Deleon
2023-04-23
365
0
0
0
0
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/17UIqbi2W4dLgzPycbEPMA Tag: 人工智能 Moss
網站名稱:160亿参数,新增多项能力,复旦MOSS开源了
網站地址:https://mp.weixin.qq.com/s/17UIqbi2W4dLgzPycbEPMA
今年2月份,机器之心报道了复旦大学推出中国版ChatGPT的消息(参见《复旦发布中国版ChatGPT:MOSS开启测试冲上热搜,服务器挤爆》),引起了广泛关注。当时,邱锡鹏教授就…
[SEO信息] [Alexa信息]
-->>直達網站
今年 2 月份,机器之心报道了复旦大学推出中国版 ChatGPT 的消息(参见《复旦发布中国版 ChatGPT:MOSS 开启测试冲上热搜,服务器挤爆》),引起了广泛关注。当时,邱锡鹏教授就曾表示将于四月份开源 Moss。
昨天,开源版的 Moss 真的来了。

项目地址:https://github.com/OpenLMLab/MOSS
MOSS 是一个支持中英双语和多种插件的开源对话语言模型,但参数数量比 ChatGPT 少得多。在 v0.0.2 之后,团队持续对其进行调整,推出了 MOSS v0.0.3,也就是目前开源的版本。相比于早期版本,功能也实现了多项更新。
最初的测试中,MOSS 的基础功能与 ChatGPT 类似,可以按照用户输入的指令完成各类自然语言处理任务,包括文本生成、文本摘要、翻译、代码生成、闲聊等等。
开放内测后,团队继续加大中文语料的预训练:「截止目前,MOSS 003 的基座语言模型已经在 100B 中文 token 上进行了训练,总训练 token 数量达到 700B,其中还包含约 300B 代码。」
在开放内测后,我们也收集了一些用户数据,我们发现真实中文世界的用户意图和 OpenAI InstructGPT 论文中披露的 user prompt 分布有较大差异(这不仅与用户来自的国家差异有关,也跟产品上线时间有关,早期产品采集的数据中存在大量对抗性和测试性输入),于是我们以这部分真实数据作为 seed 重新生成了约 110 万常规对话数据,涵盖更细粒度的 helpfulness 数据和更广泛的 harmlessness 数据。
内容来源:https://www.zhihu.com/question/596908242/answer/2994534005
目前,团队已将 moss-moon-003-base、moss-moon-003-sft、moss-moon-003-sft-plugin 三个模型上传到 HuggingFace。后续,还有三个模型将会开源。

根据项目主页介绍,moss-moon 系列模型具有 160 亿参数,在 FP16 精度下可在单张 A100/A800 或两张 3090 显卡运行,在 INT4/8 精度下可在单张 3090 显卡运行。
团队同时表示,由于模型参数量较小和自回归生成范式,MOSS 仍然可能生成包含事实性错误的误导性回复或包含偏见 / 歧视的有害内容,请谨慎鉴别和使用 MOSS 生成的内容,请勿将 MOSS 生成的有害内容传播至互联网。
新增能力
在 MOSS v0.0.3 中,团队加入了多项新能力。
团队构造了约 30 万插件增强的对话数据,包含搜索引擎、文生图、计算器、方程求解等。关于插件版 MOSS 如何使用,后续团队将在 GitHub 公布。

MOSS v0.0.3 现已引入使用多种插件的能力。
下图展示了调用搜索引擎的能力:

下图展示了调用方程求解器的能力:

