xiaotong
2023-12-15
460
0
0
0
0
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/_8PKBF75BZM3m8F7t6dTyw Tag: ChatGPT 人工智能 Gemini Pro Bard
網站名稱:不输GPT-4,如何免费使用谷歌最新的Gemini Pro?
網站地址:https://mp.weixin.qq.com/s/_8PKBF75BZM3m8F7t6dTyw
2023年12月7日,谷歌发布了其迄今为止规模最大、功能最强大的多模态模型——Gemini,具体介绍可以看一下之前的文章Google新AI模型Gemini即将推出,爆算力超过GPT-4五倍,能否打败O…
[SEO信息] [Alexa信息]
-->>直達網站
2023年12月7日,谷歌发布了其迄今为止规模最大、功能最强大的多模态模型——Gemini ,具体介绍可以看一下之前的文章
Google新AI模型Gemini即将推出,爆算力超过GPT-4五倍,能否打败OpenAI?
GPT-4的对手来了!Google宣布推出自己迄今为止最强大的模型 Gemini
虽然Ultra版本需要等待明年才能正式发布,但Gemini Pro已经在Bard平台上进行了内测,不论他的图像识别(尤其是中文能力)、数据分析和图像生成都已经远超GPT-3.5。重点是,Bard现在是完全免费的。
