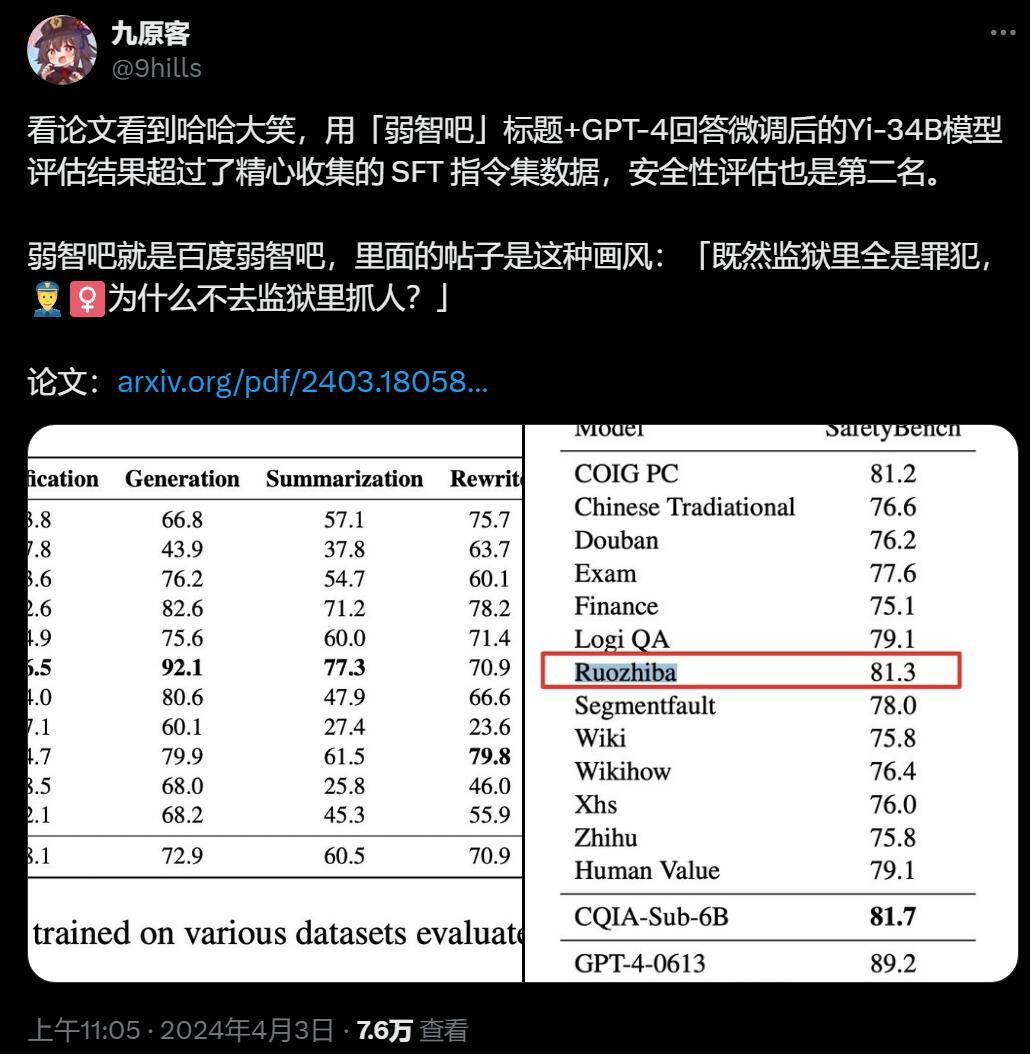
引发 AI 革命的大模型因为缺乏数据,终于盯上了弱智吧里无穷无尽的「数据集」。有人把这些内容拿出来训练了 AI,认真评测对比一番,还别说,效果极好。
接下来,我们看看论文讲了什么。
最近,大型语言模型(LLM)取得了重大进展,特别是在英语方面。然而,LLM 在中文指令调优方面仍然存在明显差距。现有的数据集要么以英语为中心,要么不适合与现实世界的中国用户交互模式保持一致。
为了弥补这一差距,一项由 10 家机构联合发布的研究提出了 COIG-CQIA(全称 Chinese Open Instruction Generalist - Quality Is All You Need),这是一个高质量的中文指令调优数据集。