下图展示了从文本生成图片的能力:
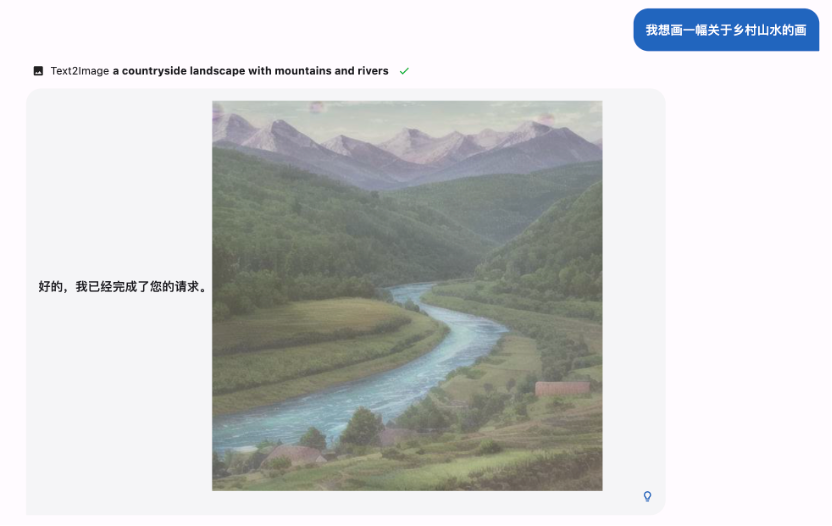
项目作者孙天祥补充说,MOSS 003 支持启用插件的能力是通过 meta instruction 来控制,类似 gpt-3.5-turbo 里的 system prompt。「因为是模型控制的,所以并不能保证 100% 控制率,以及还存在一些多选插件时调用不准、插件互相打架的缺陷,我们正在尽快开发新的模型来缓解这些问题。」
下载安装
下载本仓库内容至本地 / 远程服务器:
git clone https://github.com/OpenLMLab/MOSS.gitcd MOSS创建 conda 环境:
conda create --name moss python=3.8conda activate moss安装依赖:
pip install -r requirements.txt其中 torch 和 transformers 版本不建议低于推荐版本。
根据协议,开源的 MOSS 可用于商业用途:
此外,开发者也可通过 API 调用 MOSS 服务,团队将根据当前服务压力考虑通过 API 接口形式提供服务,接口格式可参考:https://github.com/OpenLMLab/MOSS/blob/main/moss_api.pdf
目前,已有开发者根据开源内容进行而创,比如通过 VideoChat 进行视频问答。
VideoChat 是一款多功能视频问答工具,结合了动作识别、视觉字幕和 StableLM 的功能。该工具可为视频中的任何对象和动作生成密集的描述性字幕,提供一系列语言风格以满足不同的用户偏好。它支持用户进行不同长度、情绪、语言真实性的对话。
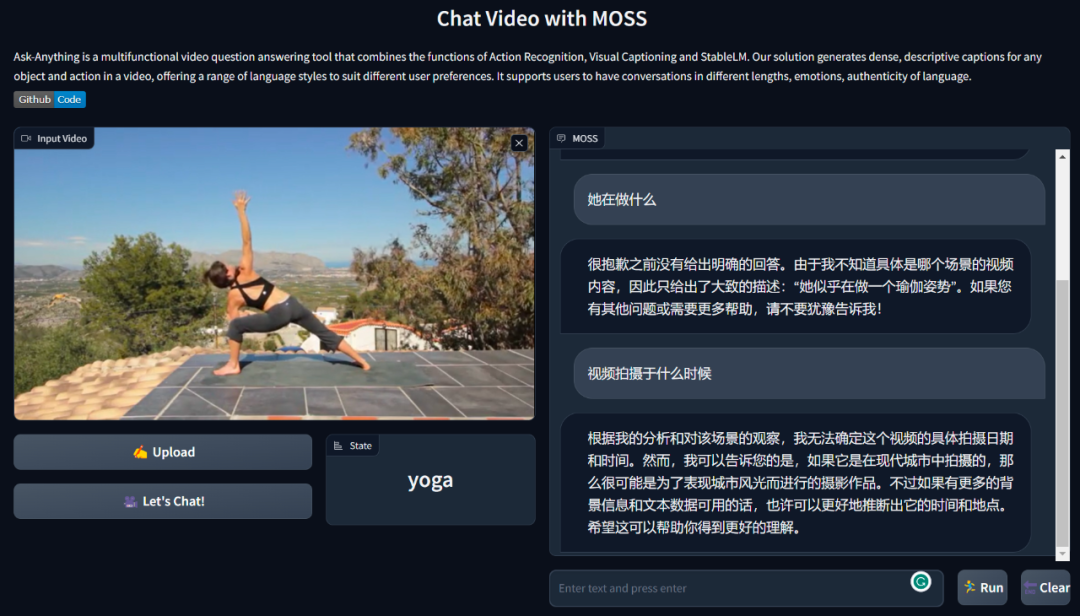
项目地址:https://github.com/OpenGVLab/Ask-Anything/tree/main/video_chat_with_MOSS
机器之心报道
编辑:蛋酱
本文爲轉帖,原文鏈接如下,如有侵權,請聯繫我們,我們會及時刪除
原文鏈接:https://mp.weixin.qq.com/s/17UIqbi2W4dLgzPycbEPMA Tag: 人工智能 Moss
評論
相關內容





字节放出地表最强ChatBot,免费使用GPT4,请低调使用
2023-04-23
为什么都放弃了LangChain?
2023-04-23
ChatGPT数据隐私解密
2023-04-23
炸裂!AI界新霸主诞生,Claude 3横扫全场,高喊“别杀
2023-04-23
斯坦福脑科学家:13分钟拥有超强专注力
2023-04-23
5月分享几个adsesne网站案例
2023-04-23
谷歌宣布推出机器人Bard,附最新Bard申请教程
2023-04-23
去年是2022年,那么138亿年前是哪一年?
2023-04-23