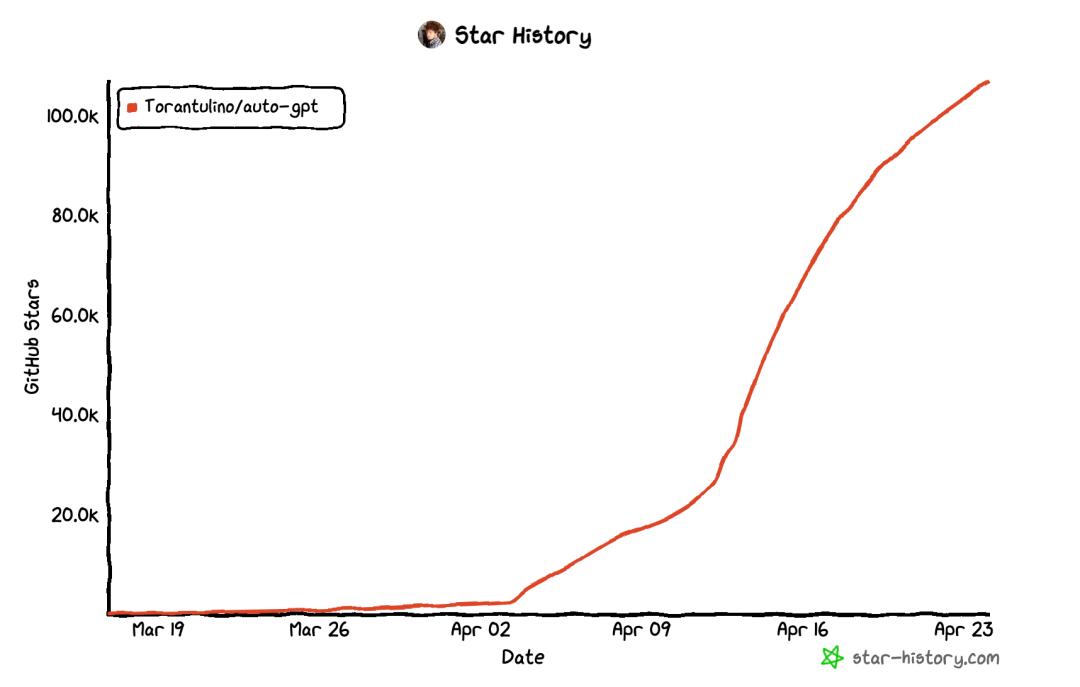
这两周,开源社区最火的项目莫过于AutoGPT了,下图是AutoGPT在GitHub上star的增长曲线,其火爆程度可见一斑。
下面这张来自知乎的图片成为了不少文章的必用插图:

喜欢钻研的同学一定会问,Auto-GPT神奇的能力来自于哪里?为什么ChatGPT只能聊天,而Auto-GPT却能自主完成不少很复杂的任务?
这篇文章就来回答这些问题,相信了解了其工作原理之后,您也能打造自己的Auto-GPT。
人类是如何解决问题的
要让AI能像人一样自主解决问题,我们就需要先看看人类在现实世界碰到问题是如何解决的,以下是来自ReAct的论文的介绍:

https://arxiv.org/pdf/2210.03629.pdf
可以看到,人类之所以具有独一无二的认知能力,其重要的原因是我们不会采取无意义的行动,人类行动的背后总是有其支撑原因,在行动之间总有一个逻辑链条。反过来,人类通过行动获取外部世界的信息,而这些信息又可以让我们形成更完善的逻辑链条,进而调整后继的行动。
就像炒菜的过程,我们需要把锅热起来是因为切菜这些准备工作都已经完成了;炒菜时因为发现没有盐了,所以要用酱油来替代;反过来,在网上搜索和面的方法,得到信息可以指导我们后继和面的动作;看菜谱和看冰箱里有什么食材,得到信息可以指导我们后继的做菜。
这种[原因/想法 -> 行动 -> 反馈]->[原因/想法 -> 行动 -> 反馈]的循环是人类能处理复杂问题的关键,虽然我们可能认为这没什么特别之处,但这只是因为我们对此已经习以为常了而已,一个AI程序并不天然具备这种能力。
那么这些形而上的讨论具体应该如何落到实处呢?
ReAct具体长什么样?