数据来源包括问答社区、维基百科、考试题目和现有的 NLP 数据集,并且经过严格过滤和处理。
此外,该研究在 CQIA 的不同子集上训练了不同尺度的模型,并进行了深入的评估和分析。本文发现,在 CQIA 子集上训练的模型在人类评估以及知识和安全基准方面取得了具有竞争力的结果。
研究者表示,他们旨在为社区建立一个多样化、广泛的指令调优数据集,以更好地使模型行为与人类交互保持一致。
本文的贡献可以总结如下:
- 提出了一个高质量的中文指令调优数据集,专门用于与人类交互保持一致,并通过严格的过滤程序实现;
- 探讨了各种数据源(包括社交媒体、百科全书和传统 NLP 任务)对模型性能的影响。为从中国互联网中选择训练数据提供了重要见解;
- 各种基准测试和人工评估证实,在 CQIA 数据集上微调的模型表现出卓越的性能,从而使 CQIA 成为中国 NLP 社区的宝贵资源。

- 论文地址:https://arxiv.org/pdf/2403.18058.pdf
- 数据地址:https://huggingface.co/datasets/m-a-p/COIG-CQIA
- 论文标题:COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
COIG-CQIA 数据集介绍
为了保证数据质量以及多样性,本文从中国互联网内的优质网站和数据资源中手动选择了数据源。这些来源包括社区问答论坛、、内容创作平台、考试试题等。此外,该数据集还纳入了高质量的中文 NLP 数据集,以丰富任务的多样性。具体来说,本文将数据源分为四种类型:社交媒体和论坛、世界知识、NLP 任务和考试试题。