接下来就告诉大家如何使用基于最新Gemini pro 模型的bard。
对于想在电脑上体验Gemini Pro的用户来说,操作过程非常简单。https://bard.google.com 即可,与ChatGPT不同,bard只需一个谷歌账号就可以注册。
首先,要确保你的网络有科学环境,同时尽量是美国的网络节点。确定网络没有问题后,直接访问Bard官网 bard.google.com,点击登录,输入谷歌账户信息就OK了。如果遇到“你所在的国家/地区目前暂不支持Bard”的提示,需要检查一下自己的谷歌账号所在区域是否为US,然后清除下浏览器的Cookie或使用无痕模式。
登录 bard.google.com,点击登录
输入自己的谷歌账号
确定之后直接进入主界面,这时候我们就可以使用bard了
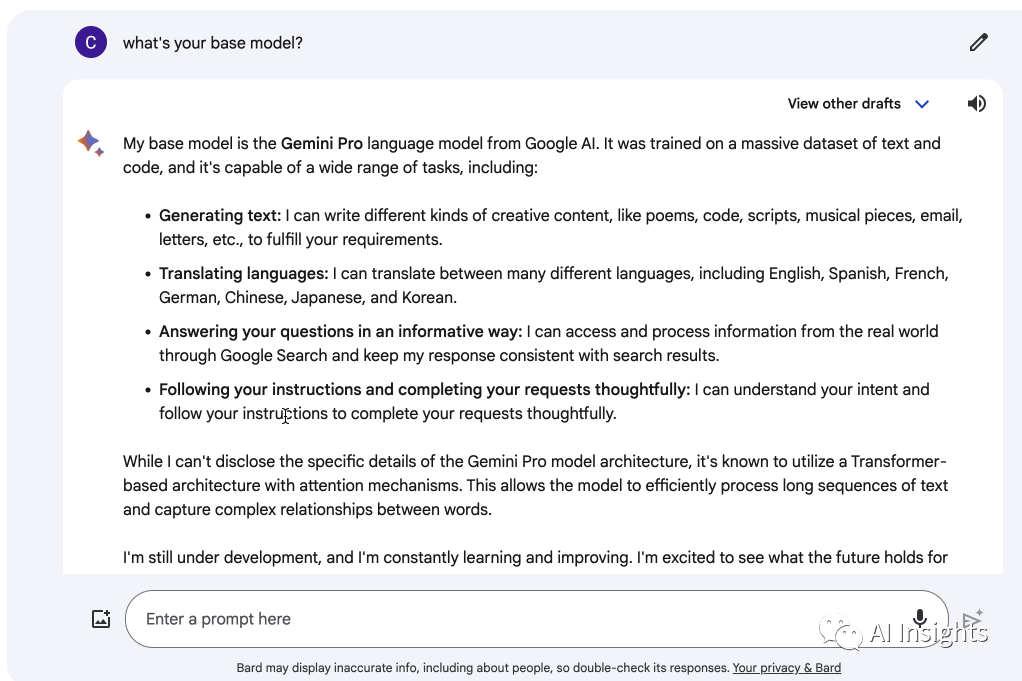
我们问一下他的基础模型
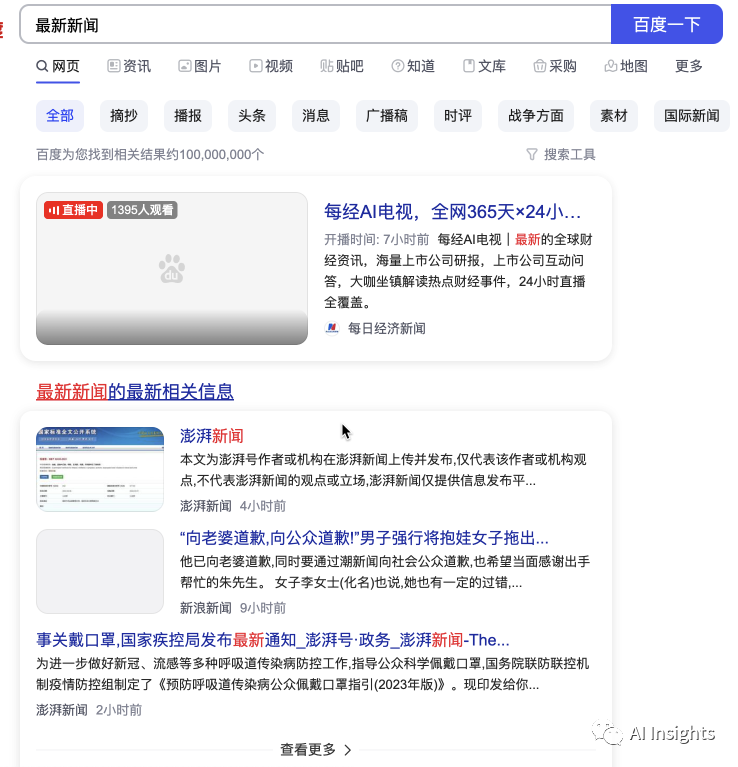
我们首先测试下他的识图能力,我在百度搜索最新新闻然后截图上传bard识别