ReAct是Reason + Act的组合简写,让我们对比一下ReAct和其它一些驱动LLM(如ChatGPT)工作的方法,下图依然来自ReAct论文:

为了方便对比效果,论文把具体的Prompt放到了附录,这里只是展示了模型的输出,并标注了需要注意的部分,可以看到:
在标准的零提示的情况下(1a),模型给出了错误答案 在CoT(Chain of Thought)的情况下(1b),模型给出了推理过程,但答案依然是错误的,这也反映了只通过CoT推理找答案,不通过行动从外部获取信息的弊端,AI在这种情况下能做得最好推理就是其在预训练时学习的知识,当其不具备相关知识的时候,它就会开始瞎编(下文有具体数据) 在只采取行动不推理找原因的情况下(1c),模型只是进行了一些徒劳的搜索,然后给出了一个莫名其妙的答案"yes" 而在既分析原因也通过行动获取外部信息的情况下(1d),可以看到模型的表现非常像人类处理未知问题时的表现,先通过推理确定自己需要采取什么行动,采取行动获取信息后,又进一步推理下一步的动作,在这种工作方式下,模型给出了正确的结果
如何在代码中实现ReAct
上面的介绍虽然进一步具象化了ReAct,但喜欢动手的同学肯定会关心如何用代码具体实现ReAct,这里我们有两个选择。
如果想从头端到端地实现整个过程,你可以参考论文提供的Prompt,以及用到的WikiAPI,这样你可以完整地复现论文中的的例子。
如果你更关心如何在实际应用中使用这个技术,那么可以参考LangChain提供的例子,下面的代码来自LangChain官网(https://python.langchain.com/en/latest/modules/agents/getting_started.html):
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
可以看到代码很简单,具体的Prompt已经由LangChang封装好了,这里需要回答的问题是看看Leo DiCaprio(小李子)的女朋友是谁?她年龄的0.43次方是多少?为了回答这个问题,ChatGPT需要和外部世界交互,所以程序里提供了一个工具"serpapi",这是一个Google搜索的API包装,而为了进行年龄的0.43次方这种复杂数学计算,程序还提供了一个工具"llm-math",这些工具LangChain都已经事先实现好了,我们直接调用即可。
让我们看看模型的具体表现:
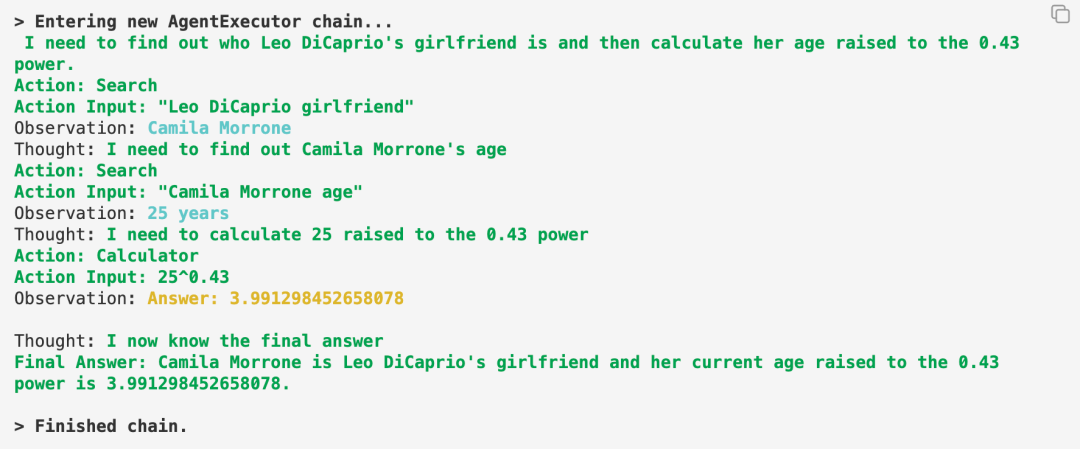
可以看到模型遵循了上面ReAct介绍的工作过程,通过一个Thought->Action->Observation的循环,模型展现出了人类一样边思考、边行动逐步解决问题的过程。
如果在实际的业务场景里,你想对上述工作过程进行更精确的控制,那么你就需要在Prompt上做工作了,下图是来自LangChain源码中的Prompt,你可以以其为参考定制自己的Prompt.