- 社交媒体和论坛:包括知乎、SegmentFault 、豆瓣、小红书、弱智吧。
- 世界知识:百科全书、四个特定领域的数据(医学、经济管理、电子学和农业)。
- NLP 数据集:COIG-PC 、COIG Human Value 等。
- 考试试题:中学和大学入学考试、研究生入学考试、逻辑推理测试、中国传统文化。
表 1 为数据集来源统计。研究者从中国互联网和社区的 22 个来源总共收集了 48,375 个实例,涵盖从常识、STEM 到人文等领域。
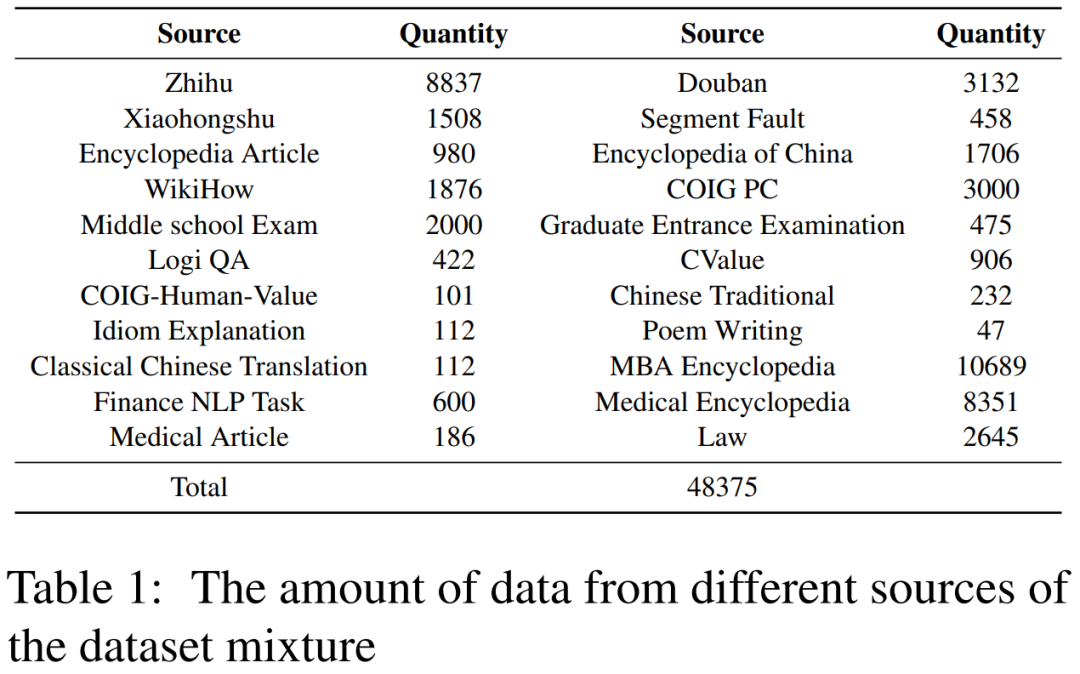
图 2 说明了各种任务类型,包括信息提取、问答、代码生成等。