我们可以看到bard的识别完全没有问题,这也是目前所有大模型中对中文支持最好的,即使是当前的GPT-4,对于中文的图片识别仍然是一塌糊涂,回答问题漏洞百出,经过实测目前只有bard在这方面是最优秀的。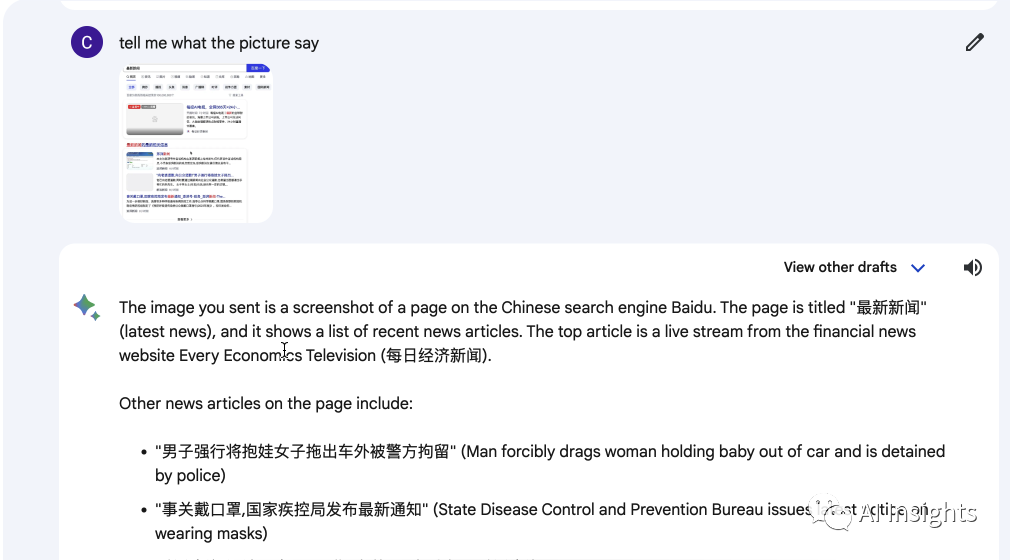
接下来我们可以给他一条youtube链接,要求他对视频信息进行总结
写代码: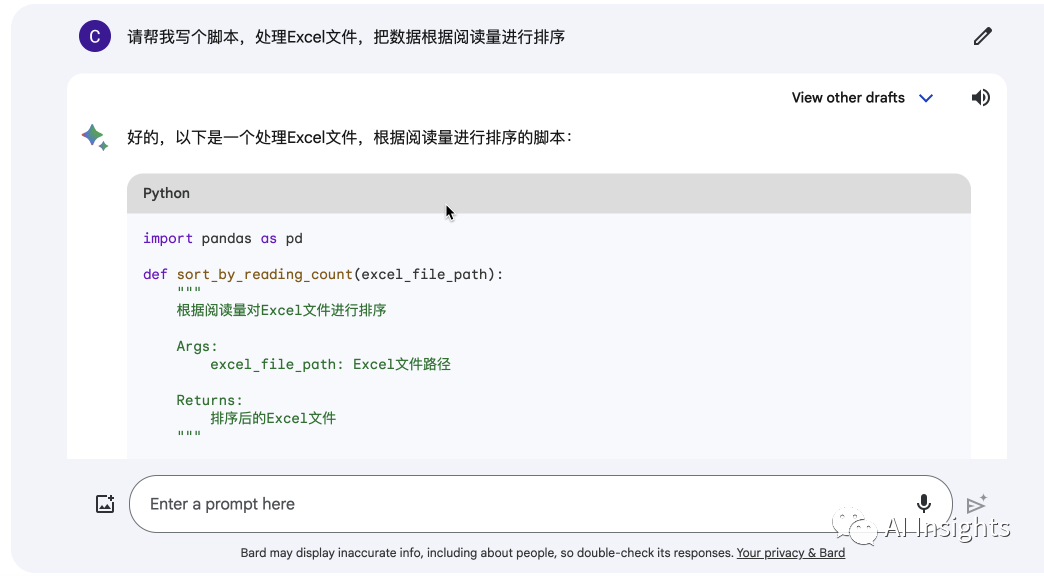
通过接近一天多的完整使用,我可以直接告诉大家结论,目前的 gemini pro综合能力是完全超过GPT-3.5的,功能也更丰富,比如可以识图,链接谷歌全家桶,实时上网获取最新信息等。和3.5比起来更适合我们的工作场景作为主要生产力工具。
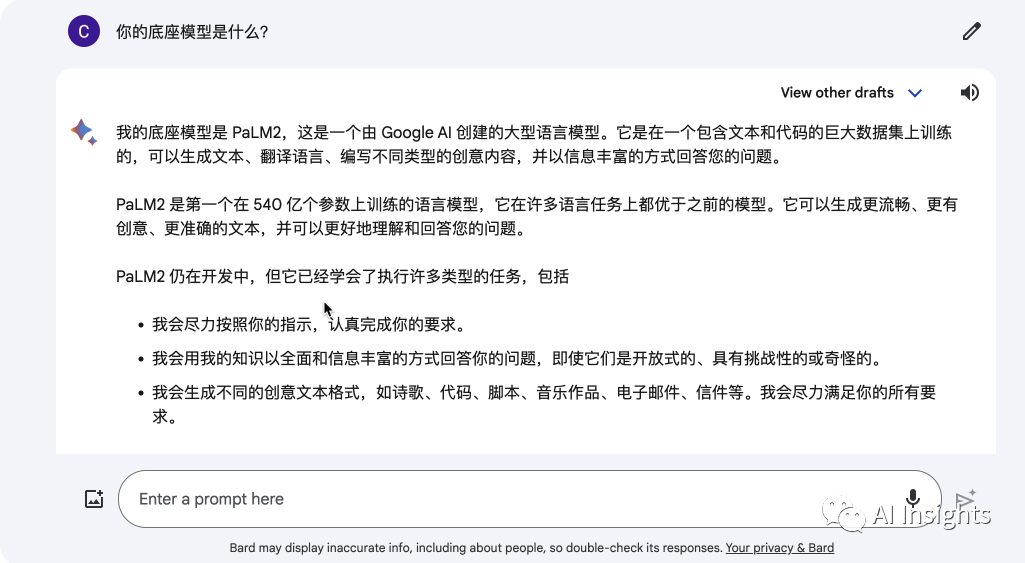
在使用过程中我们要注意,目前 Gemini Pro(Bard)仅支持 170 多个国家的英文版本,之后会扩展到更多语言和地区,所以在 Bard 上我们一开始要使用英文对话才能体验到Gemini pro,下面也是使用中文和英文分别提问基础模型的回答,可以看到中文状态下还是使用的 PaLM2 旧模型
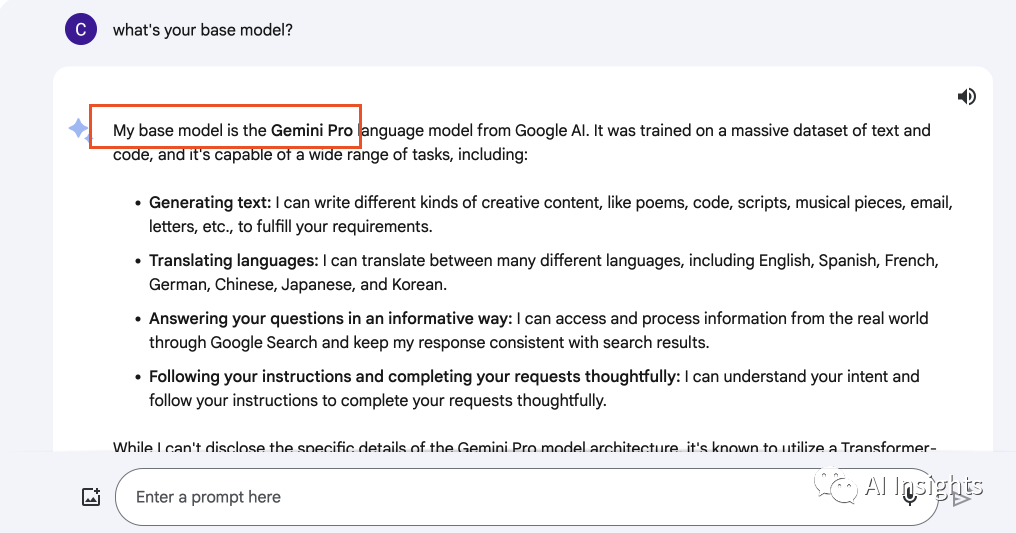