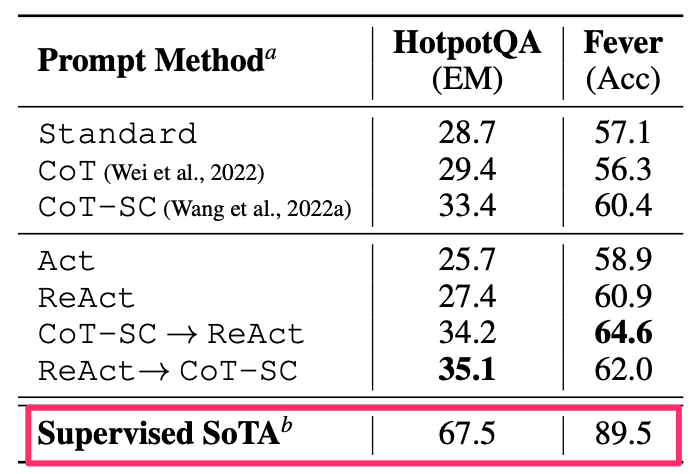
这里使用的测试数据集是HotpotQA和Fever,前者偏复杂的、需要大量信息才能回答的问题,后者偏重事实性的问题回答。
图中的Standard就是标准的0提示的方式,而CoT-SC就是CoT + Self-Consistency(自洽,我在《释放ChatGPT的真正潜力:Prompt技巧进阶指南》中有介绍),CoT-SC -> ReAct就是先用CoT-SC技术找答案,如果没找到答案就再用ReAct找答案,而反过来就是ReAct -> CoT-SC。
可以看到,单独使用ReAct,其得分比单独用Act或者CoT都好,而效果最好的是把CoT-SC和ReAct技术组合起来。
而在另外两个偏决策型的测试数据集上,ReAct的表现如下:
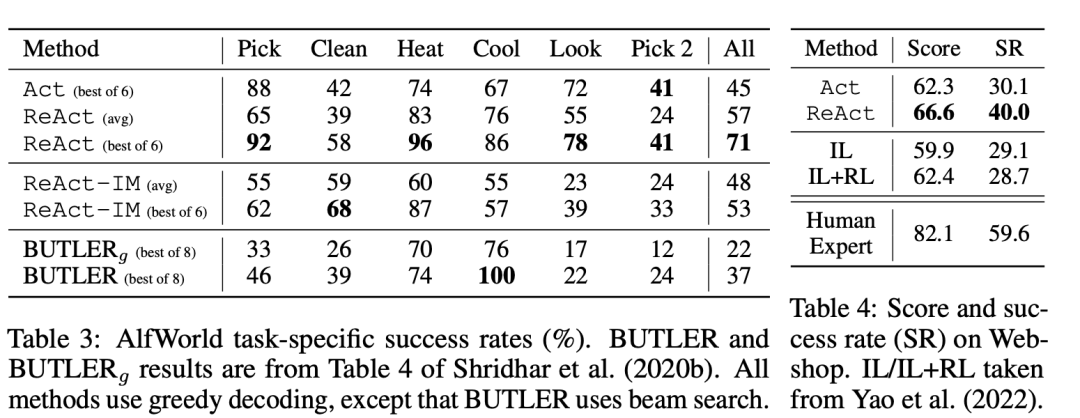
其中AlfWorld是一个文字型的游戏,模型需要在其中完成Table 3中的6类任务,而Table 4则是模型在一个大型购物网站上完成特定购物任务的表现。可以看到ReAct的表现都要比其它方法好。
但坦白说,当我看到这些测试数据的时候,我是有些失望的,毕竟我们从表中能看到ReAct的得分并不高,尤其是其在HotpotQA数据集上的得分只有30多分,作者也进一步做了一些分析:

可以看到:
在模型回答正确的问题里,有6%的相当于是蒙对的,因为其给出的原因是瞎编的 在其回答错误的问题中,有23%是因为搜索结果里本来就没答案,这种错误我们可以通过提高数据质量来避免 有29%是虽然给出的答案和标准答案不100%匹配,但答案本身是正确的,这是可以接受的 值得注意的是,在回答错误的问题中,没有一例有编瞎话的情况,对比一下CoT则有56%的瞎编的情况,这是ReAct一个非常突出的亮点