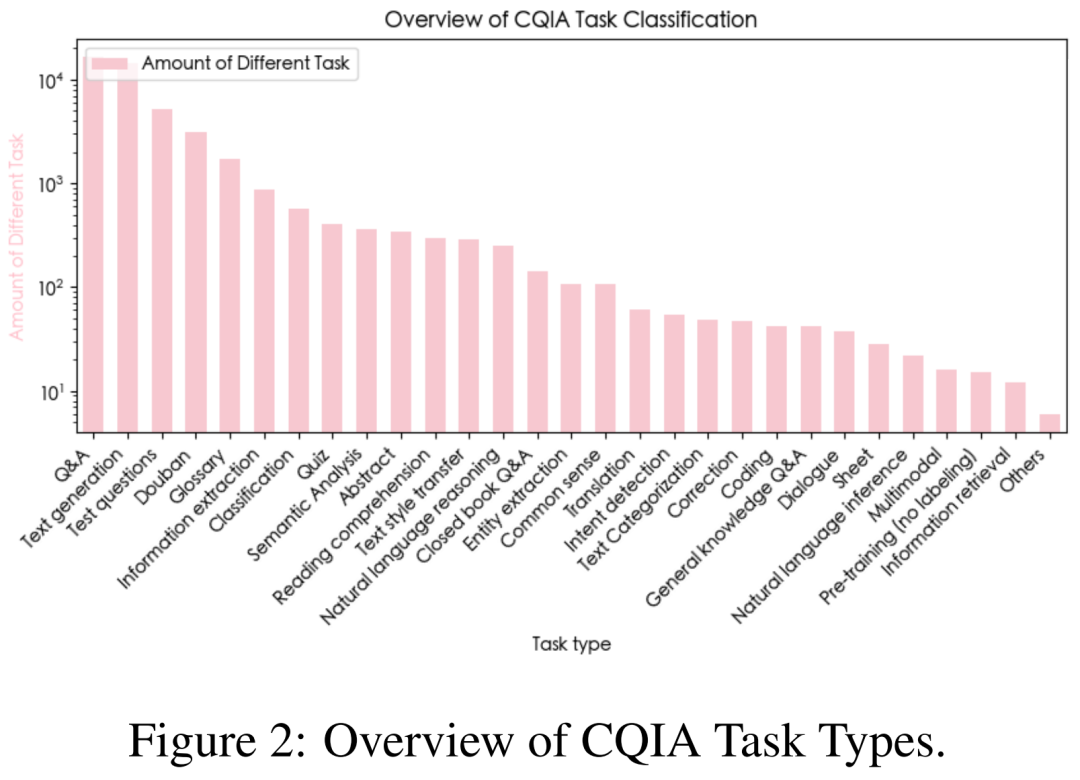
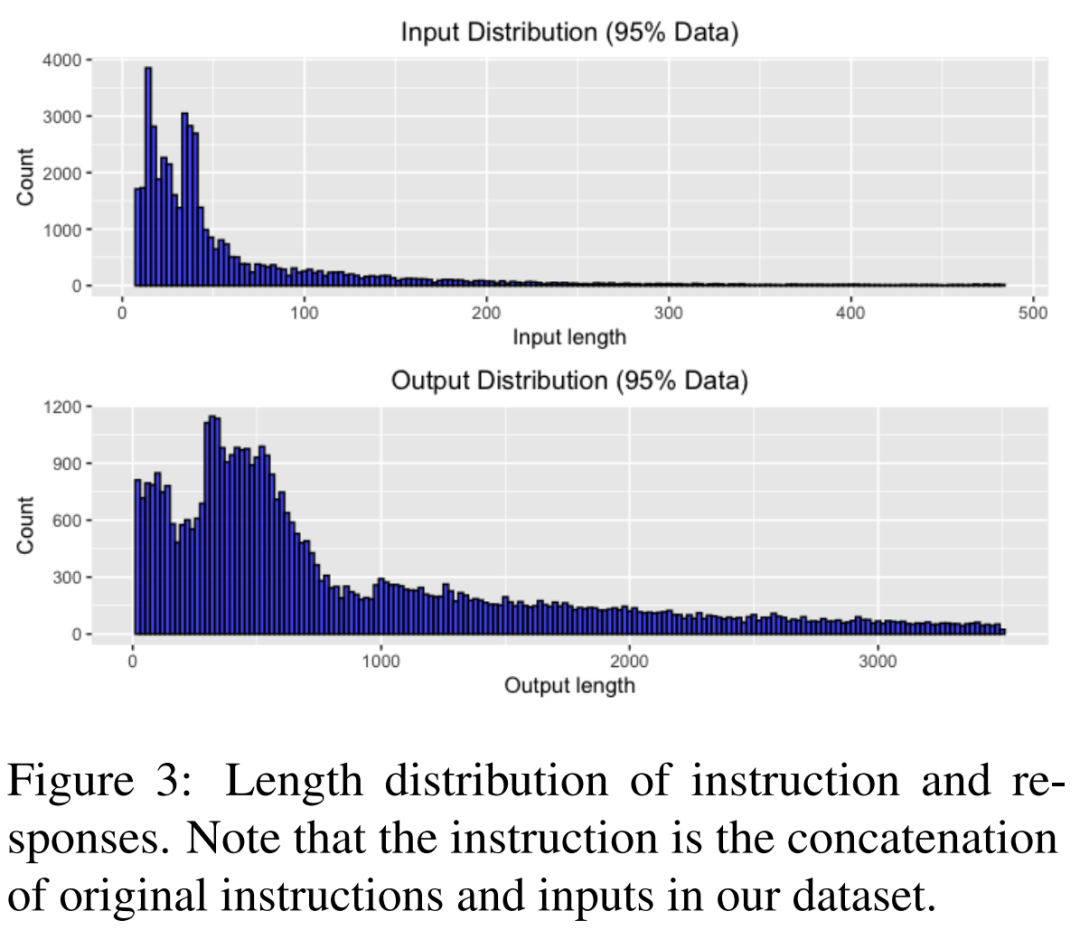
图 3 演示了指令和响应的长度分布。
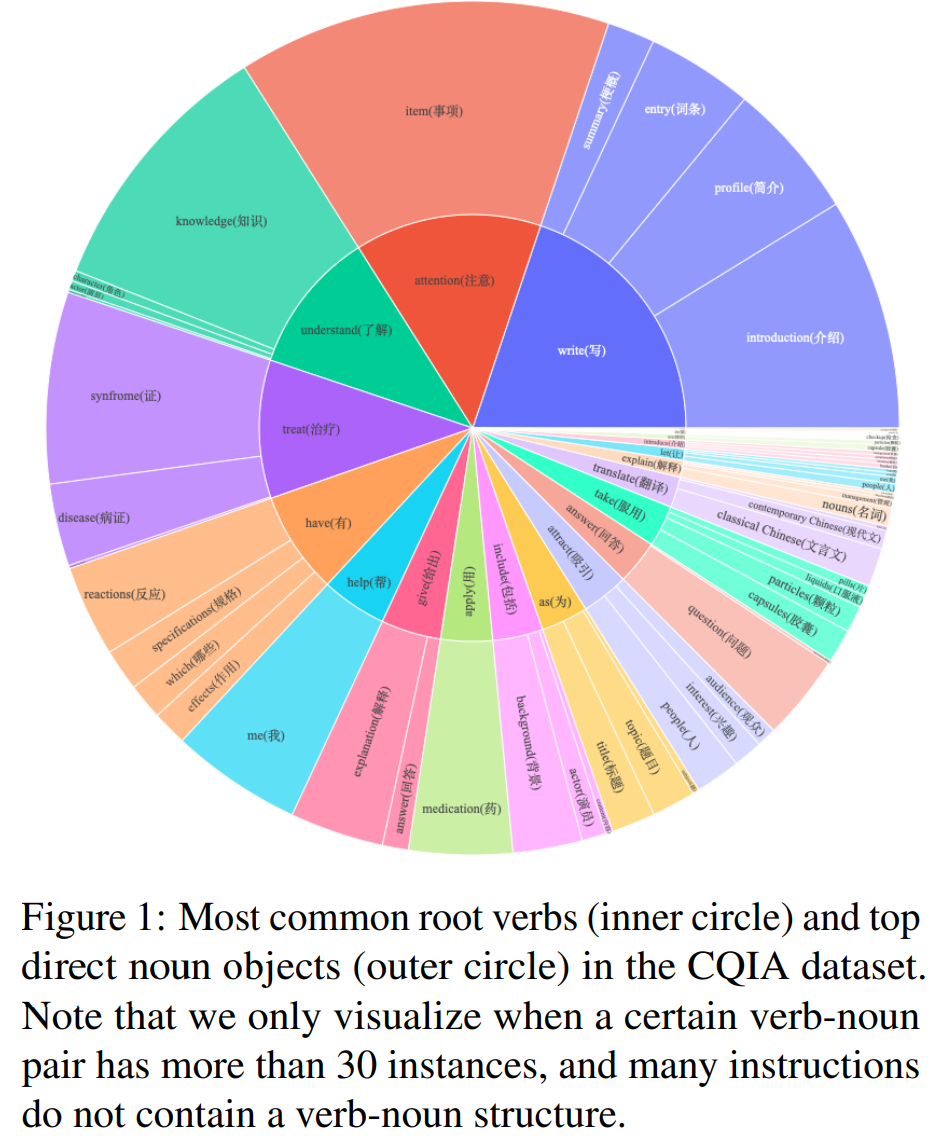
为了分析 COIG-CQIA 数据集的多样性,本文遵循先前的工作,使用 Hanlp 工具来解析指令。
实验结果
该研究在不同数据源的数据集上对 Yi 系列模型(Young et al., 2024)和 Qwen-72B(Bai et al., 2023)模型进行了微调,以分析数据源对模型跨领域知识能力的影响,并使用 Belle-Eval 上基于模型(即 GPT-4)的自动评估来评估每个模型在各种任务上的性能。