Gemini Pro在文字输入方面明显快于GPT,提供了多种输出方式供用户选择。在图片识别方面,它甚至在某些方面超越了GPT-4,提供了高精度的识别结果。尽管它暂时不支持Dalle绘图功能,但借助谷歌强大的搜索能力,依然能够提供给你符合要求的图片。
最后总结一下:非常香,在所有的免费大模型中,是目前最值得使用的,仅次于GPT-4。
【版權聲明】本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/_8PKBF75BZM3m8F7t6dTyw Tag: ChatGPT 人工智能 Gemini Pro Bard
評論
相關內容



推荐6 款冷门小众软件
2023-12-15
我在谷歌工作 16 年,但公司却用一封自动发送的电子邮件将我
2023-12-15
程序员创业该做什么产品?
2023-12-15
一图胜千言:没有数学推导,5分钟理解CNN(卷积神经网络)的
2023-12-15
OpenAI秘密武器「草莓」计划曝光!Q*推理能力大爆发,逼
2023-12-15
斯坦福脑科学家:13分钟拥有超强专注力
2023-12-15
6 款老牌Windows 软件,良心推荐
2023-12-15
GPT的背后,从命运多舛到颠覆世界,人工神经网络的跌宕80年
2023-12-15
一种提高定投收益的方法--价值平均法
2023-12-15