结合论文作者的分析,如果我们提高数据质量,不要求100%精准匹配标准答案,ReAct的表现要比评测分数更好一些,但即使如此,ReAct整体的得分也并不算非常高。
Auto-GPT的实际表现如何
在看到ReAct的评测分数后,我专门搜了一下AutoGPT在实际工作中的表现,可以看到在很多人惊叹其优异表现的同时也有不少吐槽:

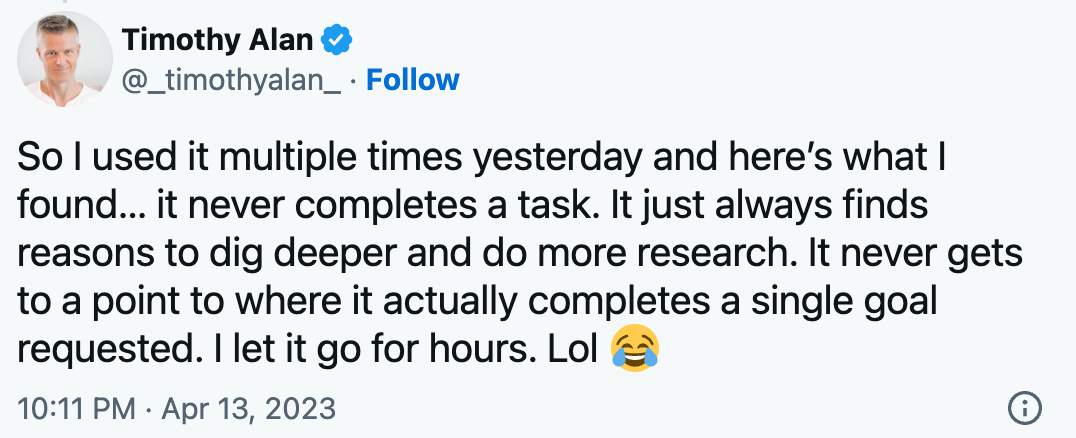
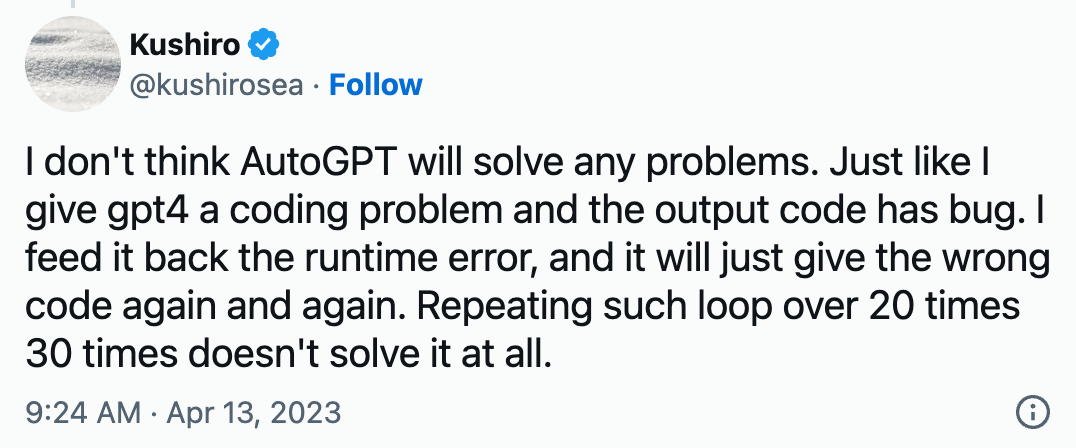
关于AutoGPT更多的槽点请参考:https://jina.ai/news/auto-gpt-unmasked-hype-hard-truths-production-pitfalls/
可以看到,AutoGPT的表现和ReAct的评测结果一致,在很多情况下AutoGPT可以按预期工作,但也有不少情况,AutoGPT并不能完成任务。那么我们应该怎么办?
首先我们还是需要具体情况具体分析,既不迷信也不完全否定ReAct技术,测试数据集实际上是比较复杂的,而我们的实际问题很多时候则相对简单,或者是可以分解为一些相对简单的问题,在这种情况下ReAct还是大有可为的,毕竟得分不如ReAct的CoT都已经解决了很多问题。
其次,如果我们的应用场景确实对模型的稳定性要求较高,但又不是必须全自动的话,我们也可以通过产品设计,在关键环节引入一些人工干预,就像我之前通过ChatGPT自动创建日历项中,偶尔ChatGPT也会不按要求输出,我就增加了一个环节,让ChatGPT真正调用脚本创建日历项前和我最后确认。
除了通过Prompt实现ReAct外,还有没有其它实现方式
ReAct的论文,以及LangChain都是通过Prompt来引导模型按照ReAct的方式进行工作的,这种实现方式虽然简单,但却导致模型的表现不够稳定,有没有非Prompt的办法来让模型按ReAct的方式工作呢?