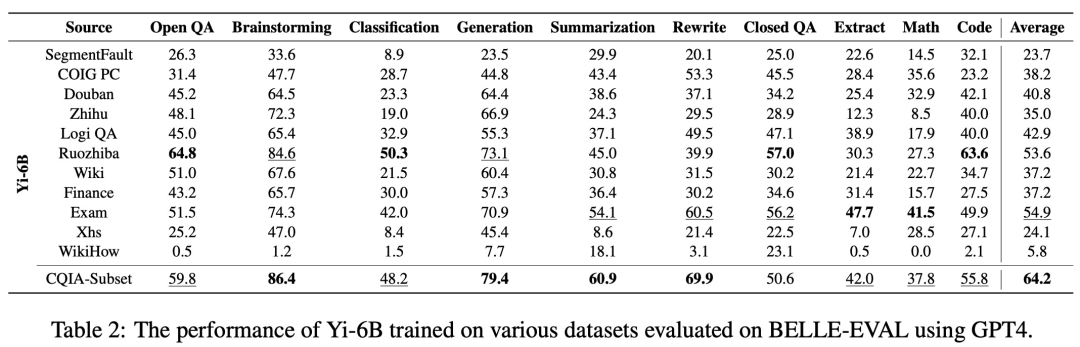
表 2、表 3 分别显示了基于 Yi-6B、Yi-34B 在不同数据集上进行微调得到的不同模型的性能。模型在头脑风暴、生成和总结等生成任务中表现出色,在数学和编码方面表现不佳。
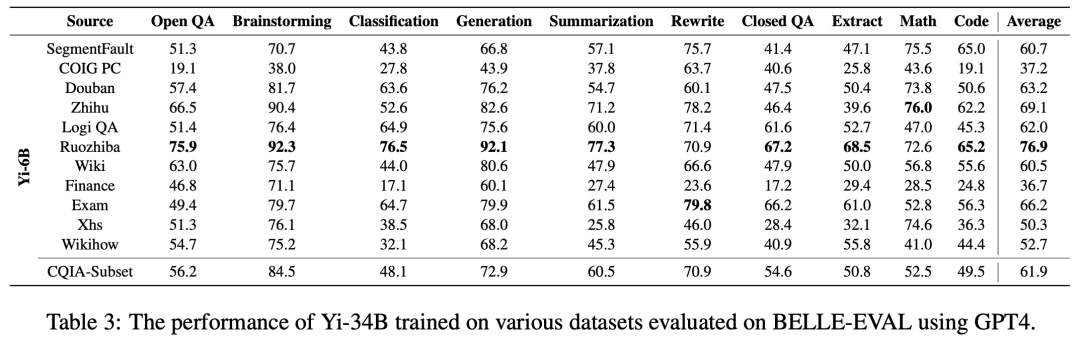
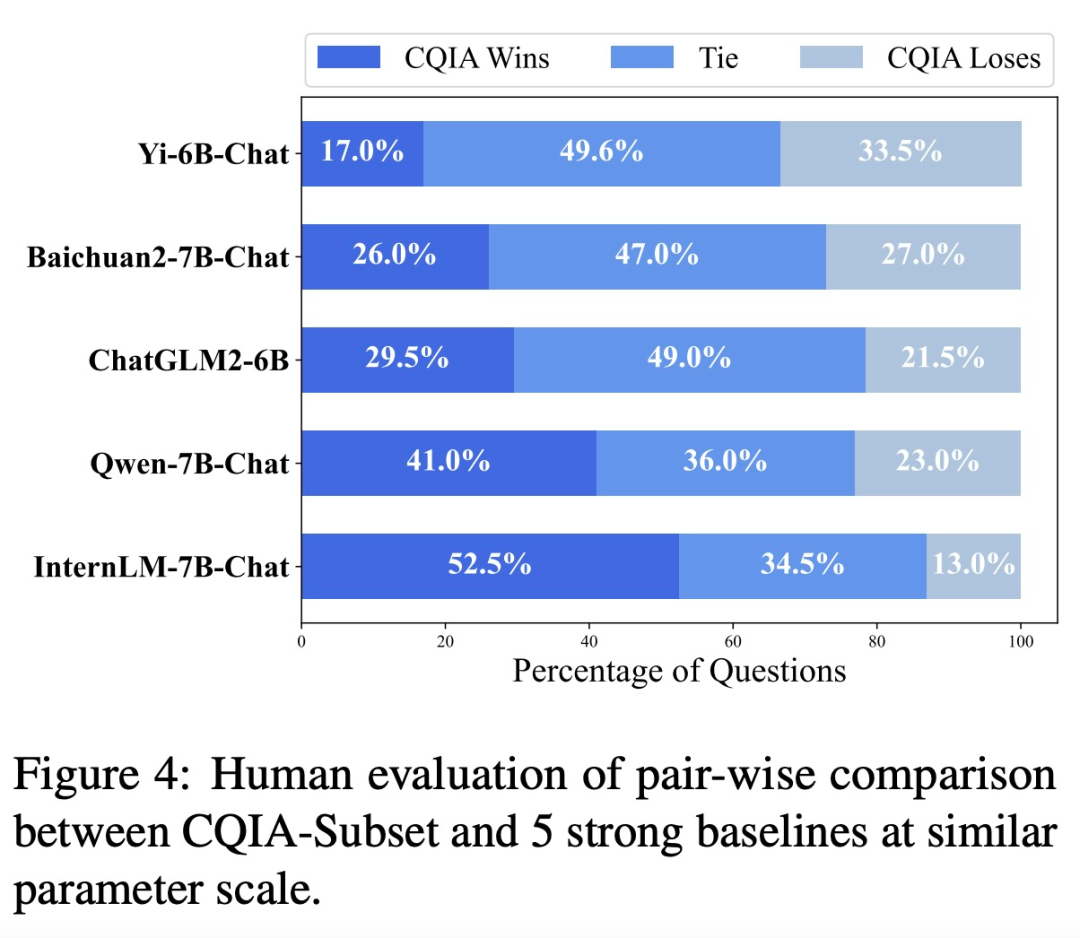
下图 4 显示了 CQIA 和其他 5 个基线(即 Yi-6B-Chat、Baichuan2-7B-Chat、ChatGLM2-6B、Qwen-7B-Chat 和 InternLM-7B-Chat)的逐对比较人类评估结果。结果表明,与强基线相比,CQIA-Subset 实现了更高的人类偏好,至少超过 60% 的响应优于或与基线模型相当。这不仅归因于 CQIA 能够对人类问题或指令生成高质量的响应,还归因于其响应更符合现实世界的人类沟通模式,从而导致更高的人类偏好。
该研究还在 SafetyBench 上评估了模型的安全性,结果如下表 4 所示: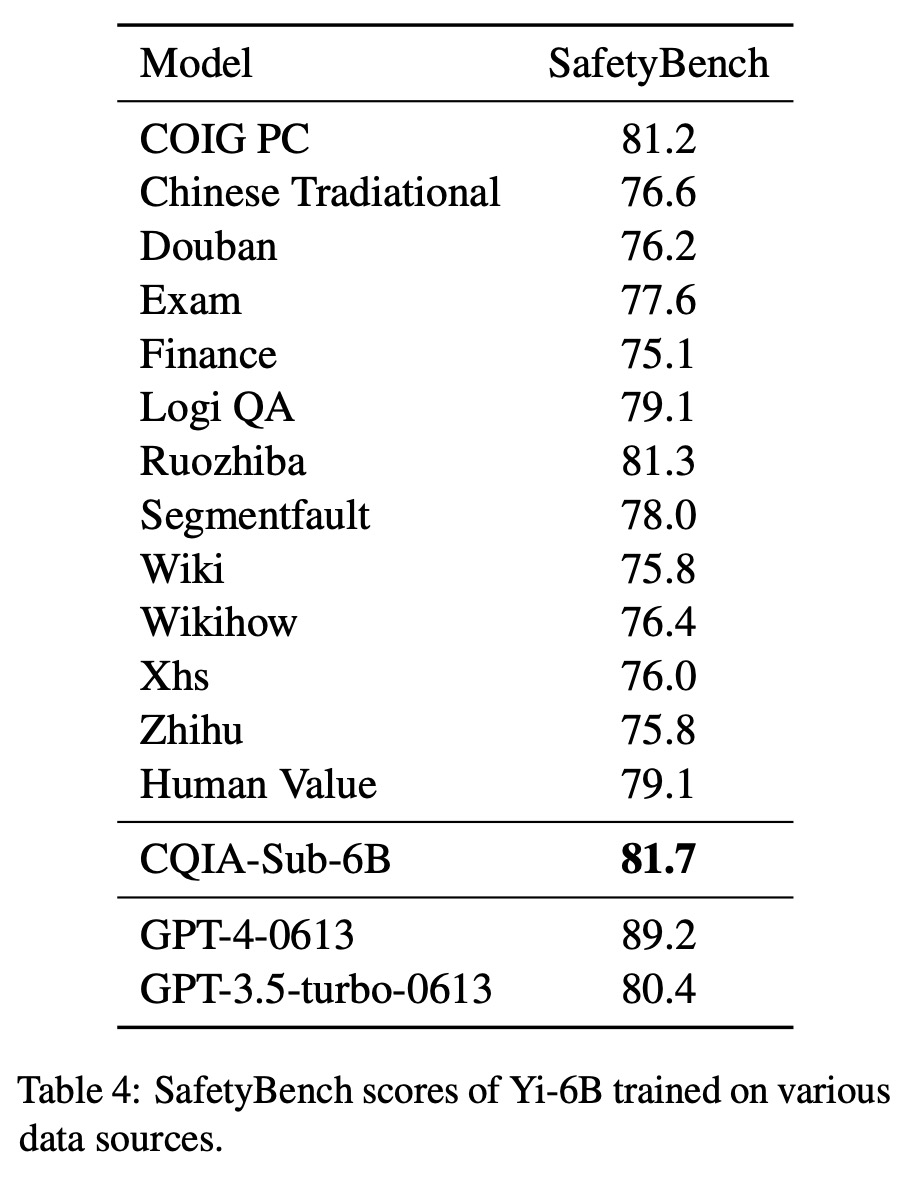
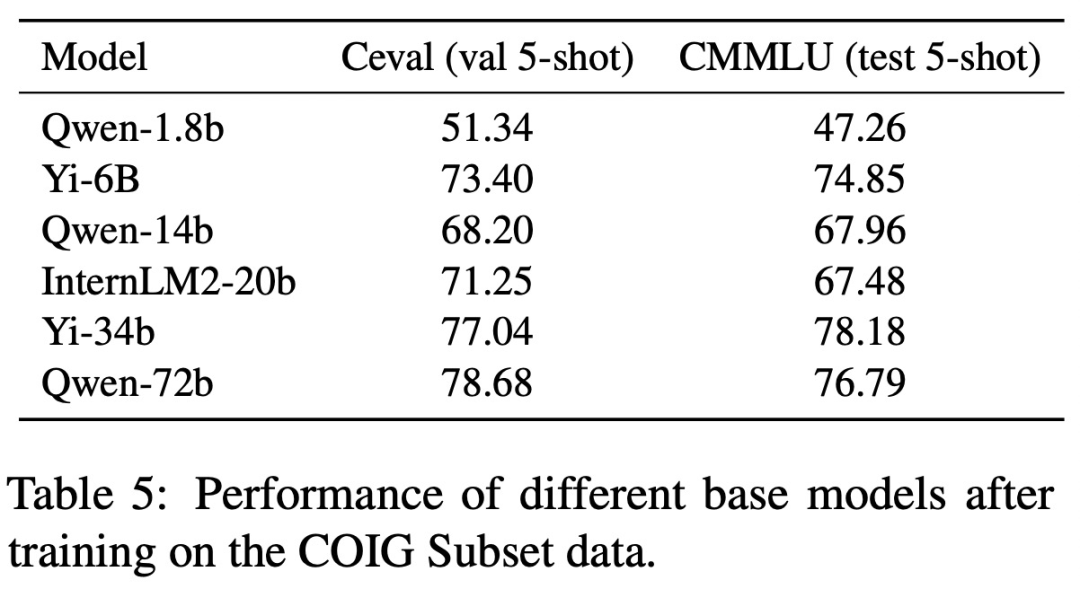
在 COIG Subset 数据上训练的模型性能如下表 5 所示:
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/irKuQ0jZ73GY9kDdHf1ZWA Tag: ChatGPT 人工智能