前文介绍了ReAct在大数据集上的评测结果,细心的同学可能已经发现,Supervised SoTA得分远高于ReAct,这又是何方神圣呢?
这是一种叫做AISO(Adaptive Information-Seeking Strategy for Open-Domain Question Answering)的实现技术,它是由来自咱们中国的研究机构和大学提出(论文地址:https://arxiv.org/pdf/2109.06747.pdf),其工作示意图如下:
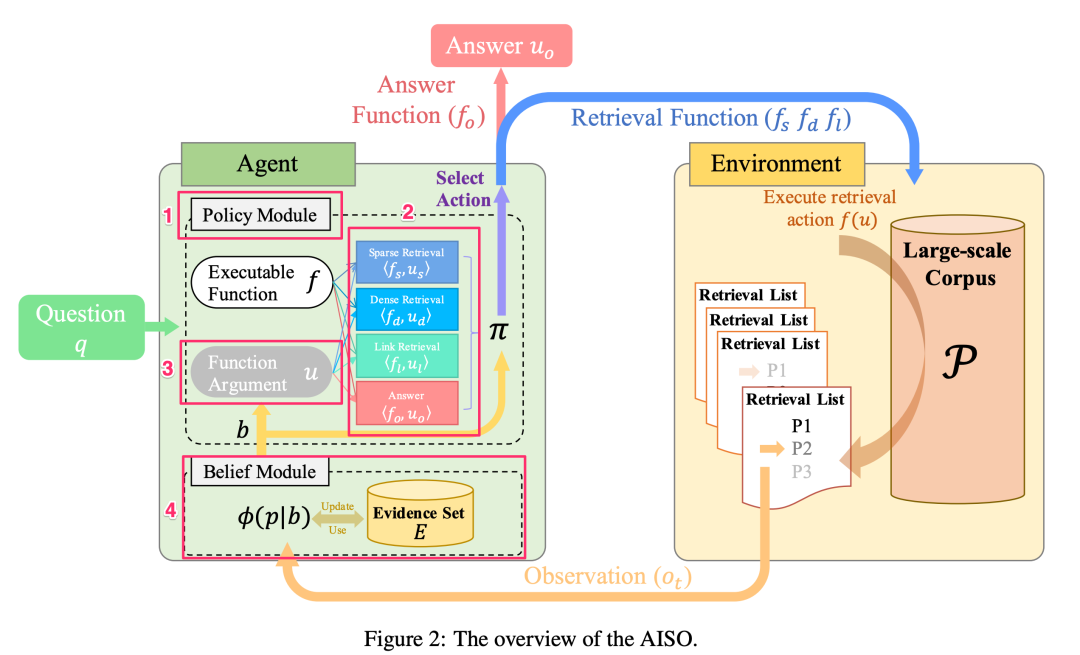
其中的1, Policy Module承担了ReAct中的推理部分,它来决定接下来需要采取什么Action。
其中的2, Function则是具体的Action,这些Action要么从环境中查询和问题相关的信息,要么返回问题的答案。
其中的3, Function Argument则负责为具体的Action提供相应的参数。
其中的4, Evidence Set则类似于ChatGPT中的上下文,负责过滤Action查询返回的信息,只有对回答问题有帮助的信息会被保存下来。
AISO和Prompt驱动的ReAct最大的不同是,图中的Policy模块、Function Argument模块、以及Evidence Set模块都需要通过大量数据训练得到,可以简单把AISO看作是一种通过Fine Tuning实现ReAct的方式。
就如同在很多情况下,Fine Tuning的效果要比单纯优化Prompt效果好一样,在ReAct的实现上,AISO的得分也要更高,但其代价则是复杂性和训练成本。
最后总结一下,人类面对复杂问题时,总是原因和行动相互交替,逐步解决问题,ReAct通过类似的工作过程,在解决复杂问题上也取得了不错的表现,AutoGPT就是其中的代表,LangChain也提供了相应的API,然而像AutoGPT这样通过Prompt来引导模型按照ReAct的方式工作有时表现不稳定,这可以通过产品设计或者简化问题的方式来适当规避,如果我们的业务对稳定性要求非常高,那么也可以通过AISO来实现ReAct,其表现更为稳定,但也更为复杂,并需要一定的训练成本和大量的训练数据。
【版權聲明】
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/fzrMUv_sTSC-nLYngtjbPQ Tag: ChatGPT 人工智能 AI原理