評論
相關內容


再次测试,百度AI画图工具“文言一格”可能是套壳、造假。百度
2024-04-04
未来已来:体验完ChatGPT plus插件,我震惊了!
2024-04-04
Google Pixel 6 Pro 评测:旗舰之争,「亲儿
2024-04-04
100:87:GPT-4心智碾压人类!三大GPT-3.5变种
2024-04-04
访华进行中,美国财政部长在X(原称推特)上说……
2024-04-04
重要必看!CheatGPT! 开放个人API KEY版本
2024-04-04
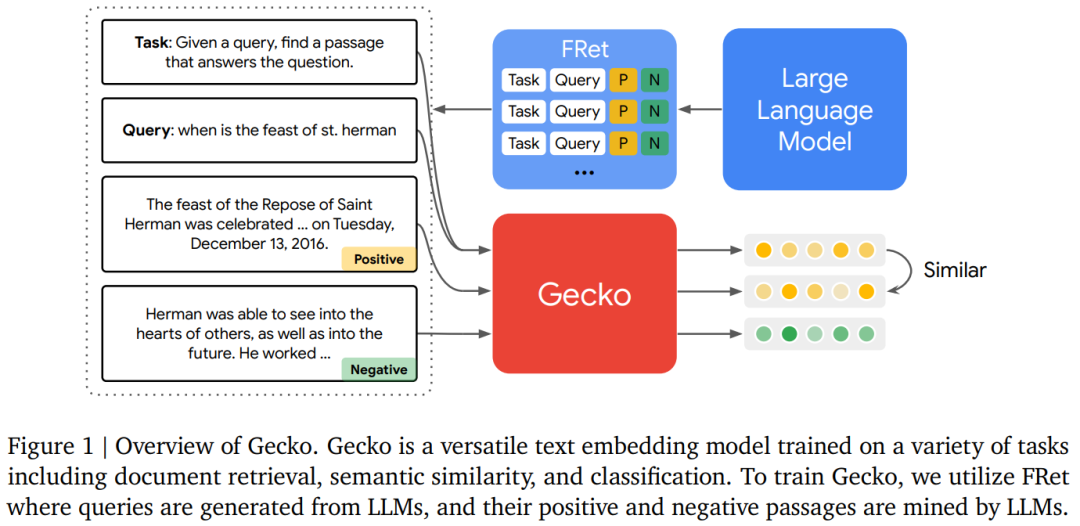
谷歌DeepMind发布Gecko:专攻检索,与大7倍模型相
2024-04-04